
Typical Deployment Architecture for Core Financial Applications (99.999% Availability)
Core financial applications require very short recovery time and can tolerate a small amount of data loss. The uptime needs to be up to 99.999%, that is, a maximum of 5.26 minutes of downtime per year.
Assume that the fault interruption duration and change interruption duration are as follows:
- Fault-caused interruptions: The duration must be as short as possible. Therefore, automatic recovery is required and no manual recovery can be triggered. Assume that there are four fault-caused interruptions each year. It takes 1 minute to recover automatically for each interruption. Thus, the total yearly interruption time is 4 minutes.
- Change-caused interruptions: Assume that applications support canary deployment or blue-green deployment, which are automatically completed. Software updates do not interrupt services.
As estimated above, the application system is unavailable for 4 minutes each year, meeting the design objectives for high availability.
The typical architecture of financial applications consists of three layers: frontend web cluster, backend application cluster, and backend database cluster. The frontend stateless applications can use ECS or CCE (CCE is used as an example in this section), and the backend databases use RDS for MySQL to provide higher performance and availability. To meet the required availability, the following solution is recommended:
|
Item |
Solution |
|---|---|
|
Redundancy |
Deploy cloud service instances in HA mode, such as ELB, CCE, DCS, Kafka, RDS, and DDS instances. |
|
Backup |
Enable automated backup for RDS and DDS databases. When a data fault occurs, the latest backup can be used to restore data, meeting availability requirements. |
|
DR |
Deploy applications across AZs so that services can be automatically restored when an AZ is faulty. Enable active-active DR across regions so that services can be quickly restored remotely when a region-level fault occurs. |
|
Monitoring metrics and alarms |
Monitor and check site statuses and instance workloads. If a site fails or a CCE, DCS, Kafka, RDS, or DDS instance is overloaded, an alarm is reported. |
|
Auto scaling |
Use CCE clusters with auto scaling of workloads. |
|
Change error prevention |
Use canary or blue-green deployment for software updates. The deployment is automatically completed and rolled back upon a fault. |
|
Emergency recovery |
Develop an emergency handling mechanism and designate related personnel to quickly make decisions and recover services. Provide solutions to common application and database problems as well as upgrade and deployment failures. Periodically perform drills to identify problems in a timely manner. |
A typical deployment architecture is as follows:
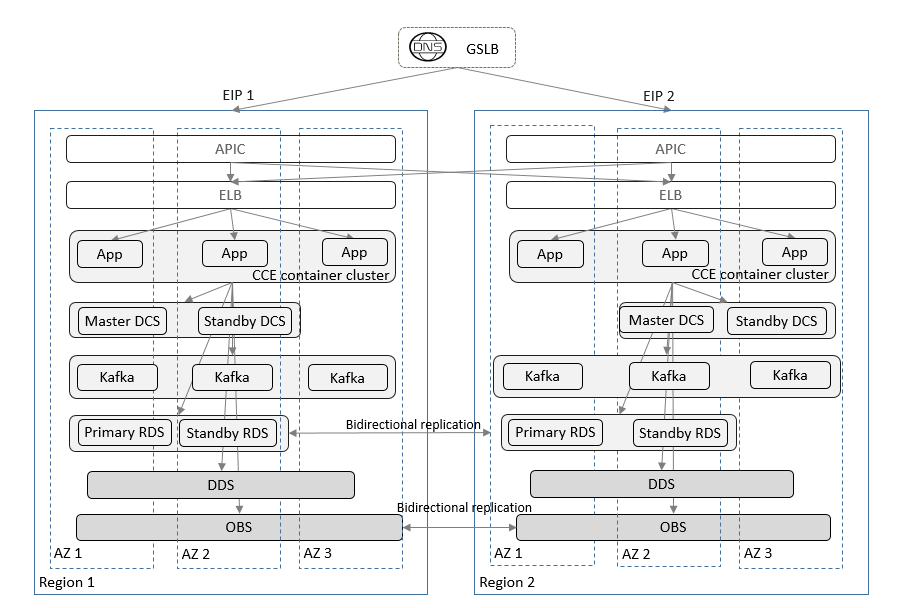
The architecture has the following features:
- The deployment architecture is layered with stateless applications and stateful databases.
- A complete application system is deployed in each of the two regions. Cross-AZ HA in a region provides active-active capabilities across DCs in the same city. Data units are deployed between regions for cross-region active-active DR. If a region is faulty, services can be quickly restored to another region.
- Access layer (external GSLB and API gateways): The external GSLB handles domain name resolution and traffic load balancing. Both regions provide services simultaneously, and if a region is faulty, service traffic is automatically redirected to another region. API gateways ensure traffic is correctly routed to the appropriate service units.
- Application layer (ELBs, application software, and containers): ELBs are used to detect faults and distribute loads for stateless applications, while containers enable elastic scaling.
- Middleware layer: Redis and Kafka clusters are deployed across AZs for high availability.
- Data layer: MySQL databases are deployed across AZs for high availability. DRS is used to implement cross-region bidirectional database replication and DR failover. Data can be automatically backed up periodically to quickly restore data in the event of data loss. OBS also supports cross-region bidirectional database replication.
- The data in RDS for MySQL and DDS databases is automatically backed up periodically to ensure data reliability.
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



