
使用Jupyter Notebook对接MRS Spark
应用场景
在MRS服务中可以配合Jupyter Notebook使用PySpark,能够提高机器学习、数据探索和ETL应用开发效率。
本实践指导用户如何在MRS集群中配置Jupyter Notebook来使用Pyspark。
方案架构
Spark的应用运行架构如图1所示,运行流程如下所示:
- 应用程序(Application)是作为一个进程的集合运行在集群上的,由Driver进行协调。
- 在运行一个应用时,Driver会去连接集群管理器(Standalone、Mesos、YARN)申请运行Executor资源,并启动ExecutorBackend。然后由集群管理器在不同的应用之间调度资源。Driver同时会启动应用程序DAG调度、Stage划分、Task生成。
- 然后Spark会把应用的代码(传递给SparkContext的JAR或者Python定义的代码)发送到Executor上。
- 所有的Task执行完成后,用户的应用程序运行结束。

约束与限制
本实践仅适用于MRS 3.x及之后版本,且在集群外客户端节点中安装Python3。
操作流程
本实践基本操作流程如下所示:
步骤1:在MRS集群外节点安装客户端
- 准备一台不属于MRS集群的Linux弹性云服务器,绑定一个弹性IP,参考集群外节点安装客户端章节安装集群客户端,例如安装目录为“/opt/client”。
- 确认MRS集群是否开启了Kerberos认证。
- 是,执行3。
- 否,执行步骤2:安装Python3。
- 登录集群的Manager界面。
- 单击,创建一个业务用户。
用户类型为人机用户,用户组选择“hadoop”,主组选择“hadoop”,角色选择“Manager_operator”。
例如创建的用户为“mrs-test”。
图2 创建MRS业务用户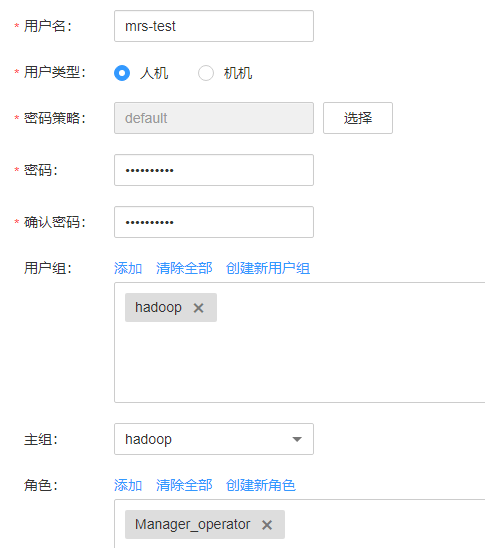
- 使用root用户,登录到集群客户端节点,执行如下命令配置环境变量并进行认证,首次进行用户认证需要修改用户密码。
source /opt/client/bigdata_env
kinit mrs-test
步骤2:安装Python3
- 使用root用户,登录集群外客户端节点,执行如下命令,检查是否安装了Python3。
python3 --version


本案例仅适用于集群外客户端节点安装Python3。
- 安装Python,此处以Python 3.6.6为例。
- 执行如下命令,安装相关依赖:
yum install zlib zlib-devel zip -y
yum install gcc-c++
yum install openssl-devel
yum install sqlite-devel -y
如果pandas库需要额外安装如下依赖:
yum install -y xz-devel
yum install bzip2-devel
- 下载对应Python版本源码。
wget https://www.python.org/ftp/python/3.6.6/Python-3.6.6.tgz
- 执行如下命令,解压python源码压缩包,例如下载在“opt”目录下。
tar -xvf Python-3.6.6.tgz
- 创建Python的安装目录,此处以“/opt/python36”为例。
- 编译Python。
./configure --prefix=/opt/python36
执行成功,显示结果如下:

执行make -j8命令,执行成功,显示结果如下:

执行make install命令,执行成功,显示结果如下:

- 执行如下命令,配置Python环境变量。
export PYTHON_HOME=/opt/python36
export PATH=$PYTHON_HOME/bin:$PATH
- 执行python3 --version命令,显示结果如下,表示Python已经安装完成。
Python 3.6.6
- 执行如下命令,安装相关依赖:
- 验证Python3。
pip3 install helloword
python3
import helloworld
helloworld.say_hello("test")

- 测试安装第三方Python库(如pandas、sklearn)。
pip3 install pandas

pip3 install backports.lzma

pip3 install sklearn

- 执行命令python3 -m pip list,查看安装结果。

- 打包Python.zip
cd /opt/python36/
zip -r python36.zip ./*
- 上传到HDFS指定目录。
hdfs dfs -mkdir /user/python
hdfs dfs -put python36.zip /user/python
- 配置MRS客户端。
进入Spark客户端安装目录“/opt/client/Spark2x/spark/conf”,在“spark-defaults.conf”配置文件如下参数。
spark.pyspark.driver.python=/usr/bin/python3 spark.yarn.dist.archives=hdfs://hacluster/user/python/python36.zip#Python
步骤3:安装Jupyter Notebook
- 使用root用户登录客户端节点,执行如下命令安装Jupyter Notebook。
pip3 install jupyter notebook
显示结果如下,表示安装成功:

- 为保障系统安全,需要生成一个密文密码用于登录Jupyter,放到Jupyter Notebook的配置文件中。
执行如下命令,需要输入两次密码:(进行到Out[3]退出)
ipython
[root@ecs-notebook python36]# ipython Python 3.6.6 (default, Dec 20 2021, 09:32:25) Type 'copyright', 'credits' or 'license' for more information IPython 7.16.2 -- An enhanced Interactive Python. Type '?' for help. In [1]: from notebook.auth import passwd In [2]: passwd() Enter password: Verify password: Out[2]: 'argon2:$argon2id$v=19$m=10240,t=10,p=8$g14BqLddl927n/unsyPlLQ$YmoKJzbUfNG7LcxylJzm90bgbKWUIiHy6ZV+ObTzdcA
- 执行如下命令生成Jupyter配置文件。
jupyter notebook --generate-config
- 修改配置文件。
vi ~/.jupyter/jupyter_notebook_config.py
添加如下配置:
# -*- coding: utf-8 -*- c.NotebookApp.ip='*' #此处填写ecs对应的内网IP c.NotebookApp.password = u'argon2:$argon2id$v=19$m=10240,t=10,p=8$NmoAVwd8F6vFP2rX5ZbV7w$SyueJoC0a5TbCuHYzqfSx1vQcFvOTTryR+0uk2MNNZA' # 填写步骤2,Out[2]密码生成的密文 c.NotebookApp.open_browser = False # 禁止自动打开浏览器 c.NotebookApp.port = 9999 # 指定端口号 c.NotebookApp.allow_remote_access = True
步骤4:验证Jupyter Notebook访问MRS
- 在客户端节点执行如下命令,启动Jupyter Notebook。
PYSPARK_PYTHON=./Python/bin/python3 PYSPARK_DRIVER_PYTHON=jupyter-notebook PYSPARK_DRIVER_PYTHON_OPTS="--allow-root" pyspark --master yarn --executor-memory 2G --driver-memory 1G
- 在浏览器中输入“弹性IP地址:9999”地址,登录到Jupyter WebUI(保证ECS的安全组对外放通本地公网IP和9999端口),登录密码为2设置的密码。
图3 登录Jupyter WebUI

- 创建代码。
创建一个新的python3任务,使用Spark读取文件。
图4 创建Python任务
登录到集群Manager界面,在Yarn的WebUI页面上查看提交的pyspark应用。
图5 查看任务运行情况
- 验证pandas库调用。
图6 验证pandas

对接Jupyter常见问题
pandas本地import使用时,报错如下:

参考以下步骤进行处理:
- 执行命令python -m pip install backports.lzma安装lzma模块,如下图所示:

- 进入“/usr/local/python3/lib/python3.6”目录(机器不同,目录也有所不同,可以通过which命令来查找当前运行python是使用的那个目录的),然后编辑lzma.py文件。
将:
from _lzma import * from _lzma import _encode_filter_properties, _decode_filter_properties
更改为:
try: from _lzma import * from _lzma import _encode_filter_properties, _decode_filter_properties except ImportError: from backports.lzma import * from backports.lzma import _encode_filter_properties, _decode_filter_properties修改前:

修改后:

- 保存退出,然后再次执行import。





