
更新时间:2024-09-30 GMT+08:00
HDFS的DataNode一直显示退服中
用户问题
HDFS的DataNode一直显示退服中。
问题现象
HDFS的某个DataNode退服(或者对Core节点进行缩容)任务失败,但是DataNode在任务失败后一直处于退服中的状态。
原因分析
在对HDFS的某个DataNode进行退服(或者对core节点进行缩容)过程中,因为Master节点重启或者nodeagent进程意外退出等情况出现,使得退服(或缩容)任务失败,并且没有进行黑名单清理。此时DataNode节点会一直处于退服中的状态,需要人工介入进行黑名单清理。
处理步骤
- 进入服务实例界面。
MRS Manager界面操作:
登录MRS Manager,在MRS Manager页面,选择“服务管理 > HDFS > 实例”。
FusionInsight Manager界面操作:
对于MRS 3.x及后续版本集群:也可登录FusionInsight Manager。选择“集群 > 服务 > HDFS > 实例”。
也可登录MRS控制台,选择“组件管理 > HDFS > 实例”。
- 查看HDFS服务实例状态,找到一直处于退服中的DataNode,复制这个DataNode的IP地址。
- 登录Master1节点的后台,执行cd ${BIGDATA_HOME}/MRS_*/1_*_NameNode/etc/命令进入黑名单目录。
- 执行sed -i "/^IP$/d" excludeHosts命令清理黑名单中的故障DataNode信息,该命令中IP替换为2中查询到的故障DataNode的IP地址,其中不能有空格。
- 如果有两个Master节点,请在Master2节点上同样执行3和4。
- 在Master1节点执行如下命令初始化环境变量。
source /opt/client/bigdata_env
- 如果当前集群已启用Kerberos认证,执行以下命令认证当前用户。如果当前集群未启用Kerberos认证,则无需执行此命令。
kinit MRS集群用户
例如, kinit admin
- 在Master1节点执行如下命令刷新HDFS的黑名单。
hdfs dfsadmin -refreshNodes
- 使用命令hdfs dfsadmin -report来查看各个DataNode的状态,确认中查到的IP对应的DataNode已经恢复为Normal状态。
图1 DataNode的状态
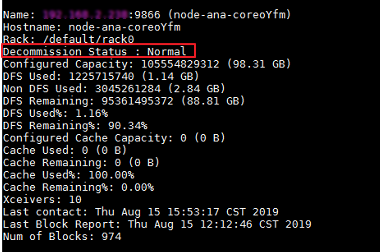
- 进入服务实例界面。
MRS Manager界面操作:
登录MRS Manager,在MRS Manager页面,选择“服务管理 > HDFS > 实例”。
FusionInsight Manager界面操作:
对于MRS 3.x及后续版本集群:可登录FusionInsight Manager。选择“集群 > 服务 > HDFS > 实例”。
登录MRS控制台,选择“组件管理 > HDFS > 实例”。
- 勾选一直处于退服中的DataNode实例,单击“更多 > 重启实例”。
- 等待重启完成,确认DataNode是否恢复正常。
建议与总结
尽量不要在退服(或缩容)过程中重启节点等高危操作。
参考信息
无
父主题: 使用HDFS




