
NUMA亲和性调度
NUMA节点是Non-Uniform Memory Access(非统一内存访问)架构中的一个基本组成单元,每个节点包含自己的处理器和本地内存,这些节点在物理上彼此独立,但通过高速互连总线连接在一起,形成一个整体系统。NUMA节点能够通过提供更快的本地内存访问来提高系统性能,但通常一个Node节点是多个NUMA节点的集合,在多个NUMA节点之间进行内存访问时会产生延迟,开发者可以通过优化任务调度和内存分配策略,来提高内存访问效率和整体性能。
在云原生环境中,对于高性能计算(HPC)、实时应用和内存密集型工作负载等需要CPU间通信频繁的场景下,跨NUMA节点访问会导致增加延迟和开销,从而降低系统性能。为此,volcano提供了NUMA亲和性调度能力,尽可能把Pod调度到需要跨NUMA节点最少的工作节点上,这种调度策略能够降低数据传输开销,优化资源利用率,从而增强系统的整体性能。
更多资料请查看社区NUMA亲和性插件指导链接:https://github.com/volcano-sh/volcano/blob/master/docs/design/numa-aware.md
前提条件
- 已创建一个CCE Standard集群,详情请参见购买Standard集群。
- 集群中已安装Volcano插件,详情请参见Volcano调度器。
Pod调度行为说明
当Pod设置了拓扑策略时,Volcano会根据Pod设置的拓扑策略预测匹配的节点列表。Pod的拓扑策略配置请参考NUMA亲和性调度使用示例。调度过程如下:
- 根据Pod设置的Volcano拓扑策略,筛选具有相同策略的节点。Volcano提供的拓扑策略与拓扑管理器相同。
- 在设置了相同策略的节点中,筛选CPU拓扑满足该策略要求的节点进行调度。
|
Pod可配置的拓扑策略 |
Pod调度时筛选节点行为说明 |
|
|---|---|---|
|
1.根据Pod设置的拓扑策略,筛选可调度的节点 |
2.筛选可调度的节点后,进一步筛选CPU拓扑满足策略的节点进行调度 |
|
|
none |
针对配置了以下几种拓扑策略的节点,调度时均无筛选行为:
|
- |
|
best-effort |
筛选拓扑策略同样为“best-effort”的节点:
|
尽可能满足策略要求进行调度: 优先调度至单NUMA节点,如果单NUMA节点无法满足CPU申请值,允许调度至多个NUMA节点。 |
|
restricted |
筛选拓扑策略同样为“restricted”的节点:
|
严格限制的调度策略:
|
|
single-numa-node |
筛选拓扑策略同样为“single-numa-node”的节点:
|
仅允许调度至单NUMA节点。 |
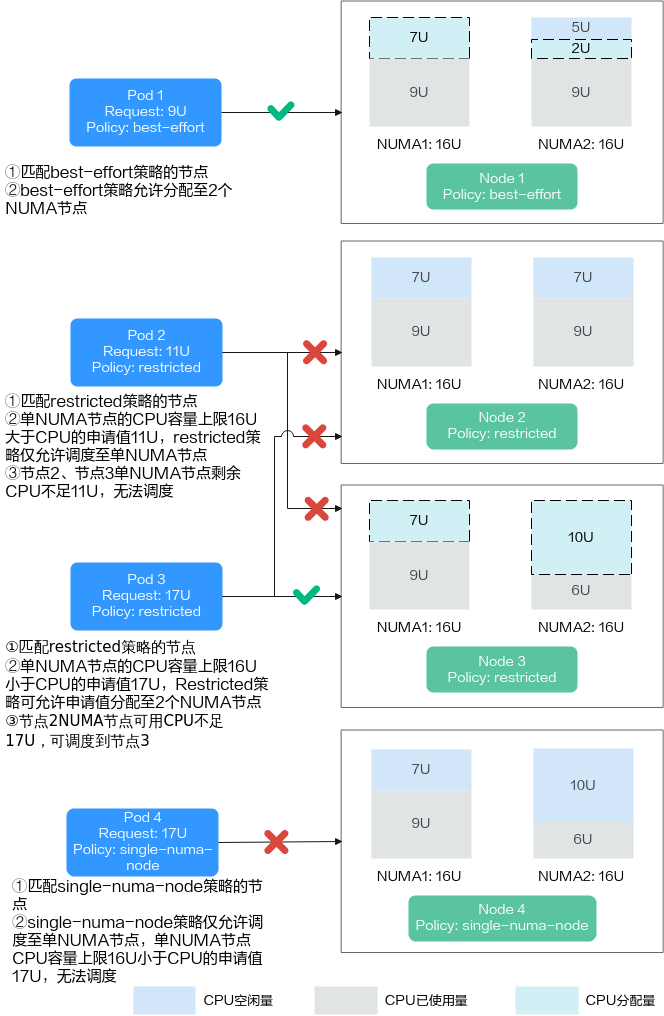
假设单个节点CPU总量为32U,由2个NUMA节点提供资源,分配如下:
|
工作节点 |
节点拓扑策略 |
NUMA节点1上的CPU总量 |
NUMA节点2上的CPU总量 |
||
|---|---|---|---|---|---|
|
CPU总量 |
CPU空闲量 |
CPU总量 |
CPU空闲量 |
||
|
节点-1 |
best-effort |
16U |
7U |
16U |
7U |
|
节点-2 |
restricted |
16U |
7U |
16U |
7U |
|
节点-3 |
restricted |
16U |
7U |
16U |
10U |
|
节点-4 |
single-numa-node |
16U |
7U |
16U |
10U |
Pod设置拓扑策略后,调度情况如图1所示。
- 当Pod的CPU申请值为9U时,设置拓扑策略为“best-effort”,Volcano会匹配拓扑策略同样为“best-effort”的节点-1,且该策略允许调度至多个NUMA节点,因此9U的申请值会被分配到2个NUMA节点,该Pod可成功调度至节点-1。
- 当Pod的CPU申请值为11U时,设置拓扑策略为“restricted”,Volcano会匹配拓扑策略同样为“restricted”的节点-2/节点-3,且单NUMA节点CPU总量满足11U的申请值,但单NUMA节点剩余可用的CPU量无法满足,因此该Pod无法调度。
- 当Pod的CPU申请值为17U时,设置拓扑策略为“restricted”,Volcano会匹配拓扑策略同样为“restricted”的节点-2/节点-3,且单NUMA节点CPU总量无法满足17U的申请值,可允许分配到2个NUMA节点,该Pod可成功调度至节点-3。
- 当Pod的CPU申请值为17U时,设置拓扑策略为“single-numa-node”,Volcano会匹配拓扑策略同样为“single-numa-node”的节点,但由于单NUMA节点CPU总量均无法满足17U的申请值,因此该Pod无法调度。
调度优先级
不管是什么拓扑策略,都是希望把Pod调度到当时最优的节点上,这里通过给每一个节点进行打分的机制来排序筛选最优节点。
原则:尽可能把Pod调度到需要跨NUMA节点最少的工作节点上。
打分公式如下:
score = weight * (100 - 100 * numaNodeNum / maxNumaNodeNum)
参数说明:
- weight:NUMA Aware Plugin的权重。
- numaNodeNum:表示工作节点上运行该Pod需要NUMA节点的个数。
- maxNumaNodeNum:表示所有工作节点中该Pod的最大NUMA节点个数。
例如,假设有三个节点满足Pod的CPU拓扑策略,且NUMA Aware Plugin的权重设为10:
- Node A:由1个NUMA节点提供Pod所需的CPU资源,即numaNodeNum=1
- Node B:由2个NUMA节点提供Pod所需的CPU资源,即numaNodeNum=2
- Node C:由4个NUMA节点提供Pod所需的CPU资源,即numaNodeNum=4
则根据以上公式,maxNumaNodeNum=4
- score(Node A) = 10 * (100 - 100 * 1 / 4) = 750
- score(Node B) = 10 * (100 - 100 * 2 / 4) = 500
- score(Node C) = 10 * (100 - 100 * 4 / 4) = 0
因此最优节点为Node A。
Volcano开启NUMA亲和性调度
- 在节点池中开启静态(static)CPU管理策略,具体请参考 为自定义节点池开启CPU管理策略。
- 登录CCE控制台,单击集群名称进入集群。
- 在左侧选择“节点管理”,在右侧选择“节点池”页签,单击节点池名称后的“更多 > 配置管理”。
- 在侧边栏滑出的“配置管理”窗口中,修改kubelet组件的CPU管理策略配置(cpu-manager-policy)参数值,选择static。
- 单击“确定”,完成配置操作。
- 在节点池中配置CPU拓扑策略。
- 登录CCE控制台,单击集群名称进入集群,在左侧选择“节点管理”,在右侧选择“节点池”页签,单击节点池名称后的“ 配置管理”。
- 将kubelet的拓扑管理策略(topology-manager-policy)的值修改为需要的CPU拓扑策略即可。
有效拓扑策略为“none”、“best-effort”、“restricted”、“single-numa-node”,具体策略对应的调度行为请参见Pod调度行为说明。
- 开启numa-aware插件功能和resource_exporter功能。
Volcano 1.7.1及以上版本
- 登录CCE控制台,单击集群名称进入集群,单击左侧导航栏的“插件中心”,在右侧找到Volcano,单击“编辑”。
- 在“扩展功能”中开启“NUMA拓扑调度”能力,单击“确定”。
Volcano 1.7.1以下版本- 登录CCE控制台,单击集群名称进入集群,单击左侧导航栏的“配置中心”,切换至“调度配置”页面,选择Volcano调度器找到对应的“专家模式”,单击“开始使用”。
- 开启resource_exporter_enable参数,用于收集节点numa拓扑信息。JSON格式的示例如下:
{ "plugins": { "eas_service": { "availability_zone_id": "", "driver_id": "", "enable": "false", "endpoint": "", "flavor_id": "", "network_type": "", "network_virtual_subnet_id": "", "pool_id": "", "project_id": "", "secret_name": "eas-service-secret" } }, "resource_exporter_enable": "true" }开启后可以查看当前节点的numa拓扑信息。kubectl get numatopo NAME AGE node-1 4h8m node-2 4h8m node-3 4h8m
- 启用Volcano numa-aware算法插件。
kubectl edit cm -n kube-system volcano-scheduler-configmap
kind: ConfigMap apiVersion: v1 metadata: name: volcano-scheduler-configmap namespace: kube-system data: default-scheduler.conf: |- actions: "allocate, backfill, preempt" tiers: - plugins: - name: priority - name: gang - name: conformance - plugins: - name: overcommit - name: drf - name: predicates - name: nodeorder - plugins: - name: cce-gpu-topology-predicate - name: cce-gpu-topology-priority - name: cce-gpu - plugins: - name: nodelocalvolume - name: nodeemptydirvolume - name: nodeCSIscheduling - name: networkresource arguments: NetworkType: vpc-router - name: numa-aware # add it to enable numa-aware plugin arguments: weight: 10 # the weight of the NUMA Aware Plugin
NUMA亲和性调度使用示例
Pod调度时可以采用的NUMA放置策略,具体策略对应的调度行为请参见Pod调度行为说明。
- single-numa-node:Pod调度时会选择拓扑管理策略已经设置为single-numa-node的节点池中的节点,且CPU需要放置在相同NUMA下,如果节点池中没有满足条件的节点,Pod将无法被调度。
- restricted:Pod调度时会选择拓扑管理策略已经设置为restricted节点池的节点,且CPU需要放置在相同的NUMA集合下,如果节点池中没有满足条件的节点,Pod将无法被调度。
- best-effort:Pod调度时会选择拓扑管理策略已经设置为best-effort节点池的节点,且尽量将CPU放置在相同NUMA下,如果没有节点满足这一条件,则选择最优节点进行放置。
- 以下为使用Volcano设置NUMA亲和性调度的示例。
- 示例一:在无状态工作负载中配置NUMA亲和性。
kind: Deployment apiVersion: apps/v1 metadata: name: numa-tset spec: replicas: 1 selector: matchLabels: app: numa-tset template: metadata: labels: app: numa-tset annotations: volcano.sh/numa-topology-policy: single-numa-node # set the topology policy spec: containers: - name: container-1 image: nginx:alpine resources: requests: cpu: 2 # 必须为整数,且需要与limits中一致 memory: 2048Mi limits: cpu: 2 # 必须为整数,且需要与requests中一致 memory: 2048Mi imagePullSecrets: - name: default-secret - 示例二:创建一个Volcano Job,并使用NUMA亲和性。
apiVersion: batch.volcano.sh/v1alpha1 kind: Job metadata: name: vj-test spec: schedulerName: volcano minAvailable: 1 tasks: - replicas: 1 name: "test" topologyPolicy: best-effort # set the topology policy for task template: spec: containers: - image: alpine command: ["/bin/sh", "-c", "sleep 1000"] imagePullPolicy: IfNotPresent name: running resources: limits: cpu: 20 memory: "100Mi" restartPolicy: OnFailure
- 示例一:在无状态工作负载中配置NUMA亲和性。
- NUMA调度分析。
假设NUMA节点情况如下:
工作节点
节点策略拓扑管理器策略
NUMA 节点 0 上的可分配 CPU
NUMA 节点 1 上的可分配 CPU
node-1
single-numa-node
16U
16U
node-2
best-effort
16U
16U
node-3
best-effort
20U
20U
则根据以上示例,
- 示例一中,Pod的CPU申请值为2U,设置拓扑策略为“single-numa-node”,因此会被调度到相同策略的node-1。
- 示例二中,Pod的CPU申请值为20U,设置拓扑策略为“best-effort”,它将被调度到node-3,因为node-3可以在单个NUMA节点上分配Pod的CPU请求,而node-2需要在两个NUMA节点上执行此操作。
确认NUMA使用情况
您可以通过lscpu命令查看当前节点的CPU概况:
# 查看当前节点的CPU概况 lscpu ... CPU(s): 32 NUMA node(s): 2 NUMA node0 CPU(s): 0-15 NUMA node1 CPU(s): 16-31
然后查看NUMA节点使用情况。
# 查看当前节点的CPU分配
cat /var/lib/kubelet/cpu_manager_state
{"policyName":"static","defaultCpuSet":"0,10-15,25-31","entries":{"777870b5-c64f-42f5-9296-688b9dc212ba":{"container-1":"16-24"},"fb15e10a-b6a5-4aaa-8fcd-76c1aa64e6fd":{"container-1":"1-9"}},"checksum":318470969}
以上示例中表示,节点上运行了两个容器,一个占用了NUMA node0的1-9核,另一个占用了NUMA node1的16-24核。
常见问题
Pod调度失败
在使用过程中,如果只开启了Volcano插件的NUMA开关,没有配置CPU管理策略,且调度器为volcano时,可能导致作业调度失败,请根据以下要点进行问题排查。
- 在使用NUMA亲和性调度前,请保证已部署Volcano插件且插件运行状态正常。
- 在使用NUMA亲和性调度时:
- 请保证节点池的“CPU管理策略配置(cpu-manager-policy)”已设置为static。
- 请保证节点池的“拓扑管理策略(topology-manager-policy)”已设置正确。
- 请保证为Pod设置正确的拓扑策略,来筛选节点池中已配置了相同拓扑策略的节点,具体设置参考NUMA亲和性调度使用示例。
- 请保证应用Pod使用的是Volcano调度器,具体配置可参考使用Volcano调度工作负载;Pod中的所有容器的CPU Request必须为整数(单位:Core),且Request与Limit相同。




