
Realización de un reinicio continuo de un clúster
Escenario
Un reinicio continuo es reiniciar por lotes todos los servicios de un clúster después de que se modifiquen o actualicen sin interrumpir las cargas de trabajo.
Puede realizar un reinicio continuo de un clúster según sea necesario.

- Algunos servicios de un clúster no admiten el reinicio continuo. Estos servicios se reinician en modo normal durante el reinicio continuo del clúster. Como resultado, las cargas de trabajo pueden interrumpirse. Por lo tanto, debe determinar si se debe realizar esta operación como se le solicite.
- Las configuraciones que deben surtir efecto inmediatamente, por ejemplo, las configuraciones de puertos de servidor, deben reiniciarse en modo normal.
Impacto en el sistema
Un reinicio continuo tarda más tiempo y puede afectar el rendimiento y el rendimiento del servicio.
Procedimiento
- Inicie sesión en FusionInsight Manager.
- Elija Cluster > Name of the target cluster > Dashboard. En esta página de pestaña, elija More >Rolling-restart Service.
- En el cuadro de diálogo que se muestra, introduzca la contraseña del usuario de inicio de sesión actual y haga clic en OK.
- Configure los parámetros según los requisitos del sitio. Figura 1 Clúster de reinicio continuo
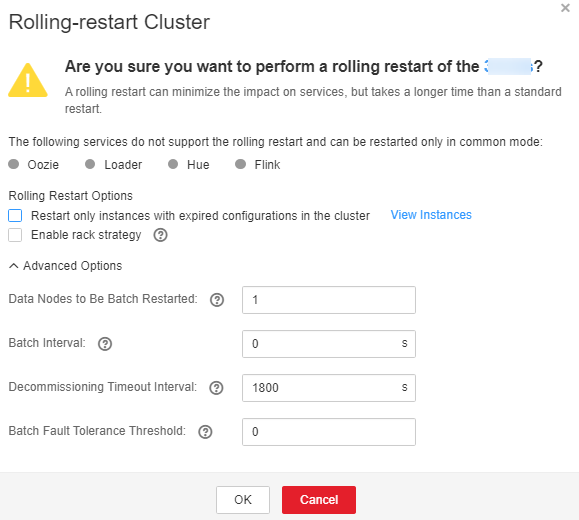
Tabla 1 Parámetros del reinicio secuencial Parámetro
Descripción
Restart only instances with expired configurations in the cluster
Si desea reiniciar solo las instancias modificadas en un clúster
Enable rack strategy
Si se debe habilitar la estrategia de reinicio continuo de rack simultáneos. Este parámetro solo tiene efecto para los roles que cumplen con la estrategia de reinicio continuo de rack. (Los roles admiten el reconocimiento de rack y las instancias de los roles pertenecen a dos o más racks.)
NOTA:Este parámetro es configurable solo cuando se realiza un reinicio continuo en HDFS o YARN.
Data Nodes to Be Batch Restarted
Número de instancias que se reinician en cada lote cuando se utiliza la estrategia de reinicio continuo por lotes. El valor predeterminado es 1.
NOTA:- Este parámetro solo es válido cuando se utiliza la estrategia de reinicio continuo por lotes y el tipo de instancia es de DataNode.
- Este parámetro no es válido cuando se habilita la estrategia de rack. En este caso, el clúster utiliza el número máximo de instancias (20 de forma predeterminada) configuradas en la estrategia de rack como el número máximo de instancias que se reinician simultáneamente en un rack.
- Este parámetro es configurable solo cuando se realiza un reinicio continuo en HDFS, HBase, YARN, Kafka, Storm, o Flume.
- Este parámetro para el RegionServer de HBase no se puede configurar manualmente. En su lugar, se ajusta automáticamente en función del número de nodos de RegionServer. Específicamente, si el número de nodos de RegionServer es menor que 30, el valor del parámetro es de 1. Si el número es mayor o igual que 30 y menor que 300, el valor del parámetro es 2. Si el número es mayor o igual a 300, el valor del parámetro es 1% del número (redondeado hacia abajo).
Batch Interval
Intervalo entre dos lotes de instancias que se van a reiniciar. El valor predeterminado es 0.
Decommissioning Timeout Interval
Intervalo de desmantelamiento para instancias de rol durante un reinicio continuo. El valor predeterminado es 1800s.
Algunos roles (como HiveServer y JDBCServer) dejan de proporcionar servicios antes del reinicio continuo. Las instancias detenidas no se pueden conectar a nuevos clientes. Las conexiones existentes se completarán después de un período de tiempo. Un intervalo de tiempo de espera adecuado puede garantizar la continuidad del servicio.
NOTA:Este parámetro solo se puede configurar cuando se realiza un reinicio continuo en Hive o Spark2x.
Batch Fault Tolerance Threshold
Tiempos de tolerancia cuando el reinicio continuo de las instancias no se ejecuta por lotes. El valor predeterminado es 0, que indica que la tarea de reinicio continuo finaliza después de que cualquier lote de instancias no se reinicie.
Los parámetros avanzados, como Data Nodes to Be Batch Restarted, Batch Interval y Batch Fault Tolerance Threshold deben configurarse correctamente en función de los requisitos del sitio. De lo contrario, los servicios pueden verse interrumpidos o el rendimiento del clúster puede verse gravemente afectado.
Ejemplo:
- Si Data Nodes to Be Batch Restarted se establece en un valor innecesariamente grande, un gran número de instancias se reinician simultáneamente. Como resultado, los servicios se interrumpen o el rendimiento del clúster se ve gravemente afectado debido a que hay muy pocas instancias de trabajo.
- Si Batch Fault Tolerance Threshold es demasiado grande, los servicios se interrumpirán porque el siguiente lote de instancias se reiniciará después de que un lote de instancias no se reinicie.
- Haga clic en OK.




