
Platform Survey
Big Data Survey Overview
Big data migration is the process of migrating big data clusters, big data task scheduling platforms, and big data applications from one runtime environment to another.

The following information needs to be surveyed for big data migration:
- Big data platforms, including big data clusters, task scheduling platforms, and data flows.
- Data information, including type, volume, metadata, permissions, and update frequency.
- Task information, including the type, number, and update period.
This section describes how to survey big data platforms, data, and tasks.
Platform Survey
The following describes the details.
- Big data cluster survey
Survey the number and functions of big data clusters, services and data types processed by each cluster or component, components that process real-time or offline data and detailed version information, data format types and compression algorithms, data security and permission control, high availability (HA) and fault tolerance mechanisms, scalability, and elasticity.
Survey the number and functions of big data clusters: For example, Hadoop, Spark, and Hive clusters serve as storage, computing, and query clusters based on service requirements.
Survey the service scope of each cluster or component, types of data they process, and data transfer modes.
Survey the components used to process real-time and offline data. For example, real-time data may be processed by Apache Kafka and Apache Flink, and offline data may be processed by Hadoop and Spark.
Survey the data format types and compression algorithms:
Survey the data security and permission control mechanisms of the platform, such as data encryption and user access permission management.
Understand the HA and fault tolerance mechanisms of big data clusters, including fault recovery, backup policies, and disaster recovery (DR) solutions.
- Big data task scheduling platform survey
Survey the big data task scheduling platform details for future selection and solution design, including the type, version, supported big data framework and technologies, scheduling task type, visualized and management GUI, scalability and integration, fault tolerance and recovery, security and permission control, community support, and documentation.
Survey the type of the platform, such as Azkaban. Understand its features and applications.
Survey the version of the platform and learn the function updates and improvements of the latest version.
Check whether the platform supports the current big data framework and technologies, such as Hadoop, Spark, Hive, Pig, and Flink.
Survey the task types supported by the platform, including Jar tasks, SQL tasks, and script tasks (Python and Shell).
Check whether a visualized and management GUI is provided by the platform for configuring, monitoring, and managing task scheduling.
Understand the fault tolerance mechanism of the platform, including the retry mechanism upon task failure and the fault recovery policy.
- Data flow survey
The figure below shows the architecture and data flow diagram of the big data platform and services.
Data access source of the platform.
Data inflow mode, for example, real-time data reporting and batch data extraction.
Analyze the data flow in the big data platform and between its components, such as data collection component types, the next layer after collection, data storage components, and data processing workflows.
Figure 2 Data flow example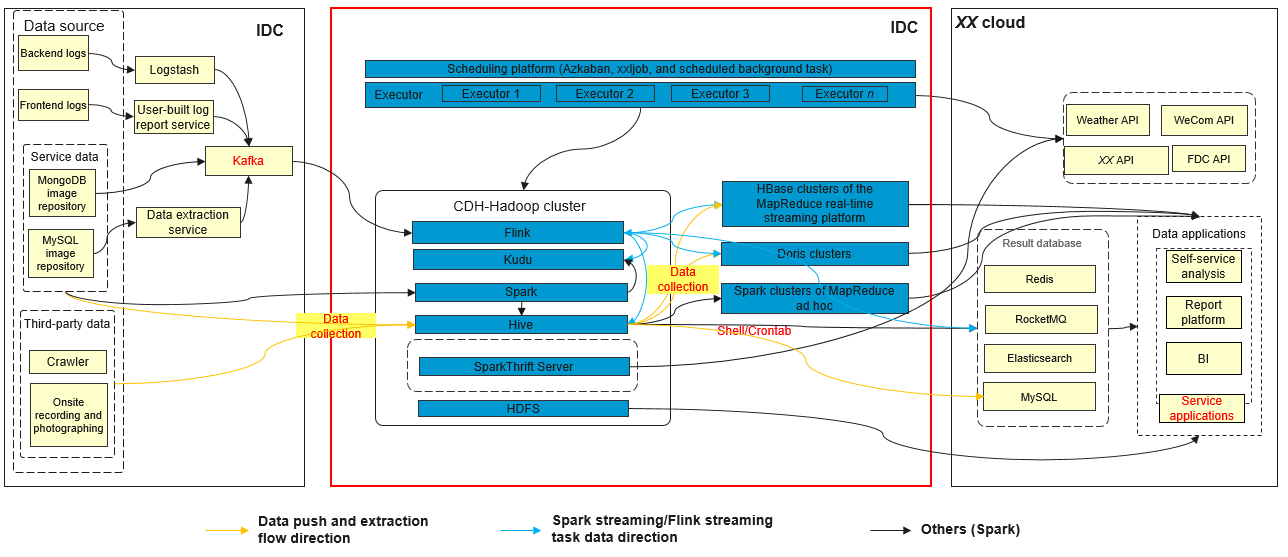
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



