
使用Hive加载OBS数据并分析企业雇员信息
应用场景
MRS Hadoop分析集群,提供Hive、Spark离线大规模分布式数据存储和计算,进行海量数据分析与查询。
本实践基于华为云MapReduce服务,用于指导您创建MRS集群后,使用Hive对OBS中存储的原始数据进行导入、分析等操作,展示了如何构建弹性、低成本的存算分离大数据分析。
本实践中,雇员信息的原始数据包含以下两张表:
|
编号 |
姓名 |
支付薪水币种 |
薪水金额 |
纳税税种 |
工作地 |
入职时间 |
|---|---|---|---|---|---|---|
|
1 |
Wang |
R |
8000.01 |
personal income tax&0.05 |
China:Shenzhen |
2014 |
|
3 |
Tom |
D |
12000.02 |
personal income tax&0.09 |
America:NewYork |
2014 |
|
4 |
Jack |
D |
24000.03 |
personal income tax&0.09 |
America:Manhattan |
2015 |
|
6 |
Linda |
D |
36000.04 |
personal income tax&0.09 |
America:NewYork |
2014 |
|
8 |
Zhang |
R |
9000.05 |
personal income tax&0.05 |
China:Shanghai |
2014 |
|
编号 |
电话 |
邮箱 |
|---|---|---|
|
1 |
135 XXXX XXXX |
xxxx@example.com |
|
3 |
159 XXXX XXXX |
xxxxx@example.com.cn |
|
4 |
186 XXXX XXXX |
xxxx@example.org |
|
6 |
189 XXXX XXXX |
xxxx@example.cn |
|
8 |
134 XXXX XXXX |
xxxx@example.cn |
通过数据应用,进行以下分析:
- 查看薪水支付币种为美元的雇员联系方式。
- 查询入职时间为2014年的雇员编号、姓名等字段,并将查询结果加载到新表中。
- 统计雇员信息共有多少条记录。
- 查询使用以“cn”结尾的邮箱的员工信息。
方案架构
Hive是建立在Hadoop上的数据仓库框架,提供大数据平台批处理计算能力,能够对结构化/半结构化数据进行批量分析汇总完成数据计算。提供类似SQL的Hive Query Language语言操作结构化数据,其基本原理是将HQL语言自动转换成MapReduce任务,从而完成对Hadoop集群中存储的海量数据进行查询和分析。
Hive主要特点如下:
- 海量结构化数据分析汇总。
- 将复杂的MapReduce编写任务简化为SQL语句。
- 灵活的数据存储格式,支持JSON、CSV、TEXTFILE、RCFILE、SEQUENCEFILE、ORC等存储格式。
Hive作为一个基于HDFS和MapReduce架构的数据仓库,其主要能力是通过对HQL(Hive Query Language)编译和解析,生成并执行相应的MapReduce任务或者HDFS操作。

- Metastore:对表,列和Partition等的元数据进行读写及更新操作,其下层为关系型数据库。
- Driver:管理HQL执行的生命周期并贯穿Hive任务整个执行期间。
- Compiler:编译HQL并将其转化为一系列相互依赖的Map/Reduce任务。
- Optimizer:优化器,分为逻辑优化器和物理优化器,分别对HQL生成的执行计划和MapReduce任务进行优化。
- Executor:按照任务的依赖关系分别执行Map/Reduce任务。
- ThriftServer:提供thrift接口,作为JDBC的服务端,并将Hive和其他应用程序集成起来。
- Clients:包含WebUI和JDBC接口,为用户访问提供接口。
操作视频
本视频以自定义创建一个MRS集群为例,介绍如何在创建MRS集群时通过绑定IAM委托对接OBS,并使用Hive访问OBS数据。
因不同版本操作界面可能存在差异,相关视频供参考,具体以实际环境为准。
操作流程
本实践以用户开发一个Hive数据分析应用为例,通过客户端连接Hive后,执行HQL语句访问OBS中的Hive数据。进行企业雇员信息的管理、查询。如果需要基于MRS服务提供的样例代码工程开发构建应用,您可以参考Hive应用开发简介。
基本操作流程如下所示:
步骤1:创建MRS离线查询集群
- 进入购买MRS集群页面。
- 选择“快速购买”,填写软件配置参数。
表3 软件配置(以下参数仅供参考,可根据实际情况调整) 参数名称
参数说明
取值样例
计费模式
选择待创建的MRS集群的计费模式。
按需计费
区域
选择区域。
不同区域的云服务产品之间内网互不相通。请就近选择靠近您业务的区域,可减少网络时延,提高访问速度。
中国-香港
集群名称
待创建的MRS集群名称。
MRS_demo
集群类型
待创建的MRS集群类型。
选择“自定义”
版本类型
待创建的MRS集群版本类型。
普通版
集群版本
待创建的MRS集群版本。
MRS 3.1.0
组件选择
选择待创建的MRS集群配套的组件。
Hadoop分析集群
可用区
选择集群工作区域下关联的可用区。
可用区1
虚拟私有云
选择需要创建集群的VPC,单击“查看虚拟私有云”进入VPC服务查看已创建的VPC名称和ID。如果没有VPC,需要创建一个新的VPC。
vpc-01
子网
选择需要创建集群的子网,可进入VPC服务查看VPC下已创建的子网名称和ID。如果VPC下未创建子网,请单击“创建子网”进行创建。
subnet-01
集群节点
配置集群节点信息。
保持默认值。
Kerberos认证
登录Manager管理页面时是否启用Kerberos认证。
不开启
用户名
Manager管理员用户,目前默认为admin用户。
admin/root
密码
配置Manager管理员用户的密码。
设置密码登录集群管理页面及ECS节点用户的密码,例如:Test!@12345。
确认密码
再次输入Manager管理员用户的密码。
再次输入设置用户密码
企业项目
选择集群所属的企业项目。
default
通信安全授权
若不开启通信安全授权,MRS将无法创建集群。
勾选授权
- 单击“立即购买”,等待MRS集群创建成功。
步骤2:创建OBS委托并绑定至MRS集群

- MRS在IAM的委托列表中预置了MRS_ECS_DEFAULT_AGENCY委托,可在创建自定义过程中可以直接选择该委托,该委托拥有对象存储服务的OBSOperateAccess权限和在集群所在区域拥有CESFullAccess(对开启细粒度策略的用户)、CES Administrator和KMS Administrator权限。
- 如需使用自定义委托,请参考如下步骤进行创建委托(创建或修改委托需要用户具有Security Administrator权限)。
- 登录华为云管理控制台。
- 在服务列表中选择“管理与监管 > 统一身份认证服务 IAM”。
- 选择“委托 > 创建委托”。
- 设置“委托名称”,“委托类型”选择“云服务”,在“云服务”中选择“弹性云服务器ECS 裸金属服务器BMS”,授权ECS或BMS调用OBS服务。
- “持续时间”选择“永久”并单击“完成”。
图2 创建委托
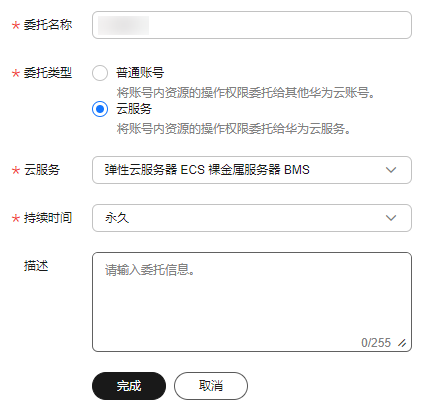
- 在创建的委托的“操作”列单击“授权”,搜索“OBS OperateAccess”策略,勾选“OBS OperateAccess”策略。
- 单击“下一步”,选择权限范围方案,默认选择“所有资源”,单击“展开其他方案”,选择“全局服务资源”。
- 单击“确定”,在弹出的提示框中单击“知道了”,开始授权。界面提示“授权成功。”,单击“完成”,委托成功创建。
- 返回MRS控制台,在集群列表中,单击已创建好的MRS集群名称,在集群的“概览”页面中,单击“选择委托”,选择创建好的OBS委托后单击“确定”。
步骤3:创建Hive表并加载OBS中数据
- 在服务列表中选择“存储 > 对象存储服务 OBS”,登录OBS控制台,单击“并行文件系统 > 创建并行文件系统”,填写以下参数,单击“立即创建”。
表4 并行文件系统参数 参数名称
参数说明
取值样例
区域
设置并行文件系统的区域。
中国-香港
文件系统名称
设置并行文件系统的名称
hiveobs
数据冗余存储策略
- 多AZ存储:数据冗余存储至多个可用区(AZ),可靠性更高。
- 单AZ存储:数据仅存储在单个可用区(AZ),成本更低。
单AZ存储
策略
并行文件系统的读写策略。
私有
归档数据直读
通过归档数据直读,您可以直接下载存储类别为归档存储的文件,而无需提前恢复。
关闭
企业项目
将并行文件系统加入到企业项目中统一管理。
default
标签
可选。标签用于标识OBS中的并行文件系统,以此达到对并行文件系统进行分类的目的。
-
- 下载并安装MRS集群客户端,例如在主Master节点上安装,客户端安装目录为“/opt/client”,相关操作可参考安装客户端。
也可直接使用Master节点中自带的集群客户端,安装目录为“/opt/Bigdata/client”。
- 为主Master节点绑定一个弹性IP并在安全组中放通22端口,然后使用root用户登录主Master节点,进入客户端所在目录并加载变量。
cd /opt/client
source bigdata_env
- 执行beeline命令进入Hive Beeline命令行界面。
执行以下命令创建一个与原始数据字段匹配的雇员信息数据表“employees_info”:
create external table if not exists employees_info
(
id INT,
name STRING,
usd_flag STRING,
salary DOUBLE,
deductions MAP<STRING, DOUBLE>,
address STRING,
entrytime STRING
)
row format delimited fields terminated by ',' map keys terminated by '&'
stored as textfile
location 'obs://hiveobs/employees_info';
执行以下命令创建一个与原始数据字段匹配的雇员联系信息数据表“employees_contact”:
create external table if not exists employees_contact
(
id INT,
phone STRING,
email STRING
)
row format delimited fields terminated by ','
stored as textfile
location 'obs://hiveobs/employees_contact';
- 查看表是否创建成功:
show tables;
+--------------------------+ | tab_name | +--------------------------+ | employees_contact | | employees_info | +--------------------------+
- 将数据导入OBS对应表目录下。
Hive内部表会默认在指定的存储空间中建立对应文件夹,只要把文件放入,表就可以读取到数据(需要和表结构匹配)。
登录OBS控制台,在已创建的文件系统的“文件”页面,将本地的原始数据分别上传至生成的“employees_info”、“employees_contact”文件夹下。
例如原始数据格式如下:
info.txt:
1,Wang,R,8000.01,personal income tax&0.05,China:Shenzhen,2014 3,Tom,D,12000.02,personal income tax&0.09,America:NewYork,2014 4,Jack,D,24000.03,personal income tax&0.09,America:Manhattan,2015 6,Linda,D,36000.04,personal income tax&0.09,America:NewYork,2014 8,Zhang,R,9000.05,personal income tax&0.05,China:Shanghai,2014
contact.txt:
1,135 XXXX XXXX,xxxx@xx.com 3,159 XXXX XXXX,xxxx@xx.com.cn 4,189 XXXX XXXX,xxxx@xx.org 6,189 XXXX XXXX,xxxx@xx.cn 8,134 XXXX XXXX,xxxx@xxx.cn
- 在Hive Beeline客户端中,执行以下命令,查询源数据是否被正确加载。
select * from employees_info;
+--------------------+----------------------+--------------------------+------------------------+-------------------------------+-------------------------+---------------------------+ | employees_info.id | employees_info.name | employees_info.usd_flag | employees_info.salary | employees_info.deductions | employees_info.address | employees_info.entrytime | +--------------------+----------------------+--------------------------+------------------------+-------------------------------+-------------------------+---------------------------+ | 1 | Wang | R | 8000.01 | {"personal income tax":0.05} | China:Shenzhen | 2014 | | 3 | Tom | D | 12000.02 | {"personal income tax":0.09} | America:NewYork | 2014 | | 4 | Jack | D | 24000.03 | {"personal income tax":0.09} | America:Manhattan | 2015 | | 6 | Linda | D | 36000.04 | {"personal income tax":0.09} | America:NewYork | 2014 | | 8 | Zhang | R | 9000.05 | {"personal income tax":0.05} | China:Shanghai | 2014 | +--------------------+----------------------+--------------------------+------------------------+-------------------------------+-------------------------+---------------------------+select * from employees_contact;
+-----------------------+--------------------------+--------------------------+ | employees_contact.id | employees_contact.phone | employees_contact.email | +-----------------------+--------------------------+--------------------------+ | 1 | 135 XXXX XXXX | xxxx@xx.com | | 3 | 159 XXXX XXXX | xxxx@xx.com.cn | | 4 | 186 XXXX XXXX | xxxx@xx.org | | 6 | 189 XXXX XXXX | xxxx@xx.cn | | 8 | 134 XXXX XXXX | xxxx@xxx.cn | +-----------------------+--------------------------+--------------------------+
步骤4:基于HQL对数据进行分析
在Hive Beeline客户端中,执行HQL语句,对原始数据进行分析。
- 查看薪水支付币种为美元的雇员联系方式。
创建新数据表进行数据清洗。
create table employees_info_v2 as select id, name, regexp_replace(usd_flag, '\s+','') as usd_flag, salary, deductions, address, entrytime from employees_info;
等待Map任务完成后,执行以下命令
select a.* from employees_info_v2 a inner join employees_contact b on a.id = b.id where a.usd_flag='D';
INFO : MapReduce Jobs Launched: INFO : Stage-Stage-3: Map: 1 Cumulative CPU: 2.95 sec HDFS Read: 8483 HDFS Write: 317 SUCCESS INFO : Total MapReduce CPU Time Spent: 2 seconds 950 msec INFO : Completed executing command(queryId=omm_20211022162303_c26d4f1b-a577-4d6c-919c-6cb96095b24b); Time taken: 26.259 seconds INFO : OK INFO : Concurrency mode is disabled, not creating a lock manager +-------+---------+-------------+-----------+-------------------------------+--------------------+--------------+ | a.id | a.name | a.usd_flag | a.salary | a.deductions | a.address | a.entrytime | +-------+---------+-------------+-----------+-------------------------------+--------------------+--------------+ | 3 | Tom | D | 12000.02 | {"personal income tax":0.09} | America:NewYork | 2014 | | 4 | Jack | D | 24000.03 | {"personal income tax":0.09} | America:Manhattan | 2015 | | 6 | Linda | D | 36000.04 | {"personal income tax":0.09} | America:NewYork | 2014 | +-------+---------+-------------+-----------+-------------------------------+--------------------+--------------+ 3 rows selected (26.439 seconds) - 查询入职时间为2014年的雇员编号、姓名等字段,并将查询结果加载进表employees_info_extended中的入职时间为2014的分区中。
创建一个表:
create table if not exists employees_info_extended (id int, name string, usd_flag string, salary double, deductions map<string, double>, address string) partitioned by (entrytime string) stored as textfile;
执行以下命令,在表中写入数据:
insert into employees_info_extended partition(entrytime='2014') select id,name,usd_flag,salary,deductions,address from employees_info_v2 where entrytime = '2014';
数据抽取成功后,查询表数据。
select * from employees_info_extended;
+-----------------------------+-------------------------------+-----------------------------------+---------------------------------+-------------------------------------+----------------------------------+------------------------------------+ | employees_info_extended.id | employees_info_extended.name | employees_info_extended.usd_flag | employees_info_extended.salary | employees_info_extended.deductions | employees_info_extended.address | employees_info_extended.entrytime | +-----------------------------+-------------------------------+-----------------------------------+---------------------------------+-------------------------------------+----------------------------------+------------------------------------+ | 1 | Wang | R | 8000.01 | {"personal income tax":0.05} | China:Shenzhen | 2014 | | 3 | Tom | D | 12000.02 | {"personal income tax":0.09} | America:NewYork | 2014 | | 6 | Linda | D | 36000.04 | {"personal income tax":0.09} | America:NewYork | 2014 | | 8 | Zhang | R | 9000.05 | {"personal income tax":0.05} | China:Shanghai | 2014 | +-----------------------------+-------------------------------+-----------------------------------+---------------------------------+-------------------------------------+----------------------------------+------------------------------------+ - 统计雇员信息有多少条记录。
select count(1) from employees_info_v2;
+------+ | _c0 | +------+ | 5 | +------+
- 查询使用以“cn”结尾的邮箱的员工信息。
select a.*, b.email from employees_info_v2 a inner join employees_contact b on a.id = b.id where b.email rlike '.*cn$';
+-------+---------+-------------+-----------+-------------------------------+------------------+--------------+-----------------+ | a.id | a.name | a.usd_flag | a.salary | a.deductions | a.address | a.entrytime | b.email | +-------+---------+-------------+-----------+-------------------------------+------------------+--------------+-----------------+ | 3 | Tom | D | 12000.02 | {"personal income tax":0.09} | America:NewYork | 2014 | xxxx@xx.com.cn | | 6 | Linda | D | 36000.04 | {"personal income tax":0.09} | America:NewYork | 2014 | xxxx@xx.cn | | 8 | Zhang | R | 9000.05 | {"personal income tax":0.05} | China:Shanghai | 2014 | xxxx@xxx.cn | +-------+---------+-------------+-----------+-------------------------------+------------------+--------------+-----------------+




