
Creating a CDL Job
Scenario
This section describes how to submit jobs using the CDLService web UI.
A CDL job consists of two parts: Sink Connector and Source Connector. Connectors contain the link concept independently. Therefore, the process of creating a CDL job is as follows:
- Verify a link.
- Create a link.
- Create a job (including the configurations of two Connectors).
- Submit the job.

- If the default domain name of the cluster is not hadoop.hadoop.com, add the following parameters to the Connector parameters of the created job. xxx.xxx.xxx indicates the actual domain name.
{"name" : "producer.override.kerberos.domain.name", "value" : "xxx.xxx.xxx"}
{"name" : "consumer.override.kerberos.domain.name", "value" : "xxx.xxx.xxx"}
- After a job is created, it is not automatically executed. Connectors are created only after the job is submitted manually. For details about the APIs used for creating a job, see Common CDL Service APIs.
- CDL cannot fetch tables whose names contain the dollar sign ($).
{
"job_type": "CDL_JOB", // Job type. Currently, only CDL_JOB is supported.
"name": "CDCMRSPGSQLJOB", // Job name
"description":"CDC MRS postgres Job", // Job description
"from-link-name": "postgresMRS", // Data source link
"to-link-name": "HDFSPOSTGRESMRSConnection", // Target source link
"from-config-values": {
// Source Connector configuration. For details, see the input parameters in "Common CDL Service APIs".
{"name" : "topic.table.mapping", "value" : "[{\"topicName\": \"perf_test1\",\"tableName\": \"TESTMYSQL10\"},{\"topicName\": \"perf_test1\",\"tableName\": \"TESTMYSQL11\"}]"},// Topic mapping configuration, which is used to set the mapping between tables and topics and specify the topic to which data in a table is sent.
},
"to-config-values": {
// Sink Connector configuration. For details, see the input parameters in "Common CDL Service APIs".
{"name" : "topics", "value" : "kris_topic_t1,perf_test1,perf_test1"},// Specify the topics consumed by the Sink Connector.
},
"job-config-values": {
"inputs": [
{"name" : "global.topic", "value" : "cdcmrspgsqltopic"} // Store the topic of the captured data.
]
}
All CDL jobs must be created by following the preceding steps. This section uses the data capture path from MySQL to Kafka as an example. For other paths, obtain specific parameters by referring to Common CDL Service APIs.
Prerequisites
- Binary logging has been enabled for MySQL.
- The MySQL driver JAR file has been uploaded to all dbDriver folders in all node installation directories of CDL. Pay attention to the file permission.

Procedure
- In the CLI, enter the commands in the following figure to verify the MySQL link and click Send. If SUCCESS is displayed, the verification is successful.
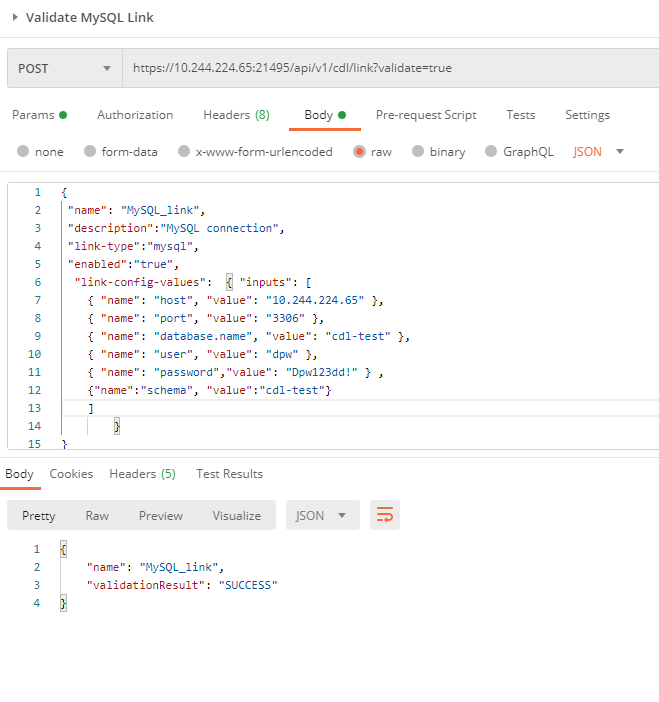
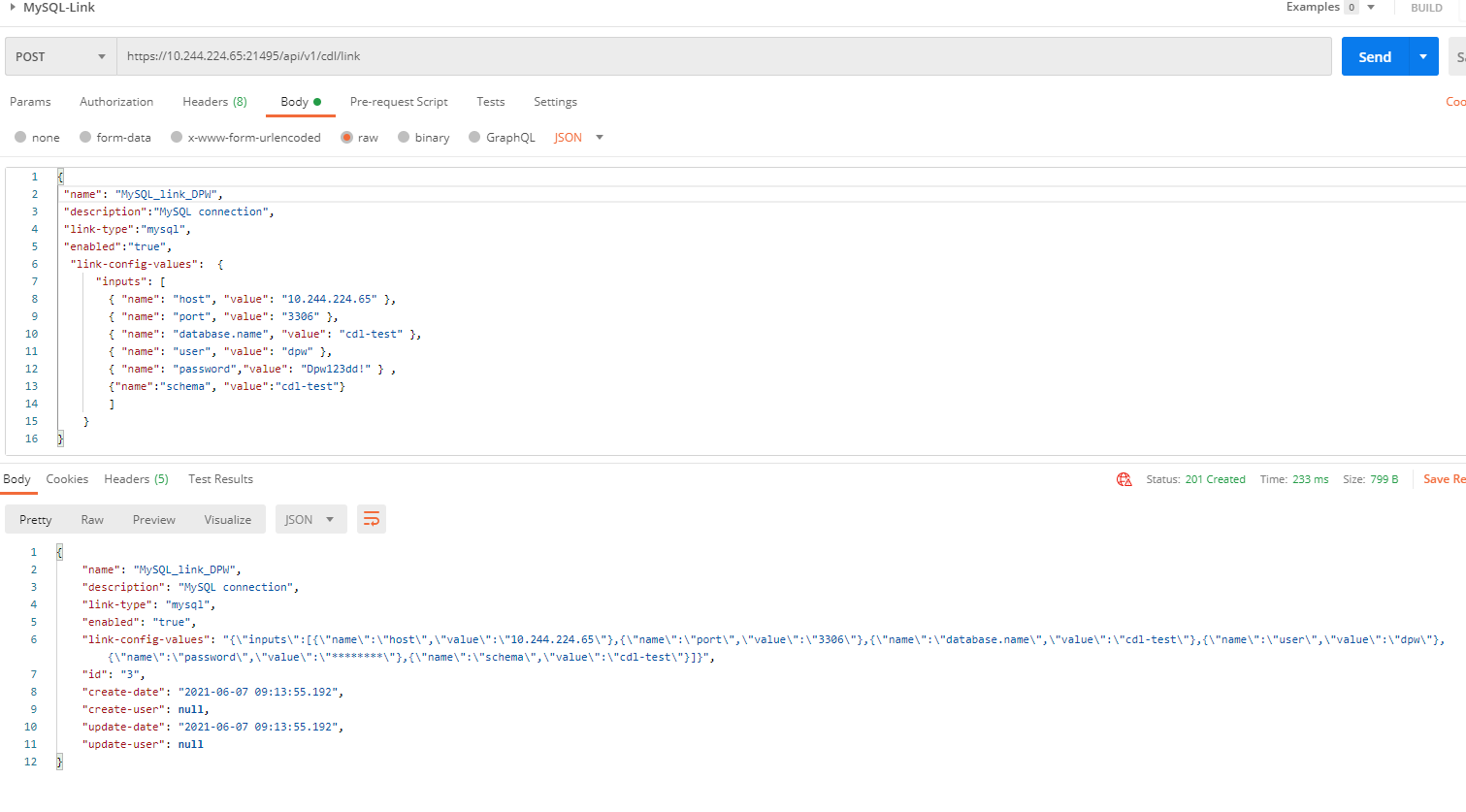
- Create a MySQL link by referring to the commands in the following figure.
- In the CLI, enter the commands in the following figure to verify the Kafka link and click Send. If SUCCESS is displayed, the verification is successful.
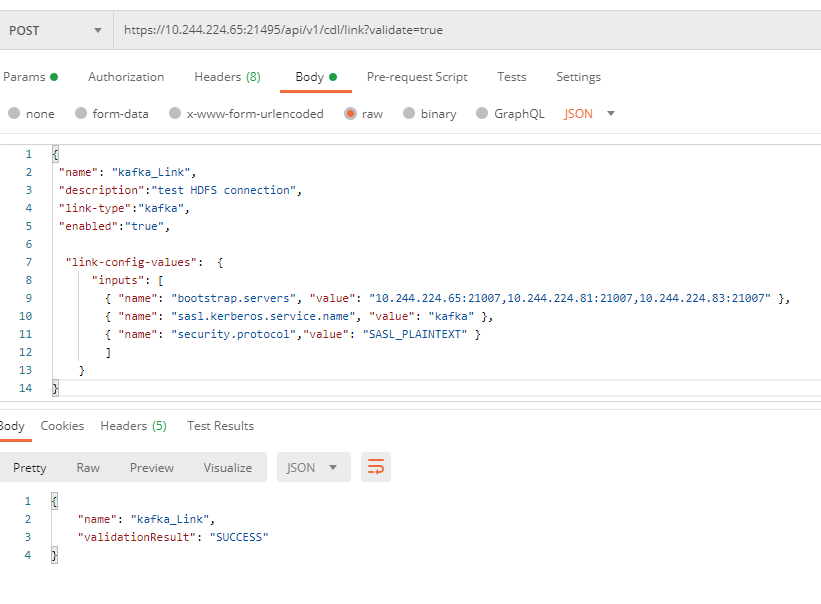
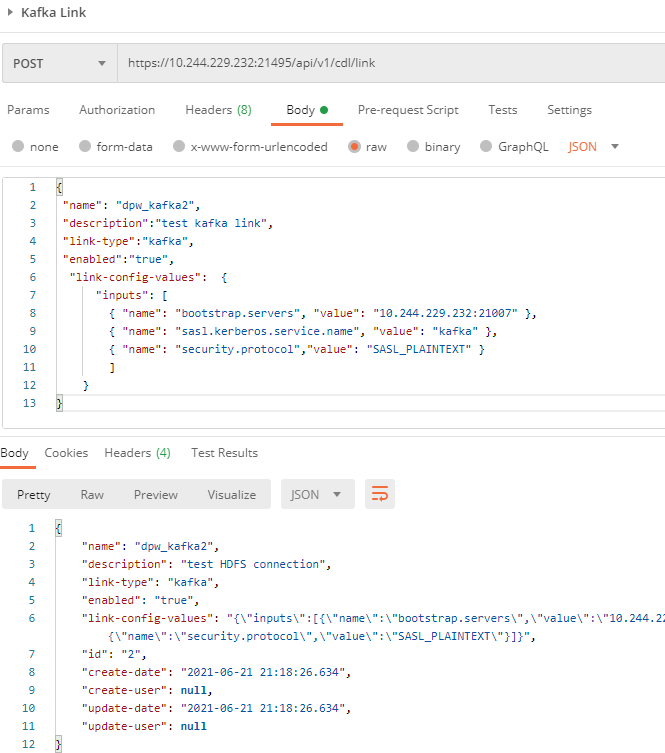
- Create a Kafka link by referring to the commands in the following figure.
- Create a job by referring to the commands in the following figure.
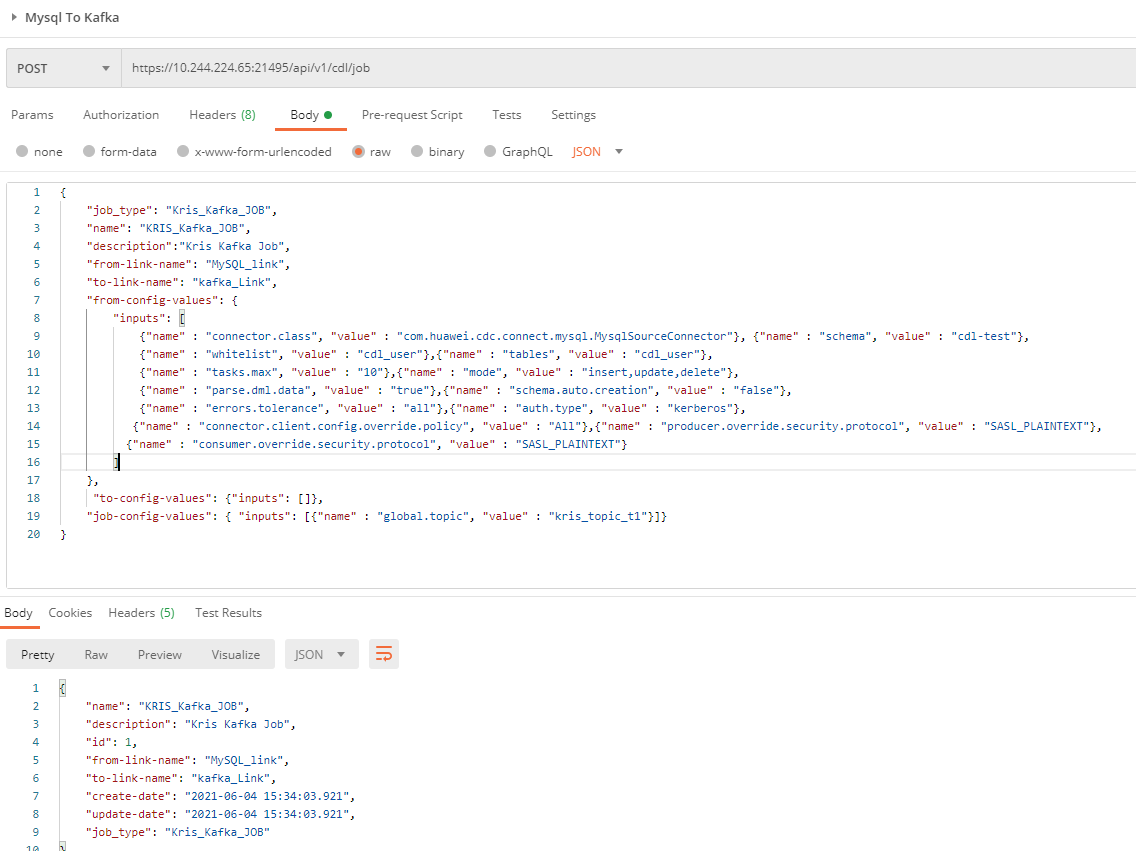
- Submit the job by referring to the commands in the following figure.
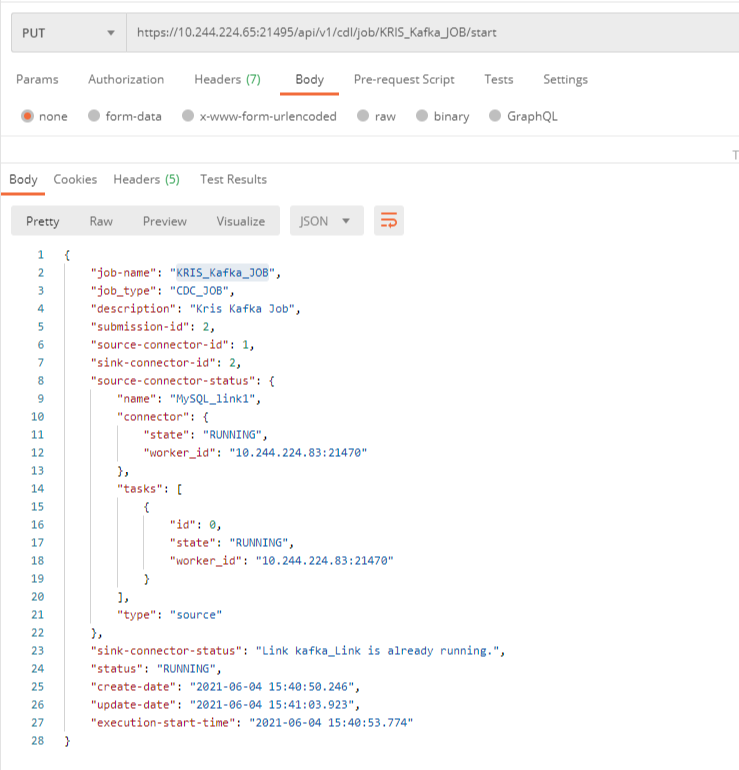
- After the job is submitted successfully, you can capture data, perform operations on the tables in the corresponding database, and check whether the topic contains data.
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



