
What Should I Do If a Hudi Read Job Is in the Booting State for a Long Time?
Cause 1: Except for the problems with the resources of the Yarn queue, jobs are suspended when Spark SQL is executed to read Hudi and write Hive temporary tables. The execution speed depends on the data volume of the Hudi table and the remaining resources of the Yarn queue.
Troubleshooting 1: Search for Yarn tasks of Spark JDBC Server and find tasks whose Running Containers are more than 1 in the queue. View ApplicationMaster and click the SQL tab to view the SQL statements that are being executed. Click the Stages tab to view the execution progress of each SQL statement.

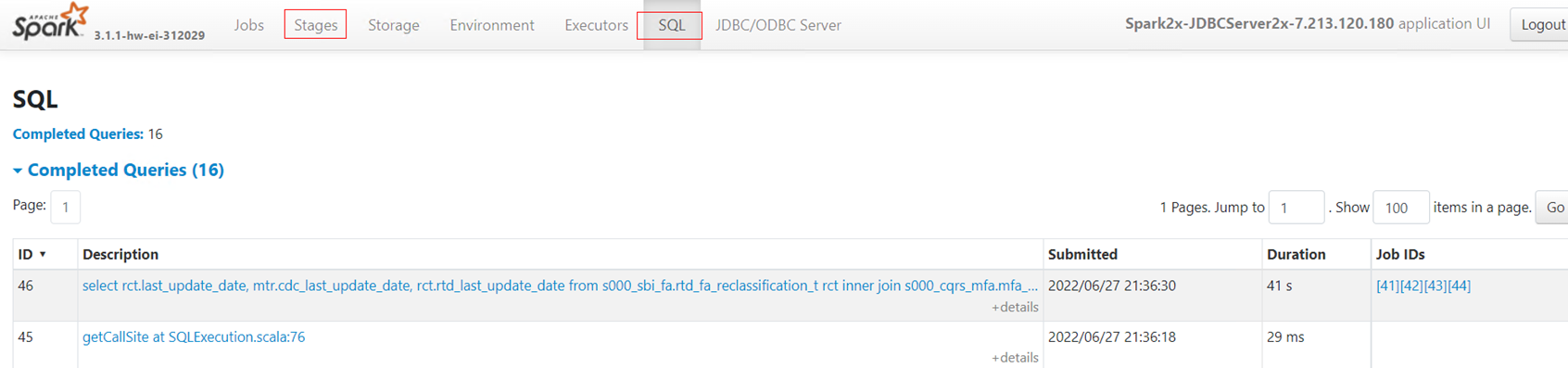
When the job is in booting status, its logs cannot be viewed. If you cannot find Yarn tasks, contact CDM O&M engineers to view background logs and obtain the application ID. The following figure shows an example log.

Cause 2: Clear Data Before Import is enabled for the job. As the DWS table contains a large amount of inventory data, the job is stuck in the truncate table operation and times out after 5 minutes by default.
Troubleshooting 2: Contact CDM O&M engineers to view background logs.
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



