
Help Center/
MapReduce Service/
User Guide (Ankara Region)/
Overview/
Components/
GraphBase/
Relationship Between GraphBase and Other Components
Updated on 2024-11-29 GMT+08:00
Relationship Between GraphBase and Other Components
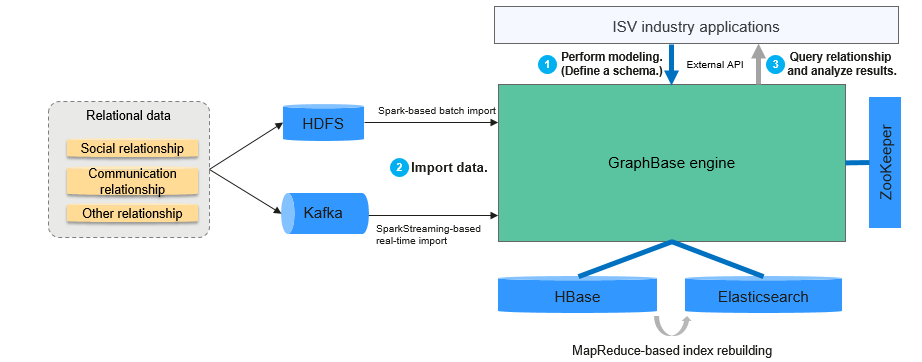
Service data and metadata are stored in HBase to support massive data. External index data is stored in Elasticsearch to implement query capabilities such as full-text search and fuzzy match. GraphBase uses Spark to implement batch and real-time data import, uses MapReduce to implement index recreation and batch deletion, and uses ZooKeeper to implement distributed coordination of multiple instances of the compute engine.
Figure 1 shows the relationship between GraphBase and other components.
Parent topic: GraphBase
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
The system is busy. Please try again later.
For any further questions, feel free to contact us through the chatbot.
Chatbot



