
GraphBase Basic Principles
Overview
With the quick development of network technologies, enterprises in the Internet era are facing massive data. As the number of data sets increases, the query performance of traditional relational databases deteriorates, especially for some special service scenarios. Therefore, a new solution is urgently needed to cope with this problem. To resolve the complex relationship problem, GraphBase came into being.
In GraphBase, data is stored and queried by graph. A graph contains nodes and relationships. Nodes and relationships can have labels and attributes, and edges can have directions. GraphBase is a distributed graph database. Based on the distributed storage mechanism of HBase, it supports data of tens of billions of nodes and hundreds of billions of relationships, and provides Spark-based data import and Elasticsearch-based index mechanisms. GraphBase is widely used in recommendations, relationship analysis, and financial anti-fraud. GraphBase has the following features:
- Distributed architecture and seamless integration with the Hadoop ecosystem.
- Queries of hundreds of billions of relationships on tens of billions of nodes in just seconds.
- Easy-to-use REST APIs to facilitate data query and analysis.
- Powerful Gremlin graph traversal function to implement complex service logic.
- Offline batch import, real-time stream import, and import performance optimization.
GraphBase architecture
GraphBase contains GraphServer and LoadBalancer.
- GraphServer: includes the GremlinServer and StandardServer services. GremlinServer is used for the graph query using Gremlin, and StandardServer is used for the REST service. When the system is started, the meta_graph graph is started first. The meta_graph graph is used to store multi-graph metadata and asynchronous tasks. ZooKeeper monitors live instances in services and provides distributed lock services.
- LoadBalancer: balances the load of GraphServer.
Figure 1 shows the GraphBase architecture.
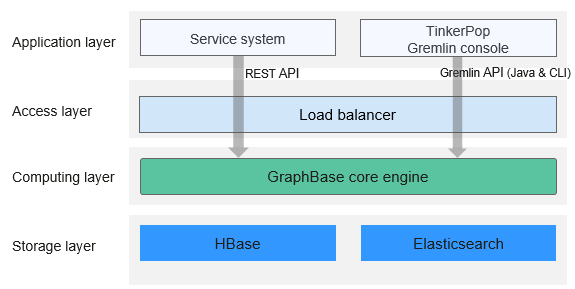
- Access layer
- Gremlin API: is an open-source standard language API for graph interactive query based on the Apache TinkerPop Gremlin.
- REST API: includes APIs for graph query, modification, and management, and graph algorithm enhanced online analysis.
- Load Balancer: provides load sharing for multi-instance GraphServer.
- Compute layer
- Provides a core engine of data management and metadata management for GraphBase.
- Provides API adaptation for backend storage and index.
- Storage layer
- Distributed KV storage: provides massive graph data storage capabilities.
- Provides a search engine with secondary index, full-text search, and fuzzy search capabilities.
Typical application scenarios:
- Financial anti-fraud
- Knowledge graph
- Relationship analysis
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



