
Help Center/
MapReduce Service/
Component Operation Guide (LTS) (Ankara Region)/
Using Solr/
Common Service Operations About Solr/
Restoring Data using Solr
Updated on 2024-11-29 GMT+08:00
Restoring Data using Solr
Scenario
This section describes how to use Solr to restore HDFS data that is mistakenly deleted during the deletion of indexes or replicas.
Prerequisites
- Solr has been installed and HDFS is running properly. Solr data is stored in HDFS. You can determine whether Solr data is stored in HDFS by checking whether the value of INDEX_STORED_ON_HDFS is true.
- The client has been installed in a directory, for example, /opt/client.
- The HDFS recycle bin mechanism has been enabled for the cluster (this function is enabled by default). Periodic Solr tasks for backing up metadata exist and are running properly.
- If the cluster is in security mode, ensure that you have created a user who has operation permissions on Solr and HDFS, for example, testuser (skip this step in normal mode).
Procedure
- Restore Solr metadata and restart the Solr service. For details, see "Restoring Solr Metadata" in .
- On FusionInsight Manager, choose Cluster > Services > Solr. On the displayed page, click Stop Service, verify the password, and wait until the service is stopped.
- Log in to the node where the client is installed as the client installation user. Run the following commands to log in to the client and authenticate the user:
cd /opt/client
source bigdata_env
kinit testuser (skip this step if the cluster is in normal mode. Change the password upon the first authentication.)
- Run the command for each copy to copy the data in the HDFS recycle bin to the HDFS data directory of the index.
For example, if the index name is test1 and the replica name is core_node3, run the following command:
hdfs dfs -cp -f /user/solr/.Trash/Current/solr/collections/test1/core_node3/data /solr/collections/test1/core_node3

Specifically:
- -f: indicates the enhanced parameter that is used for forcibly overwriting the data.
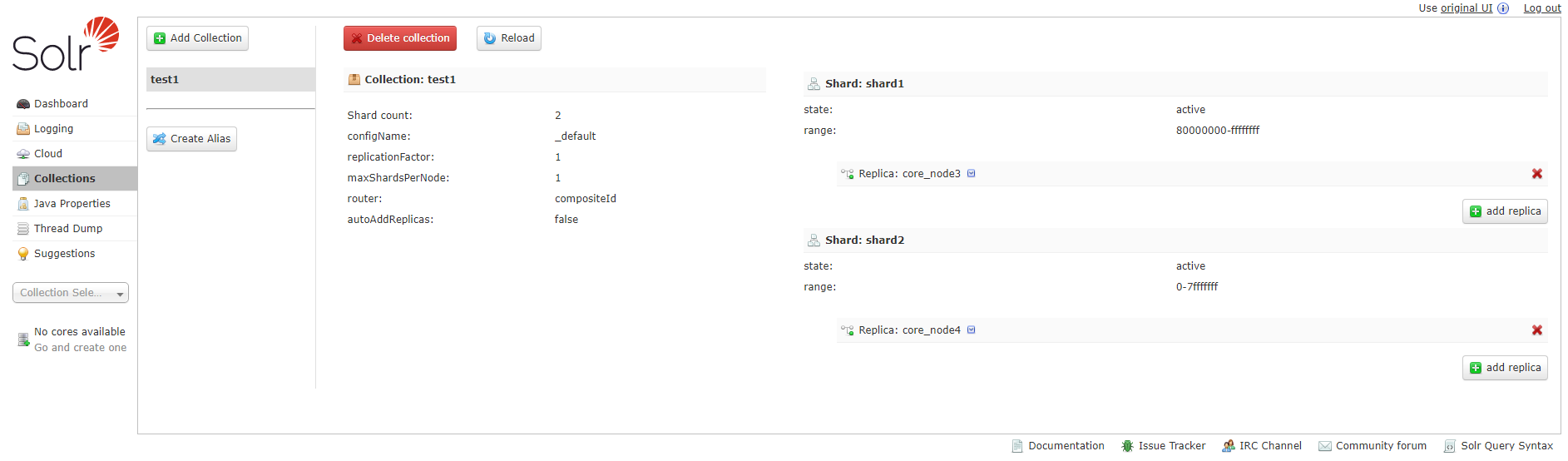
- Index name and replica name: Log in to the Solr Admin page as a service user. In the navigation pane on the left, choose Collections to view the index name (Collection) and replica name (Replica).
- The HDFS recycle bin creates a new checkpoint directory after the previous checkpoint and copies the data in the recycle bin to the new checkpoint directory. If HDFS creates a new checkpoint directory during Solr index data restoration, index data restoration may fail. To prevent this problem, increase the value of fs.trash.checkpoint.interval of HDFS to reduce the frequency of creating checkpoints.
- On FusionInsight Manager, choose Cluster > Services > Solr, click Start Service, and wait until the service is started.
Parent topic: Common Service Operations About Solr
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
The system is busy. Please try again later.
For any further questions, feel free to contact us through the chatbot.
Chatbot



