
使用MRS Hive表对接OBS文件系统
应用场景
MRS支持用户将数据存储在OBS服务中,使用MRS集群仅作数据计算处理的存算分离场景。
用户通过IAM服务的“委托”机制进行简单配置,即可实现OBS的访问。
方案架构
Hive是建立在Hadoop上的数据仓库框架,提供大数据平台批处理计算能力,能够对结构化/半结构化数据进行批量分析汇总完成数据计算。提供类似SQL的Hive Query Language语言操作结构化数据,其基本原理是将HQL语言自动转换成MapReduce任务,从而完成对Hadoop集群中存储的海量数据进行查询和分析。
Hive主要特点如下:
- 海量结构化数据分析汇总。
- 将复杂的MapReduce编写任务简化为SQL语句。
- 灵活的数据存储格式,支持JSON、CSV、TEXTFILE、RCFILE、SEQUENCEFILE、ORC等存储格式。
Hive作为一个基于HDFS和MapReduce架构的数据仓库,其主要能力是通过对HQL(Hive Query Language)编译和解析,生成并执行相应的MapReduce任务或者HDFS操作。

- Metastore:对表,列和Partition等的元数据进行读写及更新操作,其下层为关系型数据库。
- Driver:管理HQL执行的生命周期并贯穿Hive任务整个执行期间。
- Compiler:编译HQL并将其转化为一系列相互依赖的Map/Reduce任务。
- Optimizer:优化器,分为逻辑优化器和物理优化器,分别对HQL生成的执行计划和MapReduce任务进行优化。
- Executor:按照任务的依赖关系分别执行Map/Reduce任务。
- ThriftServer:提供thrift接口,作为JDBC的服务端,并将Hive和其他应用程序集成起来。
- Clients:包含WebUI和JDBC接口,为用户访问提供接口。
方案优势
MRS支持在大数据存储容量大、计算资源需要弹性扩展的场景下,用户将数据存储在OBS服务中,使用MRS集群仅作数据计算处理的存算分离模式,从而实现按需灵活扩展资源、低成本的海量数据分析方案。
约束与限制
大数据存算分离场景,请务必使用OBS并行文件系统,使用普通对象桶会对集群性能产生较大影响。
步骤一:创建ECS委托
- 登录华为云管理控制台。
- 在服务列表中选择“管理与监管 > 统一身份认证服务”。
- 选择“委托 > 创建委托”。
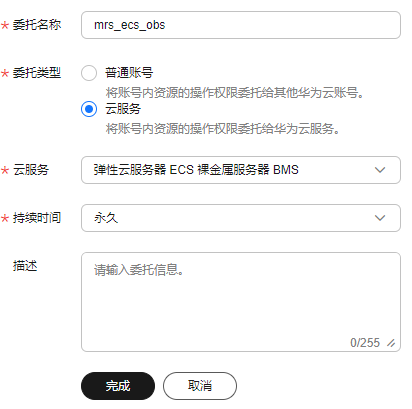
- 设置“委托名称”。例如:mrs_ecs_obs。
- “委托类型”选择“云服务”,在“云服务”中选择“弹性云服务器 ECS 裸金属服务器 BMS”,授权ECS或BMS调用OBS服务,如图2所示。
- “持续时间”选择“永久”并单击“完成”。
- 在委托的“操作”列单击“授权”,搜索“OBS OperateAccess”策略,勾选“OBS OperateAccess”策略。
- 单击“下一步”,选择权限范围方案,默认选择“所有资源”,单击“展开其他方案”,选择“全局服务资源”,单击“确定”。
- 在弹出的提示框中单击“知道了”,开始授权。界面提示“授权成功。”,单击“完成”,委托成功创建。
步骤二:为MRS集群配置委托
配置存算分离支持在新建集群中配置委托实现,也可以通过为已有集群绑定委托实现。本示例以为已有集群配置委托为例介绍。
- 登录MRS控制台,在导航栏选择“现有集群”。
- 单击集群名称,进入集群详情页面。
- 在集群详情页的“概览”页签,单击“IAM用户同步”右侧的“同步”进行IAM用户同步。
- 在集群详情页的“概览”页签,单击“委托”右侧的“选择委托”选择步骤一:创建ECS委托的委托并单击“确定”进行绑定,或单击“创建委托”进入IAM控制台进行创建后再在此处进行绑定。
图3 绑定委托

步骤四:Hive访问OBS文件系统
- 用root用户登录集群Master节点,具体请参见登录集群节点。
- 验证Hive访问OBS。
- 用root用户登录集群Master节点,执行如下命令:
source bigdata_env
source Hive/component_env
- 查看文件系统mrs-demo01下面的文件列表。
- 返回文件列表即表示访问OBS成功。
图4 查看mrs-demo01下的文件列表

- 执行以下命令进行用户认证(普通模式即未开启Kerberos认证无需执行此步骤)。
kinit hive
输入用户hive密码,默认密码为Hive@123,第一次使用需要修改密码。
- 执行Hive组件的客户端命令。
- 在beeline中直接使用OBS的目录进行访问。例如,执行如下命令创建Hive表并指定数据存储在mrs-demo01文件系统的test_demo01目录中。
create table test_demo01(name string) location "obs://mrs-demo01/test_demo01";
- 执行如下命令查询所有表,返回结果中存在表test_demo01,即表示访问OBS成功。
show tables;
图5 查看是否存在表test_demo01
- 查看表的Location。
show create table test_demo01;
查看表的Location是否为“obs://OBS桶名/”开头。
图6 查看表test_demo01的Location
- 写入数据。
insert into test_demo01 values('mm'),('ww'),('ww');
执行select * from test_demo01;查询是否写入成功。
图7 查看表test_demo01中的数据
- 执行命令!q退出beeline客户端。
- 重新登录OBS控制台。
- 单击“并行文件系统”, 选择创建的文件系统名称。
- 单击“文件”,查看是否存在创建的数据。
- 用root用户登录集群Master节点,执行如下命令:




