
Hive基本原理
Hive是建立在Hadoop上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。Hive定义了简单的类SQL查询语言,称为HQL,它允许熟悉SQL的用户查询数据。Hive的数据计算依赖于MapReduce、Spark、Tez。
使用新的执行引擎Tez代替原先的MapReduce,性能有了显著提升。Tez可以将多个有依赖的作业转换为一个作业(这样只需写一次HDFS,且中间节点较少),从而大大提升DAG作业的性能。
Hive主要特点如下:
- 海量结构化数据分析汇总。
- 将复杂的MapReduce编写任务简化为SQL语句。
- 灵活的数据存储格式,支持JSON,CSV,TEXTFILE,RCFILE,SEQUENCEFILE,ORC(Optimized Row Columnar)这几种存储格式。
Hive体系结构:
- 用户接口:用户接口主要有CLI,Client和WebUI。其中最常用的是CLI,CLI启动的时候,会同时启动一个Hive副本。Client是Hive的客户端,用户连接至Hive Server。在启动Client模式的时候,需要指出Hive Server所在节点,并且在该节点启动Hive Server。WebUI是通过浏览器访问Hive。MRS仅支持Client方式访问Hive,使用操作请参考快速使用Hive进行数据分析,应用开发请参考Hive应用开发简介。
- 元数据存储:Hive将元数据存储在数据库中,如MySQL、Derby。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
更多关于Hive组件操作指导,请参考使用Hive。
Hive结构
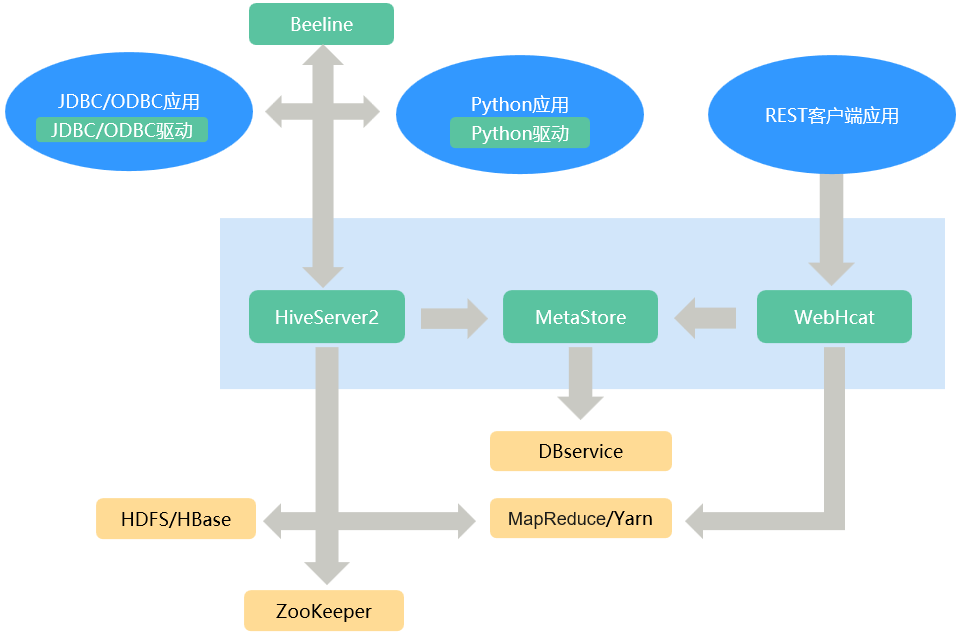
Hive为单实例的服务进程,提供服务的原理是将HQL编译解析成相应的MapReduce或者HDFS任务,图1为Hive的结构概图。
|
名称 |
说明 |
|---|---|
|
HiveServer |
一个集群内可部署多个HiveServer,负荷分担。对外提供Hive数据库服务,将用户提交的HQL语句进行编译,解析成对应的Yarn任务或者HDFS操作,从而完成数据的提取、转换、分析。 |
|
MetaStore |
|
|
WebHCat |
一个集群内可部署多个WebHCat,负荷分担。提供Rest接口,通过Rest执行Hive命令,提交MapReduce任务。 |
|
Hive客户端 |
包括人机交互命令行Beeline、提供给JDBC应用的JDBC驱动、提供给Python应用的Python驱动、提供给MapReduce的HCatalog相关JAR包。 |
|
ZooKeeper集群 |
ZooKeeper作为临时节点记录各HiveServer实例的IP地址列表,客户端驱动连接ZooKeeper获取该列表,并根据路由机制选取对应的HiveServer实例。 |
|
HDFS/HBase集群 |
Hive表数据存储在HDFS集群中。 |
|
MapReduce/Yarn集群 |
提供分布式计算服务:Hive的大部分数据操作依赖MapReduce/Yarn集群,HiveServer的主要功能是将HQL语句转换成分布式计算任务,从而完成对海量数据的处理。 |
HCatalog建立在Hive Metastore之上,具有Hive的DDL能力。从另外一种意义上说,HCatalog还是Hadoop的表和存储管理层,它使用户能够通过使用不同的数据处理工具(比如MapReduce),更轻松地在网格上读写HDFS上的数据,HCatalog还能为这些数据处理工具提供读写接口,并使用Hive的命令行接口发布数据定义和元数据探索命令。此外,经过封装这些命令,WebHCat Server还对外提供了RESTful接口,如图2所示。

Hive原理
Hive作为一个基于HDFS和MapReduce架构的数据仓库,其主要能力是通过对HQL(Hive Query Language)编译和解析,生成并执行相应的MapReduce任务或者HDFS操作。Hive与HQL相关信息,请参考HQL 语言手册。
图3为Hive的结构简图。
- Metastore:对表,列和Partition等的元数据进行读写及更新操作,其下层为关系型数据库。
- Driver:管理HQL执行的生命周期并贯穿Hive任务整个执行期间。
- Compiler:编译HQL并将其转化为一系列相互依赖的Map/Reduce任务。
- Optimizer:优化器,分为逻辑优化器和物理优化器,分别对HQL生成的执行计划和MapReduce任务进行优化。
- Executor:按照任务的依赖关系分别执行Map/Reduce任务。
- ThriftServer:提供thrift接口,作为JDBC的服务端,并将Hive和其他应用程序集成起来。
- Clients:包含WebUI和JDBC接口,为用户访问提供接口。





