
消息堆积处理建议
方案概述
在RocketMQ的实际业务中,消息堆积是比较常见的问题。在消息处理过程中,如果客户端的消费速度跟不上服务端的发送速度,未处理的消息会越来越多,这部分消息就被称为堆积消息。消息没有被及时消费而产生消息堆积,从而会造成消息消费延迟。对于消息消费实时性要求较高的业务系统,即使是消息堆积造成的短暂消息延迟也无法接受。造成消息堆积的原因有以下两个:
- 消息没有及时被消费,生产者生产消息的速度快于消费者消费消息的速度,从而产生消息积压且无法自行恢复。
- 业务系统本身逻辑耗费时间较长,导致消息消费效率较低。
消息消费过程
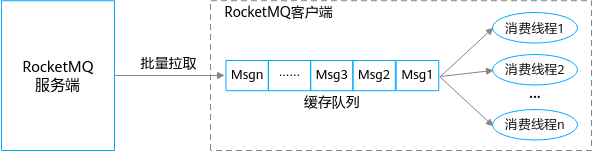
一个完整的消息消费过程主要分为2个阶段:
- 消息拉取
客户端通过批量拉取的方式从服务端获取消息,将拉取到的消息缓存到本地缓存队列中。对于拉取式消费,在内网环境下的吞吐量很高,因此消息拉取阶段一般不会引起消息堆积。
- 消息消费
客户端将本地缓存的消息提交到消费线程中,提供给业务消费逻辑进行消息处理,待消息处理完成后获取处理结果。此阶段的消费能力依赖于消息的消费耗时和消费并发度。如果由于业务处理逻辑复杂等原因,导致处理单条消息的耗时较长,就会影响整体的消息吞吐量。而消息吞吐量低会导致客户端本地缓存队列达到上限,从而停止从服务端拉取消息,引起消息堆积。
所以,消息堆积的主要瓶颈在于客户端的消费能力,而消费能力由消费耗时和消费并发度决定。消费耗时的优先级要高于消费并发度,应在保证消费耗时合理性的前提下,再考虑消费并发度问题。
消费耗时
影响消息处理时长的主要因素是业务处理的代码逻辑,而代码逻辑中会影响处理时长的主要有两种代码类型:CPU内部计算型代码和外部I/O操作型代码。如果代码中没有复杂的递归和循环处理,CPU内部计算耗时相对于外部I/O操作耗时来说几乎可以忽略,因此应关注外部I/O操作型代码的消息处理效率。
外部IO操作型代码主要有以下业务操作:
- 读写外部数据库,例如对远程MySQL数据库读写。
- 读写外部缓存系统,例如对远程Redis读写。
- 下游系统调用,例如Dubbo的RPC远程调用,Spring Cloud对下游系统的HTTP接口调用。
提前梳理下游系统的调用逻辑,掌握每个调用操作的预期耗时,有助于判断业务逻辑中I/O操作的耗时是否合理。通常消息堆积都是由于下游系统出现了服务异常或容量限制,从而导致消费耗时增加。而服务异常,并不仅仅是系统出现报错,也可能是更加隐蔽的问题,比如网络带宽问题。
消费并发度
客户端的消费并发度由单客户端线程数和客户端数量决定。单客户端线程数是指单个客户端所包含的线程数量,客户端数量是指消费组所包含的客户端(消费者)数量。对于普通消息、定时/延时消息、事务消息及顺序消息的消费并发度计算方法如下:
|
消息类型 |
消费并发度 |
|---|---|
|
普通消息 |
单客户端线程数 * 客户端数 |
|
定时/延时消息 |
|
|
事务消息 |
|
|
顺序消息 |
Min(单客户端线程数 * 客户端数,队列数) |
单客户端线程数的调整需谨慎,不能盲目调大线程数,如果设置过大的线程数反而会带来大量的线程切换开销。
理想环境下单客户端的最优线程数计算模型为:C *(T1+T2)/T1。
其中,C为单机vCPU核数,T1为业务逻辑的CPU计算耗时,T2为外部I/O操作耗时,另外线程切换耗时忽略不计,I/O操作不消耗CPU,线程需有足够消息等待处理且内存充足。
此处最大线程数的计算模型是在理想环境下得到的,在实际应用中建议逐步调大线程数,在观察效果后再进行调整。
实施方法
为了避免在实际业务中出现非预期的消息堆积问题,需要在业务系统的设计阶段梳理业务逻辑的消费耗时和设置消费并发度。
- 梳理消费耗时
通过压测获取消息的消费耗时,并对耗时较高的操作代码逻辑进行分析和优化。梳理消息的消费耗时需要注意以下几点:
- 消息消费逻辑的计算复杂度是否过高,代码是否存在复杂的递归和循环处理。
- 消息消费逻辑中的I/O操作是否是必须,是否可以使用本地缓存等方案规避。
- 消息消费逻辑中的复杂耗时操作是否可以做异步化处理。
- 设置消费并发度
对于消费并发度的计算,可以按如下方法进行处理:
- 根据公式计算出线程数的理想值,然后选取一个比理想值小的数据作为线程数起始值。逐步调大单个客户端的线程数,并观测客户端的系统指标,得到单个客户端的最优消费线程数和消息吞吐量。
- 根据上下游链路的流量峰值,计算出需要设置的客户端数量:客户端数=流量峰值/单客户端消息吞吐量。




