
GraphBase Key Features
Key Feature: Multi-Graph
Scenario
- Different service departments can use the same graph database to import different graphs for application development.
- Different applications use different data. Data is not associated, which facilitates service isolation.
Design of Multi-Graph Solution
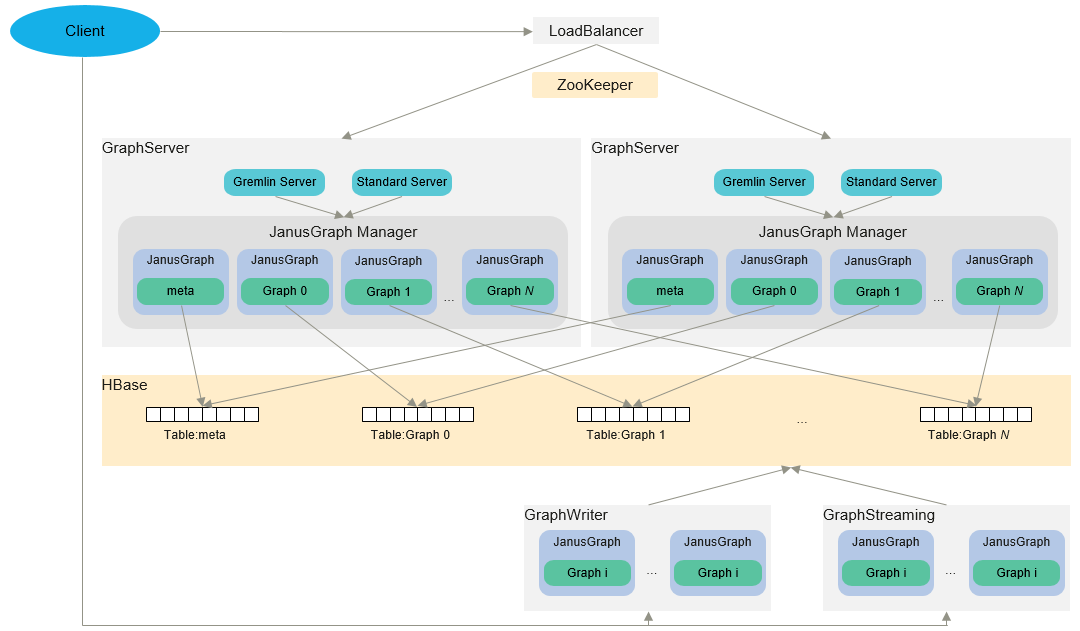
- GraphServer: includes the GremlinServer and StandardServer services. GremlinServer is used for the graph query using Gremlin, and StandardServer is used for the REST service. When the system is started, the meta_graph graph is started first. The meta_graph graph is used to store multi-graph metadata and asynchronous tasks. ZooKeeper monitors live instances in services and provides distributed lock services.
- LoadBalancer: balances the load of GraphServer.
- GraphWriter: is the module for batch data import.
- GraphStreaming: is used for real-time data import.
Key Feature: Data Import
Batch Import and Real-Time Import
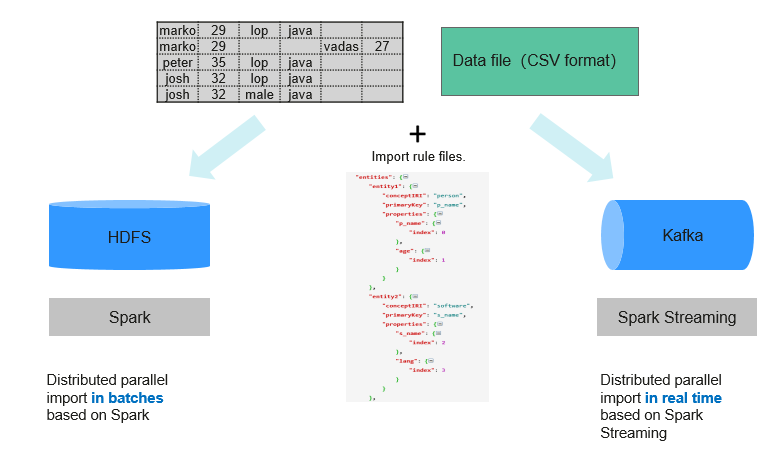
GraphBase supports batch data import and real-time data import. For batch data import, Spark is used to import all historical data stored in HDFS to GraphBase. For real-time data import, Kafka and SparkStreaming are used to import data to GraphBase in real time.
Flexible data mapping rules are provided to map original data to graph models.
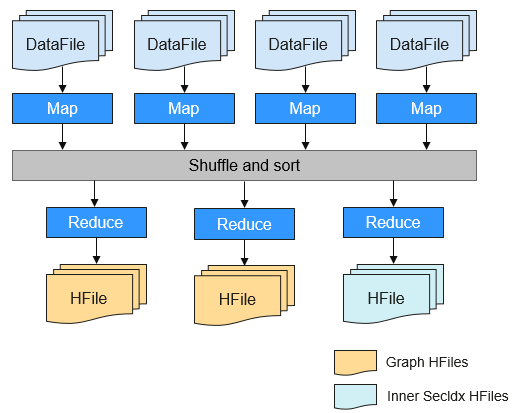
BulkLoad Supported in Batch Data Import
The capability of importing data in BulkLoad mode is added to facilitate data import.
During data import, Graph HFiles and Inner secondary index HFiles can be generated in one MapReduce job.
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



