
Availability and SLO
Availability comprehensively measures reliability and resilience.
Availability is the percentage of time (such as 99.9%) services are up over a certain period of time (typically a month or year).
Availability = Available for use time/Total time x 100%
Availability is typically represented by a number of 9s or a combination of 9s and 5s. For instance, three 9s indicate an availability of 99.9%, while three 9s and one 5 indicates an availability of 99.95%.
The system availability objective is defined by a service level objective (SLO). Different application systems have different availability objectives. Defining the objectives is essential for assessing the resilience of an application system. The following table describes the SLOs of common IT systems:
|
SLO |
Maximum Unavailability (per Year) |
Typical IT Services |
|---|---|---|
|
99% |
3.65 days |
Batch processing, background tasks, and data extraction |
|
99.9% |
8.76 hours |
Internal knowledge management systems and project tracking systems |
|
99.95% |
4.38 hours |
Customer account management services and information management services |
|
99.99% |
52.56 minutes |
E-commerce, B2B web services, and heavy-traffic media/content websites |
|
99.999% |
5.26 minutes |
Banking, investment, finance, government, telecoms, and critical enterprise applications |
The system availability depends on the availability of each service unit in the system. There are two typical reliability models for service units:
- Serial model: If any unit fails, the entire system fails.
Mathematical model for reliability:
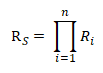
For example, if a system consists of two units connected in series, each with an availability of 99.9%, the system's overall availability is calculated as follows: Rs = 99.9% × 99.9% = 99.8%.
The availability of the serial system is lower than that of a single unit in the system. To improve the system availability:
- Minimize the number of units in the system.
- Improve the availability of each unit. Reduce their failure rates as much as possible.
- Parallel model: The system only fails if all of the units it comprises fail.


Mathematical model for reliability: 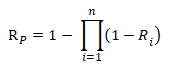
For example, if a system consists of two units connected in parallel, each with an availability of 99.9%, the system's overall availability is calculated as follows: Rs = 1 – (1 – 99.9%) x (1 – 99.9%) = 99.9999%.
Parallel connections can greatly enhance system availability. Common parallel technologies include active/standby, clusters, active-active, and multi-active setups.
To achieve an application system's availability objectives, you need to systematically define the availability requirements for its components and dependent components.
- Availability requirements for dependent components: The SLO of key dependent components should be one 9 higher than that of other services. For instance, if an application system's SLO is 99.9%, its key dependent components must achieve an SLO of 99.99%.
- Breakdown of the application system SLO : Break down the system SLO, fault frequency, and cloud service SLA to determine how long application components can tolerate an interruption. Then, further break down these requirements to establish fault detection, manual intervention, and recovery time targets.
- Enhancement of weak links in the application system:
- If the cloud service SLA is insufficient, strengthen protection and enhancements at the application layer.
- Enhance availability with component redundancy and fail-back mechanisms. For example, set up an ELB cluster to add redundancy for ELB, and configure the system to fail back temporarily to SMN if there is ever a problem with DMS access.
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



