
Using Snt9B for Distributed Training in a Lite Cluster Resource Pool
Description
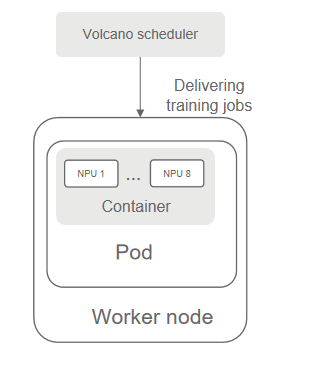
This case guides you through distributed training on Snt9B. By default, Lite Cluster resource pools come with the volcano scheduler, which delivers training jobs to clusters in volcano job mode. The BERT NLP model is used in the training test cases.
Procedure
- Pull the image. The test image is bert_pretrain_mindspore:v1, which contains the test data and code.
docker pull swr.cn-southwest-2.myhuaweicloud.com/os-public-repo/bert_pretrain_mindspore:v1 docker tag swr.cn-southwest-2.myhuaweicloud.com/os-public-repo/bert_pretrain_mindspore:v1 bert_pretrain_mindspore:v1
- Create the config.yaml file on the host.
Configure Pods using this file. For debugging, start a Pod with the sleep command. Alternatively, replace the command with the boot command for your job (for example, python train.py). The job will run once the container starts.
The file content is as follows:apiVersion: v1 kind: ConfigMap metadata: name: configmap1980-yourvcjobname #The prefix is configmap1980-, followed by the vcjob name. namespace: default #Namespace, which is optional and must be in the same namespace as vcjob. labels: ring-controller.cce: ascend-1980 # Retain the default settings. data: # The data content remains unchanged. After the initialization is complete, the data content is automatically modified by the Volcano plug-in. jobstart_hccl.json: | { "status":"initializing" } --- apiVersion: batch.volcano.sh/v1alpha1 # The value cannot be changed. The volcano API must be used. kind: Job # Only the job type is supported at present. metadata: name: yourvcjobname # Job name, which must be related to the name in the ConfigMap. namespace: default # The value must be the same as that of ConfigMap. labels: ring-controller.cce: ascend-1980 # Retain the default settings. fault-scheduling: "force" spec: minAvailable: 1 # The value of minAvailable is 1 in a single-node scenario and N in an N-node distributed scenario. schedulerName: volcano # Retain the default settings. Use the Volcano scheduler to schedule jobs. policies: - event: PodEvicted action: RestartJob plugins: configmap1980: - --rank-table-version=v2 # Retain the default settings. The ranktable file of the v2 version is generated. env: [] svc: - --publish-not-ready-addresses=true maxRetry: 3 queue: default tasks: - name: "yourvcjobname-1" replicas: 1 # The value of replicas is 1 in a single-node scenario and N in an N-node scenario. The number of NPUs in the requests field is 8 in an N-node scenario. template: metadata: labels: app: mindspore ring-controller.cce: ascend-1980 # Retain the default value. The value must be the same as the label in ConfigMap and cannot be changed. spec: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: volcano.sh/job-name operator: In values: - yourvcjobname topologyKey: kubernetes.io/hostname containers: - image: bert_pretrain_mindspore:v1 # Training framework image path, which can be modified. imagePullPolicy: IfNotPresent name: mindspore env: - name: name # The value must be the same as that of Jobname. valueFrom: fieldRef: fieldPath: metadata.name - name: ip # IP address of the physical node, which is used to identify the node where the pod is running valueFrom: fieldRef: fieldPath: status.hostIP - name: framework value: "MindSpore" command: - "sleep" - "1000000000000000000" resources: requests: huawei.com/ascend-1980: "1" # Number of required NPUs. The maximum value is 16. You can add lines below to configure resources such as memory and CPU. The key remains unchanged. limits: huawei.com/ascend-1980: "1" # Limits the number of cards. The key remains unchanged. The value must be consistent with that in requests. volumeMounts: - name: ascend-driver # Mount driver. Retain the settings. mountPath: /usr/local/Ascend/driver - name: ascend-add-ons # Mount driver. Retain the settings. mountPath: /usr/local/Ascend/add-ons - name: localtime mountPath: /etc/localtime - name: hccn # HCCN configuration of the driver. Retain the settings. mountPath: /etc/hccn.conf - name: npu-smi #npu-smi mountPath: /usr/local/sbin/npu-smi nodeSelector: accelerator/huawei-npu: ascend-1980 volumes: - name: ascend-driver hostPath: path: /usr/local/Ascend/driver - name: ascend-add-ons hostPath: path: /usr/local/Ascend/add-ons - name: localtime hostPath: path: /etc/localtime # Configure the Docker time. - name: hccn hostPath: path: /etc/hccn.conf - name: npu-smi hostPath: path: /usr/local/sbin/npu-smi restartPolicy: OnFailure - Create a pod based on the config.yaml file.
kubectl apply -f config.yaml
- Run the following command to check the pod startup status. If 1/1 running is displayed, the startup is successful.
kubectl get pod -A
- Go to the container, replace {pod_name} with your pod name (displayed by the get pod command), and replace {namespace} with your namespace (default).
kubectl exec -it {pod_name} bash -n {namespace} - Run the following command to view the NPU information:
npu-smi info
Kubernetes allocates resources to pods according to the number of NPUs specified in the config.yaml file. As illustrated in the figure below, only one NPU is displayed in the container, reflecting the single NPU configuration. This confirms that the configuration is effective.
Figure 2 Viewing NPU information
- Change the number of NPUs in the pod. In this example, distributed training is used. The number of required NPUs is changed to 8.
Delete the created pod.
kubectl delete -f config.yaml
Change the values of limit and request in the config.yaml file to 8.vi config.yaml
Figure 3 Modify the number of NPUs
Re-create a pod.
kubectl apply -f config.yaml
Go to the container and view the NPU information. Replace {pod_name} with your pod name and {namespace} with your namespace (default).kubectl exec -it {pod_name} bash -n {namespace} npu-smi infoAs shown in the following figure, 8 NPUs are used and the pod is successfully configured.
Figure 4 Viewing NPU information
- Run the following command to view the inter-NPU communication configuration file:
cat /user/config/jobstart_hccl.json
During multi-NPU training, the rank_table_file configuration file is essential for inter-NPU communication. This file is automatically generated and provides the file address once the pod is initiated. It takes a period of time to generate the /user/config/jobstart_hccl.json and /user/config/jobstart_hccl.json configuration files. The service process can generate the inter-NPU communication information only after the status field in /user/config/jobstart_hccl.json is completed. The process is shown in the figure below.
Figure 5 Inter-NPU communication configuration file
- Start a training job.
cd /home/ma-user/modelarts/user-job-dir/code/bert/ export MS_ENABLE_GE=1 export MS_GE_TRAIN=1 python scripts/ascend_distributed_launcher/get_distribute_pretrain_cmd.py --run_script_dir ./scripts/run_distributed_pretrain_ascend.sh --hyper_parameter_config_dir ./scripts/ascend_distributed_launcher/hyper_parameter_config.ini --data_dir /home/ma-user/modelarts/user-job-dir/data/cn-news-128-1f-mind/ --hccl_config /user/config/jobstart_hccl.json --cmd_file ./distributed_cmd.sh bash scripts/run_distributed_pretrain_ascend.sh /home/ma-user/modelarts/user-job-dir/data/cn-news-128-1f-mind/ /user/config/jobstart_hccl.json
Figure 6 Starting a training job
It takes some time to load a training job. After several minutes, run the following command to view the NPU information. As shown in the following figure, all the eight NPUs are occupied, indicating that the training task is in progress.
npu-smi info
Figure 7 Viewing NPU information
To stop a training task, run the commands below:
pkill -9 python ps -ef
Figure 8 Stopping the training process
Set limit and request to proper values to restrict the number of CPUs and memory size. A single Snt9B node is equipped with eight Snt9B cards and 192u1536g. Properly plan the CPU and memory allocations to avoid task failures due to insufficient CPU and memory limits.
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



