
文档首页/
数据仓库服务 GaussDB(DWS)/
开发指南/
标准数仓开发指南(8.3.0.x)/
GaussDB(DWS)存储过程/
GaussDB(DWS)存储过程数组和record/
record
更新时间:2024-10-10 GMT+08:00
record
record类型的变量
创建一个record变量的方式:
定义一个record类型 ,然后使用该类型来声明一个变量。
语法
record类型的语法参见图1。
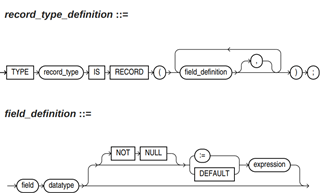
对以上语法格式的解释如下:
- record_type:声明的类型名称。
- field:record类型中的成员名称。
- datatype:record类型中成员的类型。
- expression:设置默认值的表达式。

在GaussDB(DWS)中:
- record类型的变量的赋值支持,
- 在函数或存储过程的声明阶段,声明一个record类型,并且可以在该类型中定义成员变量。
- 一个record变量到另一个record变量的赋值。
- SELECT INTO和FETCH向一个record类型的变量中赋值。
- 将一个NULL值赋值给一个record变量。
- 不支持INSERT和UPDATE语句使用record变量进行插入数据和更新数据。
- 如果成员有复合类型,在声明阶段不支持指定默认值,该行为同声明阶段的变量一样。
示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 |
下面存储过程中用到的表定义如下: CREATE TABLE emp_rec ( empno numeric(4,0), ename character varying(10), job character varying(9), mgr numeric(4,0), hiredate timestamp(0) without time zone, sal numeric(7,2), comm numeric(7,2), deptno numeric(2,0) ) with (orientation = column,compression=middle) distribute by hash (sal); \d emp_rec Table "public.emp_rec" Column | Type | Modifiers ----------+--------------------------------+----------- empno | numeric(4,0) | not null ename | character varying(10) | job | character varying(9) | mgr | numeric(4,0) | hiredate | timestamp(0) without time zone | sal | numeric(7,2) | comm | numeric(7,2) | deptno | numeric(2,0) | --演示在存储过程中对数组进行操作。 CREATE OR REPLACE FUNCTION regress_record(p_w VARCHAR2) RETURNS VARCHAR2 AS $$ DECLARE --声明一个record类型. type rec_type is record (name varchar2(100), epno int); employer rec_type; --使用%type声明record类型 type rec_type1 is record (name emp_rec.ename%type, epno int not null :=10); employer1 rec_type1; --声明带有默认值的record类型 type rec_type2 is record ( name varchar2 not null := 'SCOTT', epno int not null :=10); employer2 rec_type2; CURSOR C1 IS select ename,empno from emp_rec order by 1 limit 1; BEGIN --对一个record类型的变量的成员赋值。 employer.name := 'WARD'; employer.epno = 18; raise info 'employer name: % , epno:%', employer.name, employer.epno; --将一个record类型的变量赋值给另一个变量。 employer1 := employer; raise info 'employer1 name: % , epno: %',employer1.name, employer1.epno; --将一个record类型变量赋值为NULL。 employer1 := NULL; raise info 'employer1 name: % , epno: %',employer1.name, employer1.epno; --获取record变量的默认值。 raise info 'employer2 name: % ,epno: %', employer2.name, employer2.epno; --在for循环中使用record变量 for employer in select ename,empno from emp_rec order by 1 limit 1 loop raise info 'employer name: % , epno: %', employer.name, employer.epno; end loop; --在select into 中使用record变量。 select ename,empno into employer2 from emp_rec order by 1 limit 1; raise info 'employer name: % , epno: %', employer2.name, employer2.epno; --在cursor中使用record变量。 OPEN C1; FETCH C1 INTO employer2; raise info 'employer name: % , epno: %', employer2.name, employer2.epno; CLOSE C1; RETURN employer.name; END; $$ LANGUAGE plpgsql; --调用该存储过程。 CALL regress_record('abc'); INFO: employer name: WARD , epno:18 INFO: employer1 name: WARD , epno: 18 INFO: employer1 name: <NULL> , epno: <NULL> INFO: employer2 name: SCOTT ,epno: 10 --删除存储过程。 DROP PROCEDURE regress_record; |




