
Configuring Supernode Affinity Group Instances
Description
In foundation model training, multiple parallel strategies boost efficiency and scalability using distributed computing. Model parallelism uses AllReduce communication, while MoE expert parallelism uses all-to-all communication. Both require high network bandwidth between processing units (PUs). These communication steps often become bottlenecks due to hardware limitations, limiting training performance.
Snt9b23 uses the HCCS bus to connect NPUs across multiple compute nodes, creating supernodes. Within each supernode, a fully interconnected network known as a superplane enhances AI task communication. With supernode hardware, models can adjust parallel strategies like model parallelism or MoE expert parallelism to speed up training with higher bandwidth.
ModelArts provides a supernode affinity feature that acts as a scheduling policy. This feature organizes AI training jobs to align with the hardware network of compute resources, maximizing the high bandwidth and low latency of supernodes for better training efficiency. Algorithm engineers can effortlessly use supernode hardware through simple setups.
Principles
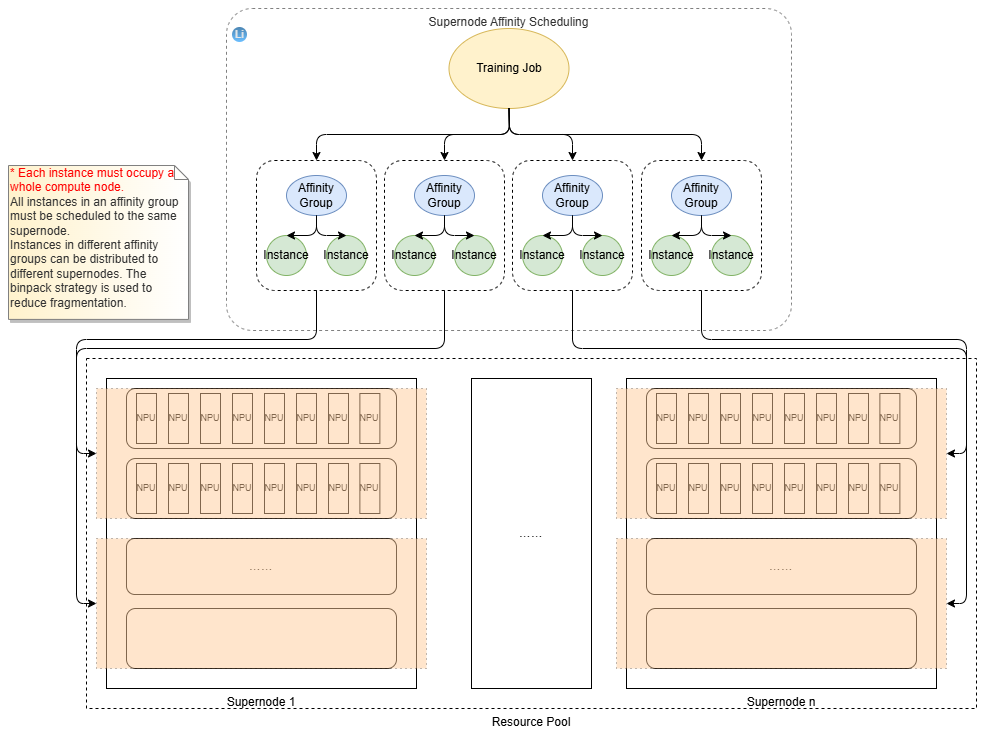
The figure shows that each task in a training job is referred to as an instance. ModelArts uses affinity groups to schedule training jobs on supernodes and maximize their ultra-high bandwidth. An affinity group is a group of instances that you want to connect through a hyperplane in a training job. Instances in the same affinity group run on the same supernode.

To boost training efficiency, place PUs that need high bandwidth in the same affinity group.
For Tensor Parallelism (TP), in older hardware, TP is often set to 8, linking eight PUs per node with HCCS. In supernodes, more PUs connect via HCCS, allowing for larger TP domains.
Prerequisite: In distributed training, each instance must use all PUs on the node.
If TP is 32, then 32 PUs form one TP domain, and each node has 16 PUs. Here, two instances must share the same supernode, forming an affinity group.
You only need to set the new parameter Supernode Affinity Group Instances to 2 when creating a training job.
The training job runs only if the resource pool's available supernodes meet these conditions:
If the training job needs eight instances, with Supernode Affinity Group Instances set to 2. Here are the available resources:
- Resource pool A
Supernode 1: maximum nodes: 8; available nodes: 6
Supernode 2: maximum nodes: 8; available nodes: 2
- Resource pool B
Supernode 3: maximum nodes: 8; available nodes: 7
Supernode 4: maximum nodes: 8; available nodes: 1
Both pools have eight available nodes, meeting the first condition. However, supernode 3 in pool B can allocate three affinity groups, while supernode 4 can allocate none. The second condition is not met. Thus, only pool A can run the training job. If the job goes to pool B, it will wait in the queue due to insufficient resources.
Constraints
- The affinity group feature only works with dedicated resource pools that have Ascend Snt9b23 supernodes.
- In distributed training, each instance must use all PUs on the node.
- The affinity group feature only supports resource pools with single-step specifications; it does not support resource pools with multi-step specifications.
Configuration Method
When you create a training job on the ModelArts console, selecting a dedicated resource pool and an Snt9b23 flavor allows you to set Supernode Affinity Group Instances during Step 5: Configuring Resources.
Notes for setting Supernode Affinity Group Instances:
- The default value is 1, and the maximum value cannot exceed the maximum number of nodes on a single supernode.
- You must set the number of instances as an integral multiple of Supernode Affinity Group Instances. Otherwise, the training job cannot be created.
- After choosing a dedicated resource pool, you can check its supernode specifications, like total nodes, total PUs, available nodes, and available PUs. This helps you decide on Supernode Affinity Group Instances.
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



