
Fragmentação
Você pode fragmentar uma coleção de tamanho grande para uma instância de cluster fragmentado. A fragmentação distribui dados em diferentes máquinas para aproveitar ao máximo o espaço de armazenamento e a capacidade de computação de cada fragmento.
Número de fragmentos
O seguinte é um exemplo usando banco de dados mytable, coleção mycoll e o campo name como a chave de fragmento.
- Faça logon em uma instância de cluster fragmentado usando o Mongo Shell.
- Verifique se uma coleção foi fragmentada.
use <database> db.<collection>.getShardDistribution()
Exemplo:
use mytable db.mycoll.getShardDistribution()

- Habilite fragmentação para os bancos de dados que pertencem à instância do cluster.
- Método 1
sh.enableSharding("<database>")Exemplo:
sh.enableSharding("mytable") - Método 2
use admin db.runCommand({enablesharding:"<database>"})
- Método 1
- Fragmente uma coleção.
- Método 1
sh.shardCollection("<database>.<collection>",{"<keyname>":<value> })Exemplo:
sh.shardCollection("mytable.mycoll",{"name":"hashed"},false,{numInitialChunks:5}) - Método 2
use admin db.runCommand({shardcollection:"<database>.<collection>",key:{"keyname":<value> }})
Tabela 1 Descrição do parâmetro Parâmetro
Descrição
<database>
Nome do banco de dados
<collection>
Nome da coleção.
<keyname>
Chave de fragmento.
As instâncias de cluster são fragmentadas com base no valor deste parâmetro. Selecione uma chave de fragmento adequada para a coleção com base em seus requisitos de serviço. Para mais detalhes, consulte Seleção de uma chave de fragmento.
<value>
A ordem de classificação com base no intervalo da chave de fragmento.- 1: Índices ascendentes
- -1: Índices descendentes
- hashed: indica que a fragmentação de hash é usada. A fragmentação de hash fornece uma distribuição de dados mais uniforme no cluster fragmentado.
Para obter detalhes, consulte sh.shardCollection().
numInitialChunks
Opcional. O número mínimo de fragmentos criados inicialmente é especificado quando uma coleção vazia é fragmentada usando uma chave de fragmento com hash.
- Método 1
- Verifique o status de armazenamento de dados do banco de dados em cada fragmento.
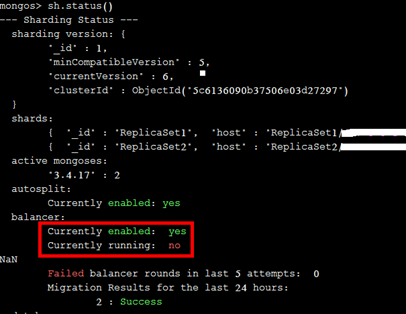
sh.status()
Exemplo:
Seleção de uma chave de fragmento
- Fundo
Cada cluster fragmentado contém coleções como sua unidade básica. Os dados na coleção são particionados pela chave de fragmento. Chave de fragmento é um campo na coleção. Ela distribui dados uniformemente entre fragmentos. Se você não selecionar uma chave de fragmento adequada, o desempenho do cluster pode se deteriorar e o processo de execução da instrução de fragmentação pode ser bloqueado.
Uma vez que a chave de fragmento é determinada, ela não pode ser alterada. Se nenhuma chave de fragmento for adequada para fragmentação, você precisará usar uma política de fragmentação e migrar os dados para uma nova coleção de fragmentação.
- Características das chaves de fragmento adequadas
- Todas as inserções, atualizações e exclusões são distribuídas uniformemente para todos os fragmentos em um cluster.
- A distribuição de chaves é suficiente.
- Consultas de dispersão-recolha raras.
Se a chave de fragmento selecionada não tiver todos os recursos anteriores, a escalabilidade de leitura e gravação do cluster será afetada. Por exemplo, se a carga de trabalho da operação find() for distribuída de forma desigual nos fragmentos, os fragmentos quentes serão gerados. Da mesma forma, se sua carga de gravação (inserções, atualizações e exclusões) não for distribuída uniformemente entre seus fragmentos, você poderá acabar com um fragmento quente. Portanto, você precisa ajustar as chaves de fragmento com base nos requisitos de serviço, como status de leitura/gravação, dados consultados com frequência e dados gravados.
Depois que os dados existentes forem fragmentados, se o campo filter da solicitação de atualização não contiver chaves de fragmento e upsert:true ou multi:false, a solicitação de atualização relatará um erro e retornará a mensagem "Um upsert em uma coleção fragmentada deve conter a chave de fragmento e ter o agrupamento simples.".
- Critérios de julgamento Você pode usar as dimensões fornecidas em Tabela 2 para determinar se as chaves de fragmento selecionadas atendem aos seus requisitos de serviço:
Tabela 2 Chaves de fragmento razoáveis Critérios de Identificação
Descrição
Cardinalidade
Cardinalidade refere-se à capacidade de dividir pedaços. Por exemplo, se você precisar registrar as informações do aluno de uma escola e usar a idade como uma chave de fragmento, os dados dos alunos da mesma idade serão armazenados em apenas um segmento de dados, o que pode afetar o desempenho e a capacidade de gerenciamento dos clusters. Uma chave de fragmento muito melhor seria o número do aluno porque é único. Se o número do aluno for usado como uma chave de fragmento, a cardinalidade relativamente grande pode garantir a distribuição uniforme dos dados.
Distribuição de gravação
Se um grande número de operações de gravação for executado no mesmo período de tempo, você deseja que a carga de gravação seja distribuída uniformemente pelos fragmentos no cluster. Se a política de distribuição de dados for fragmentos por intervalo, uma chave de fragmento monotonicamente crescente garantirá que todas as inserções entrem em um único fragmento.
Distribuição de leitura
Da mesma forma, se um grande número de operações de leitura for executado no mesmo período, você deseja que a carga de leitura seja distribuída uniformemente pelos estilhaços em um cluster para utilizar totalmente o desempenho de computação de cada fragmento.
Leitura direcionada
O roteador de consulta de dds mongos pode executar uma consulta direcionada (consultar apenas um fragmento) ou uma consulta de dispersão/coleta (consultar todos os fragmentos). A única maneira de o dds mongos conseguir direcionar um único fragmento é ter a chave do fragmento presente na consulta. Portanto, você precisa escolher uma chave de fragmento que estará disponível para uso nas consultas comuns enquanto a aplicação estiver em execução. Se você escolher uma chave de fragmento sintética e sua aplicação não puder usá-la durante consultas típicas, todas as suas consultas se tornarão dispersas/recolhedoras, limitando assim sua capacidade de dimensionar a carga de leitura.
Escolha de uma política de distribuição
Um cluster fragmentado pode armazenar os dados de uma coleção em vários fragmentos. Você pode distribuir dados com base nas chaves de fragmento de documentos na coleção.
Existem duas políticas de distribuição de dados: fragmentação ranged e fragmentação hash. Para mais detalhes, consulte 4.
A seguir descrevem-se as vantagens e desvantagens dos dois métodos.
- Fragmentação variada
A fragmentação baseada em intervalos envolve a divisão de dados em intervalos contíguos determinados pelos valores-chave da fragmento. Se você assumir que uma chave de fragmento é uma linha estendida de infinito positivo e infinito negativo, cada valor da chave de fragmento é a marca na linha. Você também pode assumir segmentos pequenos e separados de uma linha e que cada bloco contém dados de uma chave de fragmento dentro de um determinado intervalo.
Figura 1 Distribuição dos dados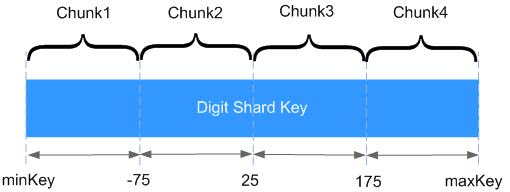
Como mostrado na figura anterior, o campo x indica a chave de fragmento de fragmentação variada. O intervalo de valores é [minKey,maxKey] e o valor é um número inteiro. O intervalo de valores pode ser dividido em vários blocos, e cada bloco (geralmente 64 MB) contém um pequeno segmento de dados. Por exemplo, o bloco 1 contém todos os documentos no intervalo [minKey, -75] e todos os dados de cada bloco são armazenados no mesmo fragmento. Isso significa que cada fragmento contém vários pedaços. Além disso, os dados de cada fragmento são armazenados no servidor de config e distribuídos uniformemente pelo dds mongos com base na carga de trabalho de cada fragmento.
A fragmentação por intervalo pode atender facilmente aos requisitos de consulta em um determinado intervalo. Por exemplo, se você precisar consultar documentos cuja chave de fragmento esteja no intervalo [-60,20], o dds mongos só precisa encaminhar a solicitação para o chunk 2.
No entanto, se as chaves de fragmento estiverem em ordem crescente ou decrescente, os documentos recém-inseridos provavelmente serão distribuídos para o mesmo bloco, afetando a expansão da capacidade de gravação. Por exemplo, se _id for usado como uma chave de fragmento, os bits altos de _id gerados automaticamente no cluster serão ascendentes.
- Fragmentação com hash
A fragmentação com hash calcula o valor de hash (inteiro de 64 bits) de um único campo como o valor de índice; esse valor é usado como sua chave de fragmento para particionar dados em seu cluster compartilhado. A fragmentação em hash proporciona uma distribuição de dados mais uniforme no cluster fragmentado porque documentos com chaves de fragmento semelhantes podem não ser armazenados no mesmo bloco.
Figura 2 Distribuição dos dados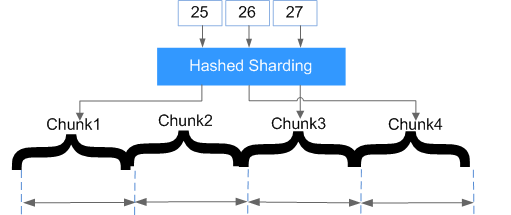
A fragmentação em hash distribui documentos aleatoriamente para cada bloco, o que expande totalmente a capacidade de gravação e compensa a deficiência da fragmentação em intervalo. No entanto, as consultas em um determinado intervalo precisam ser distribuídas para todos os fragmentos de back-end para obter documentos que atendam às condições, resultando em baixa eficiência de consulta.




