
更新时间:2025-01-22 GMT+08:00
自定义函数
概述
DLI支持三种自定义函数:
- UDF:自定义函数,支持一个或多个输入参数,返回一个结果值。
- UDTF:自定义表值函数,支持一个或多个输入参数,可返回多行多列。
- UDAF:自定义聚合函数,将多条记录聚合成一个值。
POM依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table_2.11</artifactId>
<version>1.7.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.7.2</version>
<scope>provided</scope>
</dependency>
注意事项
- 暂不支持通过python写UDF、UDTF、UDAF自定义函数。
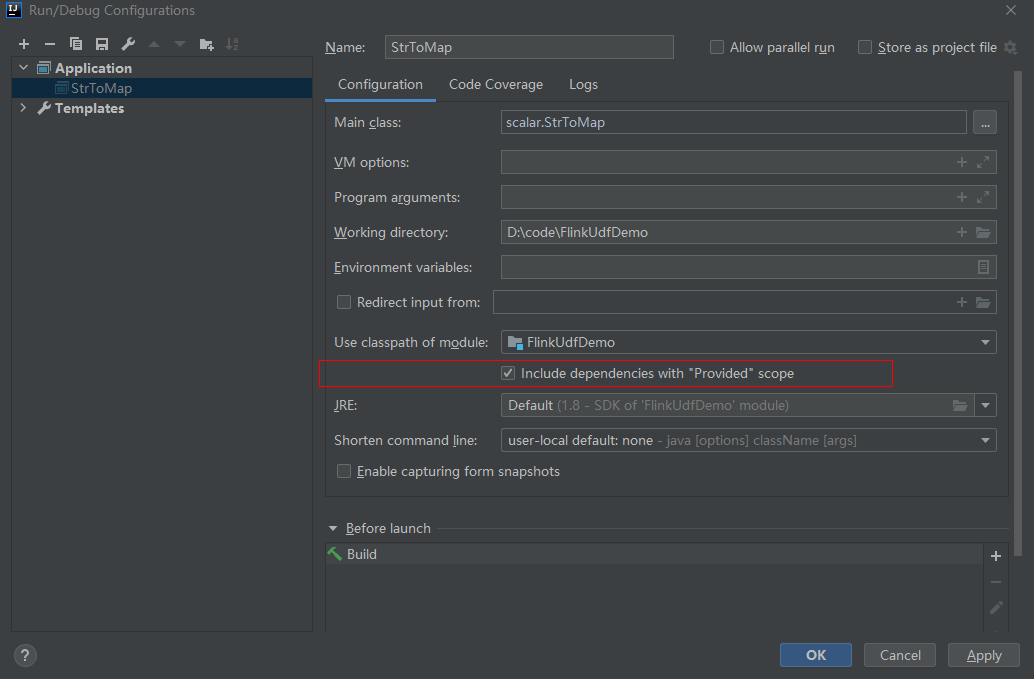
- 如果使用IntelliJ IDEA工具对创建的自定义函数进行调试,则需要在IDEA上勾选:include dependencies with "Provided" scope,否则本地调试运行时会加载不到pom文件中的依赖包。

使用方式

编写代码示例
import org.apache.flink.table.functions.FunctionContext;
import org.apache.flink.table.functions.ScalarFunction;
public class UdfScalarFunction extends ScalarFunction {
private int factor = 12;
public UdfScalarFunction() {
this.factor = 12;
}
/**
* 初始化操作,可选
* @param context
*/
@Override
public void open(FunctionContext context) {}
/**
* 自定义逻辑
* @param s
* @return
*/
public int eval(String s) {
return s.hashCode() * factor;
}
/**
* 可选
*/
@Override
public void close() {}
}
使用示例
1 2 |
CREATE FUNCTION udf_test AS 'com.xxx.udf.UdfScalarFunction'; INSERT INTO sink_stream select udf_test(attr) FROM source_stream; |
UDTF
UDTF函数需继承TableFunction函数,并实现eval方法。open函数及close函数可选。如果需要UDTF返回多列,只需要将返回值声明成Tuple或Row即可。若使用Row,需要重载getResultType声明返回的字段类型。
编写代码示例
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.table.functions.FunctionContext;
import org.apache.flink.table.functions.TableFunction;
import org.apache.flink.types.Row;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class UdfTableFunction extends TableFunction<Row> {
private Logger log = LoggerFactory.getLogger(TableFunction.class);
/**
* 初始化操作,可选
* @param context
*/
@Override
public void open(FunctionContext context) {}
public void eval(String str, String split) {
for (String s : str.split(split)) {
Row row = new Row(2);
row.setField(0, s);
row.setField(1, s.length());
collect(row);
}
}
/**
* 函数返回类型声明
* @return
*/
@Override
public TypeInformation<Row> getResultType() {
return Types.ROW(Types.STRING, Types.INT);
}
/**
* 可选
*/
@Override
public void close() {}
}
使用示例
UDTF支持CROSS JOIN和LEFT JOIN,在使用UDTF时需要带上 LATERAL 和TABLE 两个关键字。
- CROSS JOIN:对于左表的每一行数据,假设UDTF不产生输出,则这一行不进行输出。
- LEFT JOIN:对于左表的每一行数据,假设UDTF不产生输出,这一行仍会输出,UDTF相关字段用null填充。
1 2 3 4 5 6 7 |
CREATE FUNCTION udtf_test AS 'com.xxx.udf.TableFunction'; // CROSS JOIN INSERT INTO sink_stream select subValue, length FROM source_stream, LATERAL TABLE(udtf_test(attr, ',')) as T(subValue, length); // LEFT JOIN INSERT INTO sink_stream select subValue, length FROM source_stream LEFT JOIN LATERAL TABLE(udtf_test(attr, ',')) as T(subValue, length) ON TRUE; |
编写代码示例
public class WeightedAvgAccum {
public long sum = 0;
public int count = 0;
}
import org.apache.flink.table.functions.AggregateFunction;
import java.util.Iterator;
/**
* 第一个类型变量为聚合函数返回的类型,第二个类型变量为Accumulator类型
* Weighted Average user-defined aggregate function.
*/
public class UdfAggFunction extends AggregateFunction<Long, WeightedAvgAccum> {
// 初始化Accumulator
@Override
public WeightedAvgAccum createAccumulator() {
return new WeightedAvgAccum();
}
// 返回Accumulator存储的中间计算值
@Override
public Long getValue(WeightedAvgAccum acc) {
if (acc.count == 0) {
return null;
} else {
return acc.sum / acc.count;
}
}
// 根据输入更新中间计算值
public void accumulate(WeightedAvgAccum acc, long iValue) {
acc.sum += iValue;
acc.count += 1;
}
// Restract撤回操作,和accumulate操作相反
public void retract(WeightedAvgAccum acc, long iValue) {
acc.sum -= iValue;
acc.count -= 1;
}
// 合并多个accumulator值
public void merge(WeightedAvgAccum acc, Iterable<WeightedAvgAccum> it) {
Iterator<WeightedAvgAccum> iter = it.iterator();
while (iter.hasNext()) {
WeightedAvgAccum a = iter.next();
acc.count += a.count;
acc.sum += a.sum;
}
}
// 重置中间计算值
public void resetAccumulator(WeightedAvgAccum acc) {
acc.count = 0;
acc.sum = 0L;
}
}
使用示例
1 2 |
CREATE FUNCTION udaf_test AS 'com.xxx.udf.UdfAggFunction'; INSERT INTO sink_stream SELECT udaf_test(attr2) FROM source_stream GROUP BY attr1; |
父主题: Flink SQL语法参考




