
更新时间:2025-10-28 GMT+08:00
ClickHouse数据入库最佳实践
最佳实践方案
ClickHouse数据加工流程最佳实践:在数据湖中通过Hive&Spark(批量)/FlinkSQL(增量)加工成大宽表后,通过JDBC将数据批量写入ClickHouse中,下游BI工具和应用进行实时OLAP分析。
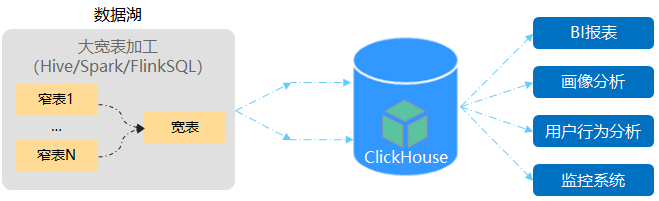
数据加工
建议使用Hive/Spark进行数据批量加工,FlinkSQL进行数据增量加工。
数据入库
通过Spark/Flink的JDBC进行数据同步,也可选择HDFS外表(ClickHouse集群只支持X86平台)用户自己写调度程序进行数据导入。
父主题: ClickHouse数据库开发




