
O que fazer se a inicialização do contêiner falhar?
Localização de falha
Na página de detalhes de uma carga de trabalho, se um evento for exibido indicando que o contêiner não foi iniciado, execute as seguintes etapas para localizar a falha:
- Efetue logon no nó onde a carga de trabalho anormal está localizada.
- Verifique o ID do contêiner onde o pod de carga de trabalho sai de forma anormal.
docker ps -a | grep $podName
- Visualize os logs do contêiner correspondente.
docker logs $containerID
Corrija a falha da carga de trabalho com base em logs.
- Verifique os logs de erros.
cat /var/log/messages | grep $containerID | grep oom
Verifique se OOM do sistema é acionado com base nos logs.
Processo de solução de problemas
Determine a causa com base nas informações do evento, conforme listado em Tabela 1.
| Log ou evento | Causa e solução |
|---|---|
| O log contém exit(0). | Não existe nenhum processo no contêiner. Verifique se o contêiner está funcionando corretamente. Item de verificação 1: se há processos que continuam em execução no contêiner (Código de saída: 0) |
| Informações do evento: Liveness probe failed: Get http... O log contém exit(137). | Falhas da verificação de integridade. Item de verificação 2: se a verificação de integridade não é realizada (Código de saída: 137) |
| Informações do evento: Thin Pool has 15991 free data blocks which are less than minimum required 16383 free data blocks. Crie mais espaço livre no thin pool ou use a opção dm.min_free_space para alterar o comportamento | O espaço de disco é insuficiente. Limpe o espaço de disco. Item de verificação 3: se o espaço em disco do contêiner é insuficiente |
| A palavra-chave OOM existe no log. | A memória é insuficiente. Item de verificação 4: se o limite superior dos recursos do contêiner foi atingido Item de verificação 5: se os limites de recursos são definidos incorretamente para o contêiner |
| Endereço já em uso | Ocorre um conflito entre as portas de contêiner no pod. Item de verificação 6: se as portas de contêiner no mesmo pod conflito uns com os outros |
Além das possíveis causas anteriores, existem outras três possíveis causas:
- Item de verificação 7: se o comando de inicialização do contêiner está configurado corretamente
- Item de verificação 8: se a versão da sonda de Java é a mais recente
- Item de verificação 9: se o serviço de usuário tem um bug
- Use a imagem correta ao criar uma carga de trabalho em um nó de braço.
Item de verificação 1: se há processos que continuam em execução no contêiner (Código de saída: 0)
- Efetue logon no nó onde a carga de trabalho anormal está localizada.
- Exiba o status do contêiner.
docker ps -a | grep $podName
Exemplo:

Se nenhum processo em execução existir no contêiner, o código de status Exited (0) será exibido.
Item de verificação 2: se a verificação de integridade não é realizada (Código de saída: 137)
A verificação de integridade configurada para uma carga de trabalho é executada nos serviços periodicamente. Se ocorrer uma exceção, o pod relata um evento e o pod não será reiniciado.
Se a verificação de integridade do tipo vivacidade (sonda de vivacidade da carga de trabalho) estiver configurada para a carga de trabalho e o número de falhas na verificação de integridade exceder o limite, os contêineres no pod serão reiniciados. Na página de detalhes da carga de trabalho, se os eventos do Kubernetes contiverem Liveness probe failed: Get http..., a verificação de integridade falha.
Solução
Na página de detalhes da carga de trabalho, selecione Upgrade > Advanced Settings > Health Check para verificar se a política de verificação de integridade está definida corretamente e se os serviços estão normais.
Item de verificação 3: se o espaço em disco do contêiner é insuficiente
A mensagem a seguir se refere ao disco do Thin Pool que é alocado do disco de Docker selecionado durante a criação do nó. Você pode executar o comando lvs como usuário root para exibir o uso atual do disco.
Thin Pool has 15991 free data blocks which are less than minimum required 16383 free data blocks. Create more free space in thin pool or use dm.min_free_space option to change behavior

Solução
Solução 1
Você pode executar o seguinte comando para limpar as imagens indesejadas não utilizadas:
docker system prune -a
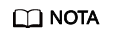
Esse comando excluirá todas as imagens do Docker que não forem usadas temporariamente. Tenha cuidado ao executar este comando.
Solução 2
Como alternativa, você pode expandir a capacidade do disco. O procedimento é o seguinte:
- Expanda a capacidade de um disco de dados no console do EVS. Para obter detalhes, consulte Expansão da capacidade de disco do EVS.
Somente a capacidade de armazenamento do disco EVS é expandida. Você também precisa executar as etapas a seguir para expandir a capacidade do volume lógico e do sistema de arquivos.
- Efetue logon no console do CCE e clique no cluster. No painel de navegação, escolha Nodes. Clique em More > Sync Server Data na linha que contém o nó de destino.
- Faça logon no nó de destino.
- Execute o comando lsblk para verificar as informações do dispositivo de bloco do nó.
Um disco de dados é dividido dependendo do armazenamento do contêiner Rootfs:
Overlayfs: nenhum thin pool independente é alocado. Os dados da imagem são armazenados no dockersys.
- Verifique os tamanhos do disco e da partição do dispositivo.
# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 50G 0 disk └─sda1 8:1 0 50G 0 part / sdb 8:16 0 150G 0 disk # The data disk has been expanded to 150 GiB, but 50 GiB space is not allocated. ├─vgpaas-dockersys 253:0 0 90G 0 lvm /var/lib/containerd └─vgpaas-kubernetes 253:1 0 10G 0 lvm /mnt/paas/kubernetes/kubelet
- Expanda a capacidade do disco.
Adicione a nova capacidade de disco ao volume lógico dockersys usado pelo mecanismo de contêiner.
- Expanda a capacidade do PV para que o LVM possa identificar a nova capacidade do EVS. /dev/sdb especifica o volume físico onde o dockersys está localizado.
pvresize /dev/sdbInformação semelhante à seguinte é exibida:
Physical volume "/dev/sdb" changed 1 physical volume(s) resized or updated / 0 physical volume(s) not resized
- Expanda 100% da capacidade livre para o volume lógico. vgpaas/dockersys especifica o volume lógico usado pelo mecanismo de contêiner.
lvextend -l+100%FREE -n vgpaas/dockersysInformação semelhante à seguinte é exibida:
Size of logical volume vgpaas/dockersys changed from <90.00 GiB (23039 extents) to 140.00 GiB (35840 extents). Logical volume vgpaas/dockersys successfully resized.
- Ajuste o tamanho do sistema de arquivos. /dev/vgpaas/dockersys especifica o caminho do sistema de arquivos do mecanismo de contêiner.
resize2fs /dev/vgpaas/dockersysInformação semelhante à seguinte é exibida:
Filesystem at /dev/vgpaas/dockersys is mounted on /var/lib/containerd; on-line resizing required old_desc_blocks = 12, new_desc_blocks = 18 The filesystem on /dev/vgpaas/dockersys is now 36700160 blocks long.
- Expanda a capacidade do PV para que o LVM possa identificar a nova capacidade do EVS. /dev/sdb especifica o volume físico onde o dockersys está localizado.
- Verifique se a capacidade está expandida.
# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 50G 0 disk └─sda1 8:1 0 50G 0 part / sdb 8:16 0 150G 0 disk ├─vgpaas-dockersys 253:0 0 140G 0 lvm /var/lib/containerd └─vgpaas-kubernetes 253:1 0 10G 0 lvm /mnt/paas/kubernetes/kubelet
- Verifique os tamanhos do disco e da partição do dispositivo.
Item de verificação 4: se o limite superior dos recursos do contêiner foi atingido
Se o limite superior de recursos do contêiner tiver sido atingido, OOM será exibido nos detalhes do evento, bem como no log:
cat /var/log/messages | grep 96feb0a425d6 | grep oom

Quando uma carga de trabalho é criada, se os recursos solicitados excederem o limite superior configurado, OOM do sistema é acionado e o contêiner é encerrado inesperadamente.
Item de verificação 5: se os limites de recursos são definidos incorretamente para o contêiner
Se os limites de recursos definidos para o contêiner durante a criação da carga de trabalho forem menores do que o necessário, o contêiner não será reiniciado.
Item de verificação 6: se as portas de contêiner no mesmo pod conflito uns com os outros
- Efetue logon no nó onde a carga de trabalho anormal está localizada.
- Verifique o ID do contêiner onde o pod de carga de trabalho sai de forma anormal.
docker ps -a | grep $podName
- Visualize os logs do contêiner correspondente.
docker logs $containerID
Corrija a falha da carga de trabalho com base em logs. Como mostrado na figura a seguir, as portas de contêiner no mesmo pod estão em conflito. Como resultado, o contêiner não pode ser iniciado.
Figura 2 Falha na reinicialização do contêiner devido a um conflito de porta de contêiner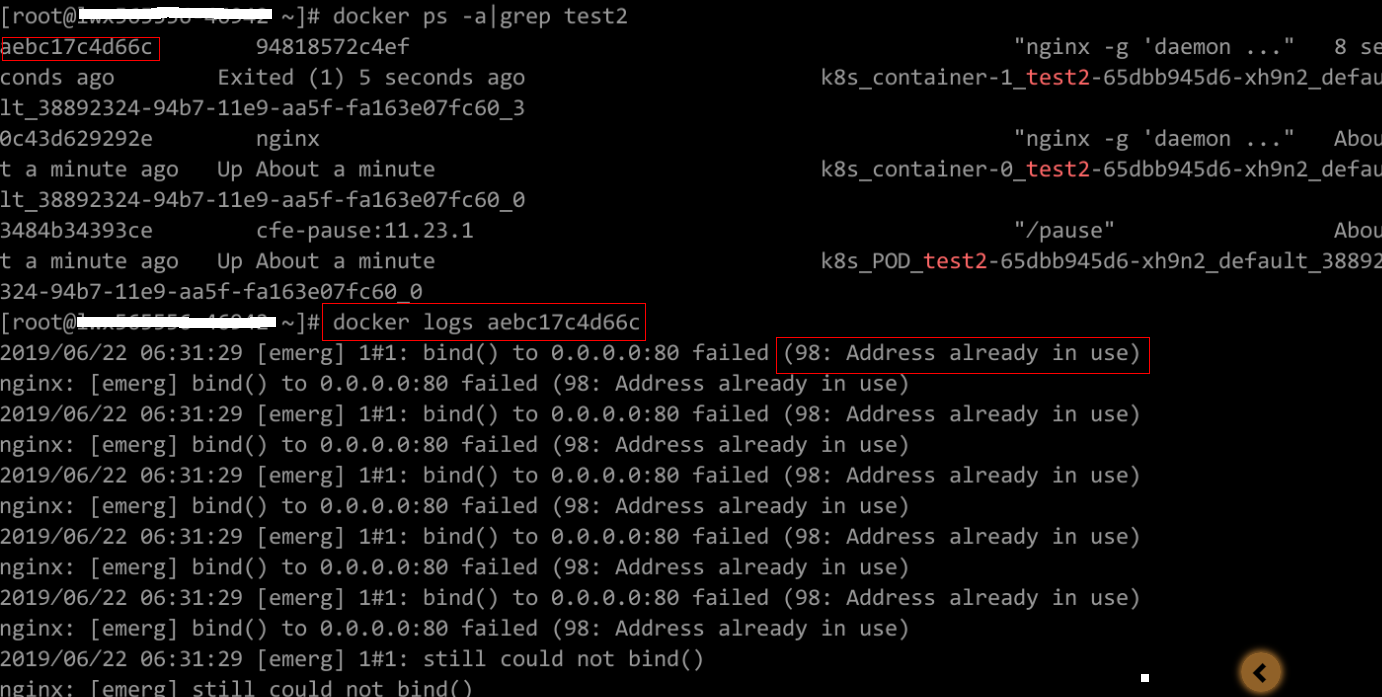
Solução
Recrie a carga de trabalho e defina um número de porta que não seja usado por nenhum outro pod.
Item de verificação 7: se o comando de inicialização do contêiner está configurado corretamente
As mensagens de erro são as seguintes:
Solução
Efetue logon no console do CCE. Na página de detalhes da carga de trabalho, escolha Upgrade > Advanced Settings > Lifecycle para verificar se o comando startup está configurado corretamente.
Item de verificação 8: se a versão da sonda de Java é a mais recente
O evento de Kubernetes "Created container init-pinpoint" ocorre.
Solução
- Ao criar uma carga de trabalho, selecione a última versão específica da sonda de Java (por exemplo, 1.0.36, não a opção latest) na guia APM Settings na área Advanced Settings.
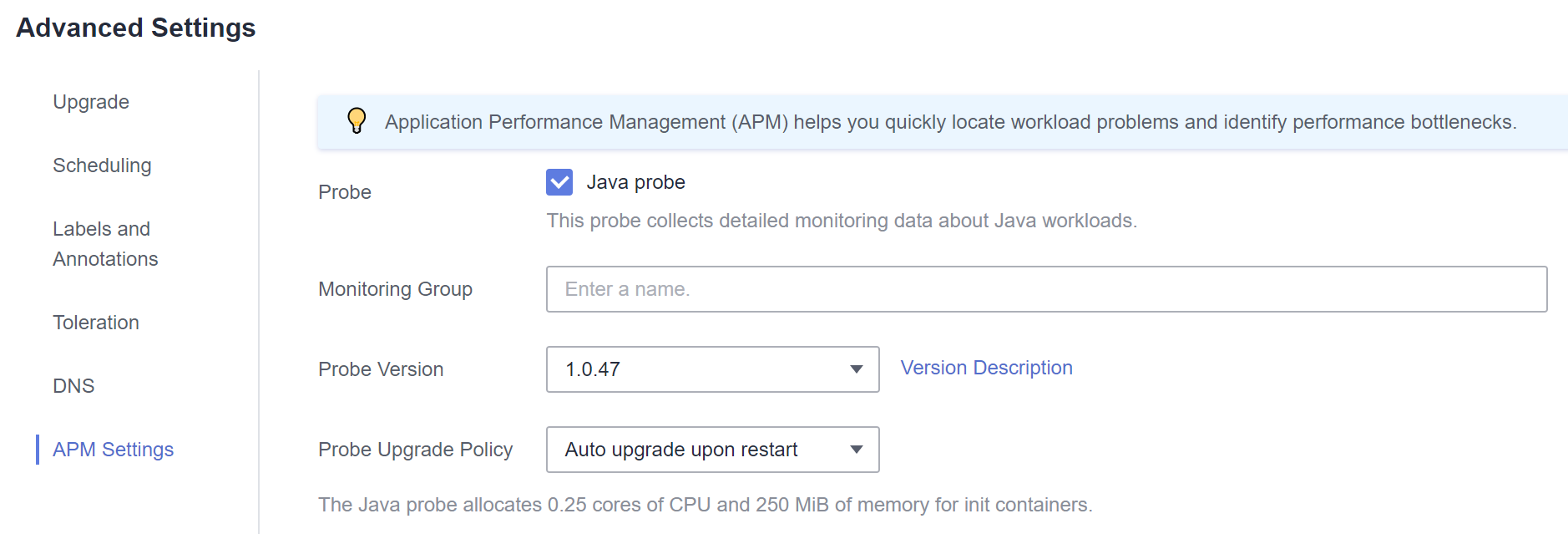
- Se você selecionou latest para a sonda de Java durante a criação da carga de trabalho, poderá fazer upgrade da carga de trabalho e alterá-la para a versão mais recente específica (por exemplo, 1.0.36).
Item de verificação 9: se o serviço de usuário tem um bug
Verifique se o comando de inicialização da carga de trabalho foi executado corretamente ou se a carga de trabalho tem um bug.
- Efetue logon no nó onde a carga de trabalho anormal está localizada.
- Verifique o ID do contêiner onde o pod de carga de trabalho sai de forma anormal.
docker ps -a | grep $podName
- Visualize os logs do contêiner correspondente.
docker logs $containerID
Observação: no comando anterior, containerID indica o ID do contêiner que saiu.
Figura 3 Comando de inicialização incorreto do contêiner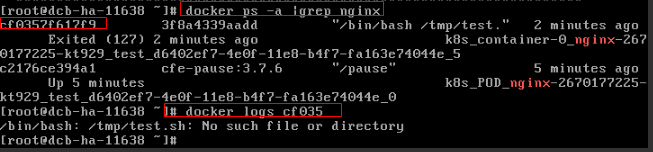
Como mostrado na figura acima, o contêiner falha ao ser iniciado devido a um comando de inicialização incorreto. Para outros erros, corrija os bugs com base nos logs.
Solução
Crie uma nova carga de trabalho e configure um comando de inicialização correto.




