
Bu sayfa henüz yerel dilinizde mevcut değildir. Daha fazla dil seçeneği eklemek için yoğun bir şekilde çalışıyoruz. Desteğiniz için teşekkür ederiz.
Connecting to an HTAP Instance for Complex OLAP Queries
You can let an application directly connect to an HTAP instance to enable complex OLAP queries.
Procedure
Step 1: Buy a Standard HTAP Instance
Step 2: Synchronize GaussDB(for MySQL) Data to the Standard HTAP Instance
Prerequisites
- Parameters have been configured for a GaussDB(for MySQL) instance according to the following table.
Table 1 Parameter description Parameter
Value
How to Modify
default_authentication_plugin
mysql_native_password
binlog_expire_logs_seconds
86400
 NOTE:
NOTE:
It is recommended that the binlog retention period be greater than one day. 86,400s = 60 (seconds) x 60 (minutes) x 24 (hours). This prevents incremental replication failures caused by a short binlog retention period.
log_bin
NOTE:
To use this parameter, ensure that the GaussDB(for MySQL) kernel version is earlier than 2.0.45.230900.
ON
How Do I Enable and View Binlog of My GaussDB(for MySQL) Instance?
rds_global_sql_log_bin
NOTE:
To use this parameter, ensure that the GaussDB(for MySQL) kernel version is 2.0.45.230900 or later.
ON
How Do I Enable and View Binlog of My GaussDB(for MySQL) Instance?
binlog_format
ROW
Run the SHOW VARIABLES; command to check the parameter value. If you need to change the parameter value, contact customer service.
binlog_row_image
FULL
Run the SHOW VARIABLES; command to check the parameter value. If you need to change the parameter value, contact customer service.
log_bin_use_v1_row_events
OFF
Run the SHOW VARIABLES; command to check the parameter value. If you need to change the parameter value, contact customer service.
- Databases and tables have been created for the GaussDB(for MySQL) instance.
Procedure
Step 1: Buy a Standard HTAP Instance
- Log in to the management console.
- Click
 in the upper left corner and select a region and project.
in the upper left corner and select a region and project. - Click
 in the upper left corner of the page and choose Databases > GaussDB(for MySQL).
in the upper left corner of the page and choose Databases > GaussDB(for MySQL). - On the Instances page, locate a GaussDB(for MySQL) instance and click its name to access the Basic Information page.
- In the navigation pane, choose HTAP Analysis. On the displayed page, click Create HTAP Instance.
- In the DB Instance Information area, check the current GaussDB(for MySQL) instance information.
Figure 1 Checking the GaussDB(for MySQL) instance information

- Set parameters for the HTAP instance.
Figure 2 Creating a standard HTAP instance
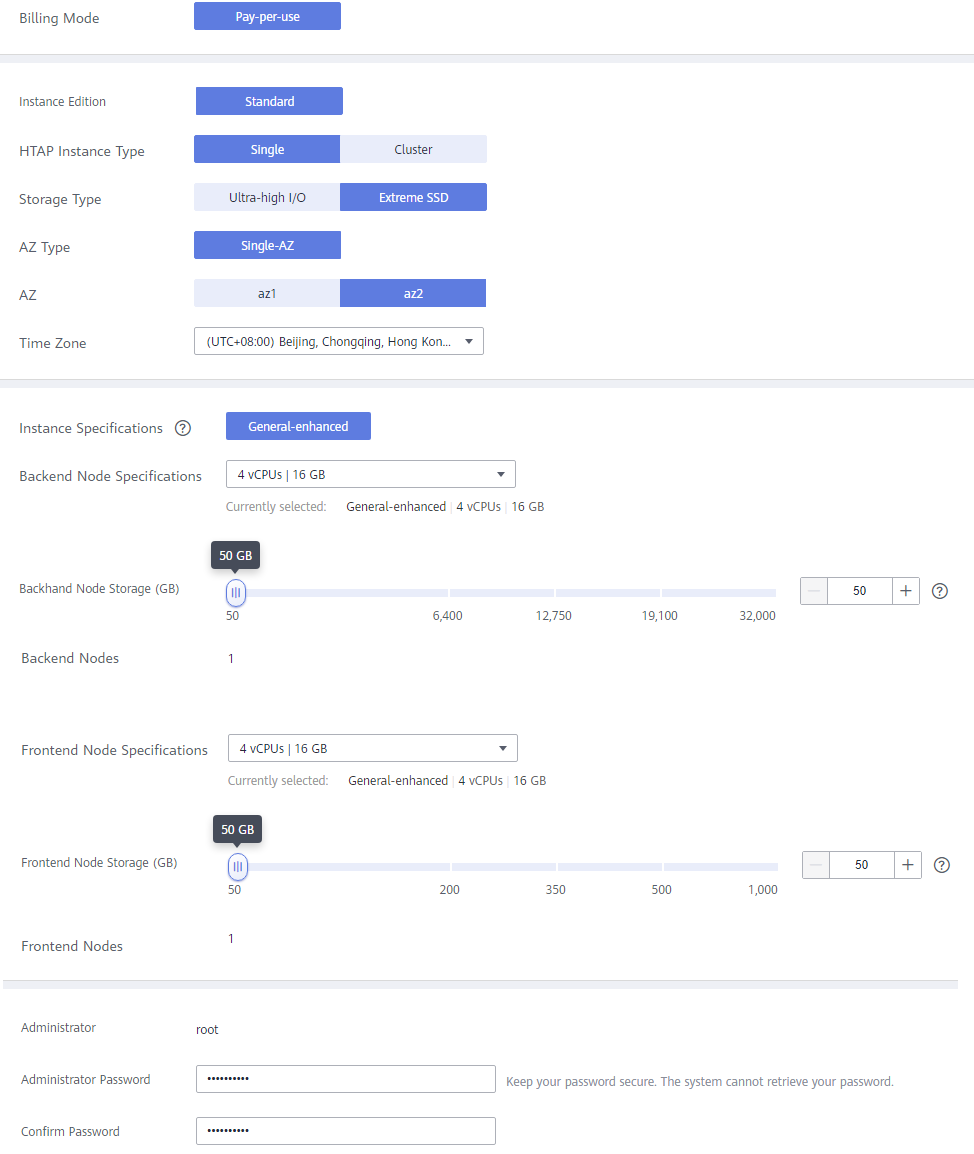
Table 2 Parameter description Parameter
Description
Billing Mode
Select Pay-per-use.
HTAP Instance Type
Select Single or Cluster.
- Single: There is only one FE node and one BE node. It is used only for function experience and testing and does not ensure SLA.
- Cluster: There are at least three FE or BE nodes and at most 10 FE or BE nodes.
Storage Type
Select Extreme SSD or Ultra-high I/O.
- Extreme SSD: uses a 25GE network and RDMA to provide you with up to 1 million random read/write performance per disk and low latency per channel.
- Ultra-high I/O: uses multi-disk striping to balance I/O loads among multiple disks, improving read/write bandwidth. The maximum throughput is 1.7 GB/s.
AZ Type
Only single-AZ is available.
AZ
Select an AZ as needed.
Time Zone
Select a time zone for your instance based on the region hosting your instance. The time zone is selected during instance creation and cannot be changed after the instance is created.
Instance Specifications
Only general-enhanced is available.
Backend Node Specifications
Select the BE node specifications.
The BE nodes are for data storage and SQL computing.
Backend Node Storage (GB)
Select the storage for BE nodes. The default storage is 50 GB and can be expanded to up to 32,000 GB.
Backend Nodes
- A single-node instance has only one BE node.
- A cluster instance has 3 to 10 BE nodes. You can apply for a maximum of 10 nodes at a time.
Frontend Node Specifications
Select the FE node specifications.
The FE nodes manage metadata, manage client connections, and plan and schedule queries.
Frontend Node Storage (GB)
Select the storage for FE nodes. The default storage is 50 GB and can be expanded to up to 1,000 GB.
Frontend Nodes
- A single-node instance has only one FE node.
- A cluster instance has 3 to 10 FE nodes. You can apply for a maximum of 10 nodes at a time.
Administrator
The default username is root.
Administrator Password
The password must consist of 8 to 32 characters and contain at least three types of the following characters: uppercase letters, lowercase letters, digits, and special characters (~!@#%^*-_=+?,()&$|.). Enter a strong password and periodically change it to improve security and defend against threats such as brute force cracking attempts.
Confirm Password
Enter the administrator password again.
- After configuration, click Next.
- Confirm the configuration and click Submit.
- On the HTAP instance list page, view and manage the HTAP instance.
Step 2: Synchronize GaussDB(for MySQL) Data to the Standard HTAP Instance
- On the Instances page, locate a GaussDB(for MySQL) instance and click its name to access the Basic Information page.
- In the navigation pane, choose HTAP Analysis.
- Click the name of an HTAP instance to access the Basic Information page.
- In the navigation pane, choose Data Synchronization. On the displayed page, click Create Synchronization Task.
- Configure required parameters.
Figure 3 Creating a synchronization task

- Currently, the databases whose name is Chinese cannot be synchronized. The destination database and task name cannot contain Chinese characters, and the destination database name must contain at least three characters.
- Synchronize Read Replica Data: Select Yes. You need to select a read replica. Full data is synchronized from the selected read replica, preventing query load on the primary node during a full synchronization. If there is only one read replica, this node is selected by default. During a full synchronization, ensure that the read replica is available, or the synchronization will fail and you will need to perform the synchronization again.
- Synchronization Task Name: The name can contain 3 to 128 characters. Only letters, digits, underscores (_) are allowed.
- Destination Database: The name can contain 3 to 128 characters. Only letters, digits, underscores (_) are allowed.
- Database to be Synchronized: Select a database that the data will be synchronized to from the drop-down list. You can modify the database parameters as required.
Figure 4 Setting databases to be synchronized

- Synchronization Scope: Select All Tables or Some Tables.
- Blacklist and Whitelist: If Synchronization Scope is set to Some Tables, you need to configure tables for the blacklist or whitelist. Set the blacklist and whitelist for the selected tables.
NOTE:
- You can set either a blacklist or a whitelist. If you select the whitelist, only the tables in the whitelist are synchronized.
- The tables to be synchronized must contain primary keys or a non-empty unique key, or they cannot be synchronized to the HTAP instance.
- Extra disk space may be used during backend data combination and query. You are advised to reserve 50% of the disk space for the system.
- When setting the table blacklist or whitelist, you can enter multiple tables in the search box at a time. The tables can be separated by commas (,), spaces, or line breaks (\n). After entering multiple tables, you need to click
 . These tables will be selected by default and displayed in the Selected Table area.
. These tables will be selected by default and displayed in the Selected Table area.

- Configure Table Operations: Enable or disable it as required.
- If you select Enabled:
- Select a synchronized table on the left and perform operations on its columns. The operations include order by, key columns, distributed by, partition by, data_model, buckets, replication_num, and enable_persistent_index. Multiple operations are separated by semicolons (;).
For details about the syntax, see Table 3.
Table 3 Operation syntax Operation Type
Syntax
order by
order by (column1, column2) or order by column1,column2
key columns
key columns (column1, column2) or key columns column1,column2
distributed by
distributed by (column1, column2) buckets 3
NOTE:
buckets is optional. If it is not set, the default value is used.
partition by
There are expression partitions and list partitions. For details, see the partition syntax example.
data_model
Specifies the table type. The value can be primary key, duplicate key, or unique key.
Syntax:
data_model=primary key, data_model=duplicate key, or data_model=unique key
replication_num
replication_num=3
NOTE:
The value cannot exceed the number of BE nodes, or the verification fails.
enable_persistent_index
Specifies whether to make the index persistent. Syntax:
enable_persistent_index=true or enable_persistent_index=false
Combined scenario
data_model=duplicate key;key columns column1, column2;
Partition syntax example:
You only need to set a partition expression (time function expression or lis expression) when creating a table. During data import, an HTAP instance automatically creates partitions based on the data and the rule defined in the partition expression.
Partitioning based on a time function expression: If data is often queried and managed based on a continuous date range, you only need to specify a partition column of the date type (DATE or DATETIME) and a partition granularity (year, month, day, or hour) in the time function expression. An HTAP instance automatically creates partitions and sets the start time and end time of the partitions based on the imported data and partition expression.
Syntax:
PARTITION BY expression ... [ PROPERTIES( 'partition_live_number' = 'xxx' ) ] expression ::= { date_trunc ( <time_unit> , <partition_column> ) | time_slice ( <partition_column> , INTERVAL <N> <time_unit> [ , boundary ] ) }Table 4 Parameter description Parameter
Mandatory
Description
expression
Yes
Currently, only the date_trunc and time_slice functions are supported. If you use time_slice, you do not need to configure the boundary parameter because this parameter can only be set to floor by default.
time_unit
Yes
Partition granularity. Currently, the value can only be hour, day, month, or year. If the partition granularity is hour, the partition columns can only be of the DATETIME type.
partition_column
Yes
Partition column.
- Only the date type (DATE or DATETIME) is supported. If date_trunc is used, the partition column can be of the DATE or DATETIME type. If time_slice is used, the partition column can only be of the DATETIME type. The value of the partition column can be NULL.
- If the partition column is of the DATE type, the value range is from 0000-01-01 to 9999-12-31. If the partition column is of the DATETIME type, the value range is from 0000-01-01 01:01:01 to 9999-12-31 23:59:59.
- Currently, only one partition column can be specified.
Example: If you often query data by day, you can use the partition expression date_trunc (), set the partition column to event_day, and set the partition granularity to day during table creation. In this way, data is automatically partitioned based on dates when being imported. Data of the same day is stored in the same partition. Partition pruning can significantly improve queries.
CREATE TABLE site_access1 ( event_day DATETIME NOT NULL, site_id INT DEFAULT '10', city_code VARCHAR(100), user_name VARCHAR(32) DEFAULT '', pv BIGINT DEFAULT '0' ) DUPLICATE KEY(event_day, site_id, city_code, user_name) PARTITION BY date_trunc('day', event_day) DISTRIBUTED BY HASH(event_day, site_id);Partitioning based on the column expression: If you often query and manage data based on enumerated values, you only need to specify the column representing the type as the partition column. An HTAP instance automatically divides and creates partitions based on the partition column value of the imported data.
Syntax:
PARTITION BY expression ... [ PROPERTIES( 'partition_live_number' = 'xxx' ) ] expression ::= ( <partition_columns> ) partition_columns ::= <column>, [ <column> [,...] ]Table 5 Parameter description Parameter
Mandatory
Description
partition_columns
Yes
Partition columns.
- The value can be a Character (BINARY is not supported), Date, Integer, or Boolean value. The value cannot be NULL.
- After the import, a partition automatically created can contain only one value of each partition column. If multiple values of each partition column need to be contained, use list partitioning.
Example: If you often query the equipment room billing details by date range and city, you can use a partition expression to specify the date and city as the partition columns when creating a table. In this way, data of the same date and city is grouped into the same partition, and partition pruning can be used to significantly accelerate queries.CREATE TABLE t_recharge_detail1 ( id bigint, user_id bigint, recharge_money decimal(32,2), city varchar(20) not null, dt varchar(20) not null ) DUPLICATE KEY(id) PARTITION BY (dt,city) DISTRIBUTED BY HASH(`id`);List partitioning
Data is partitioned based on a list of enumerated values that you explicitly define. You need to explicitly list the enumerated values contained in each list partition, and the values do not need to be consecutive.
List partitioning is suitable for storing columns where there are a small number of enumerated values and querying and managing data based on the enumerated values. For example, a column indicates a geographical location, status, or category. Each value of a column represents an independent category. Data is partitioned based on the enumerated values of columns to improve query performance and data management. List partitioning is especially suitable for scenarios where a partition needs to contain multiple values of each partition column. For example, the city column in a table indicates the city that an individual is from, and you often query and manage data by state and city. You can use the city column as the partition column for list partitioning when creating a table, and specify that data of multiple cities in the same state is stored in the same partition PARTITION pCalifornia VALUES IN ("Los Angeles","San Francisco","San Diego"), this feature accelerates queries and data management.
NOTE:
Partitions must be created during table creation. Partitions cannot be automatically created during data import. If the table does not contain the partitions corresponding to the data, an error is reported.
Syntax:PARTITION BY LIST (partition_columns)( PARTITION <partition_name> VALUES IN (value_list) [, ...] ) partition_columns::= <column> [,<column> [, ...] ] value_list ::= value_item [, value_item [, ...] ] value_item ::= { <value> | ( <value> [, <value>, [, ...] ] ) }Table 6 Parameter description Parameter
Mandatory
Description
partition_columns
Yes
Partition columns.
The value can be a Character (except BINARY), Date (DATE and DATETIME), Integer, or Boolean value. The value cannot be NULL.
partition_name
Yes
Partition name.
You are advised to set proper partition names to distinguish data categories in different partitions.
value_list
Yes
List of enumerated values of partition columns in a partition.
Example 1: If you often query the equipment room billing details by state or city, you can specify the city column as the partition column and specify that the cities in each partition belong to the same state. In this way, you can quickly query data of a specific state or city and manage data by state or city.
CREATE TABLE t_recharge_detail2 ( id bigint, user_id bigint, recharge_money decimal(32,2), city varchar(20) not null, dt varchar(20) not null ) DUPLICATE KEY(id) PARTITION BY LIST (city) ( PARTITION pCalifornia VALUES IN ("Los Angeles","San Francisco","San Diego"), --: These cities belong to the same state. PARTITION pTexas VALUES IN ("Houston","Dallas","Austin") ) DISTRIBUTED BY HASH(`id`);Example 2: If you often query the equipment room billing details by date range and state or city, you can specify the date and city as the partition columns when creating a table. In this way, data of a specific date and a specific state or city is grouped into the same partition, to accelerate queries and data management.
CREATE TABLE t_recharge_detail4 ( id bigint, user_id bigint, recharge_money decimal(32,2), city varchar(20) not null, dt varchar(20) not null ) ENGINE=OLAP DUPLICATE KEY(id) PARTITION BY LIST (dt,city) ( PARTITION p202204_California VALUES IN ( ("2022-04-01", "Los Angeles"), ("2022-04-01", "San Francisco"), ("2022-04-02", "Los Angeles"), ("2022-04-02", "San Francisco") ), PARTITION p202204_Texas VALUES IN ( ("2022-04-01", "Houston"), ("2022-04-01", "Dallas"), ("2022-04-02", "Houston"), ("2022-04-02", "Dallas") ) ) DISTRIBUTED BY HASH(`id`); - After entering the statement for performing column operations on the table, click Verify on the right of the area.
- Select a synchronized table on the left and perform operations on its columns. The operations include order by, key columns, distributed by, partition by, data_model, buckets, replication_num, and enable_persistent_index. Multiple operations are separated by semicolons (;).
- If you select Disabled, go to 6.
- If you select Enabled:
- After the settings are complete, click Create Synchronization Task.
- Confirm the settings and click Sync Now.
NOTE:
If you click Previous on the page or click
 in the upper left corner of the page to return to the data synchronization page, a synchronization task will be generated. The status of the task is Synchronization Stage: Waiting for synchronization. To start the task, click Synchronize in the Operation column.
in the upper left corner of the page to return to the data synchronization page, a synchronization task will be generated. The status of the task is Synchronization Stage: Waiting for synchronization. To start the task, click Synchronize in the Operation column. - Click Back to Synchronization List to return to the data synchronization page. View details about the task name, source database, destination database, status, and operations.
Figure 5 Viewing task status
 NOTE:
NOTE:
If the status of a task is Synchronization Stage: Incremental synchronization in progress, the data synchronization is complete.
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot


