
Solr Basic Principle
Solr is a high-performance Lucene-based full-text retrieval server. Extended based on Lucene, Solr provides more diversified query languages than Lucene, implements the full-text search function, and supports highlighting display and dynamic clusters, providing high scalability. Solr 4.0 and later versions support the SolrCloud mode. In this mode, centralized configuration, near-real-time search, and automatic fault tolerance functions are supported.
- Uses ZooKeeper as the collaboration service. When ZooKeepers are started, users can specify the related Solr configuration files to be uploaded to the ZooKeepers for multiple machines to share. Configuration in the ZooKeepers will not be cached locally. Solr directly reads the configuration information in the ZooKeepers. Modification of the configuration files will be sensed by all machines.
- Supports automatic fault tolerance. SolrCloud divides a Collection into multiple Shards and creates multiple Replicas for each Shard. After a Replica breaks down, the entire index search service will not be affected. Each Replica can independently provide services to external environments.
- Supports automatic load balancing during indexing and query. The multiple Replicas of a SolrCloud Collection can be distributed on multiple machines to balance the indexing and query pressure. If the indexing and query pressure is huge, users can add machines or Replicas to balance the pressure.
- The Solr index data can be stored in multiple modes. The HDFS can be used as the index file storage system of Solr to provide a high-reliability, high-performance, scalable, and real-time full-text search system. The data can also be stored on local disks for higher data indexing and query speed.
|
Name |
Description |
|---|---|
|
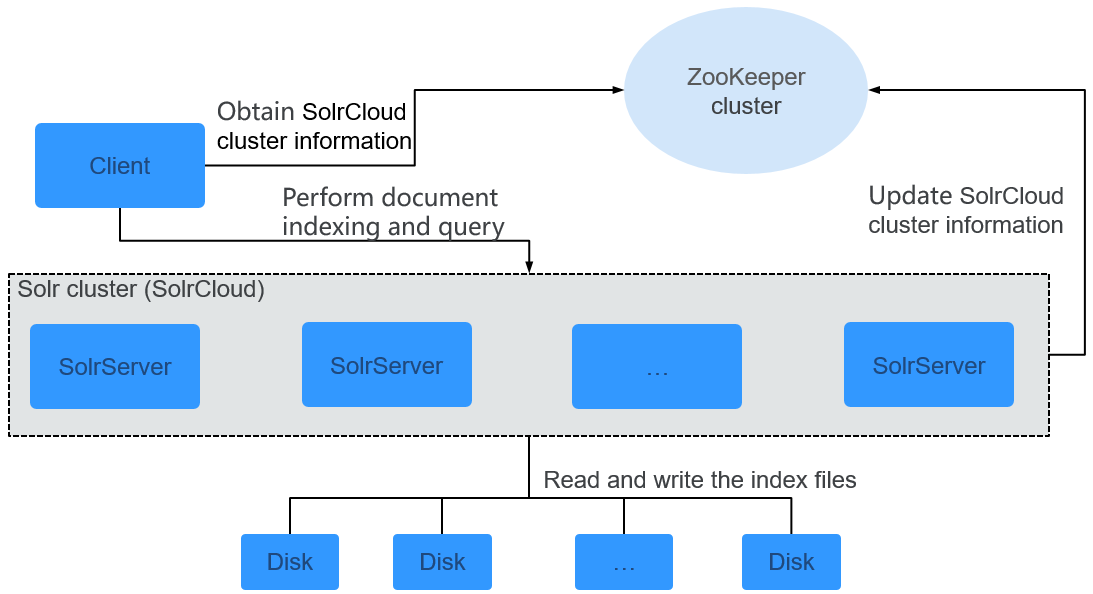
Client |
Client communicates with SolrServer in the Solr cluster (SolrCloud) through the HTTP or HTTPS protocol and performs distributed indexing and distributed search operations. |
|
SolrServer |
SolrServer provides various services, such as index creation and full-text retrieval. It is a data computing and processing unit in the Solr cluster. |
|
ZooKeeper cluster |
ZooKeeper provides distributed coordination services for various processes in the Solr cluster. Each SolrServer registers its information (collection configuration information and SolrServer health information) with ZooKeeper. Based on the information, Client detects the health status of each SolrServer, thereby determining distribution of indexing and search requests. |
Basic Concept
- Collection: a complete logical index in a SolrCloud cluster. A Collection can be divided into multiple Shards that use the same Config Set.
- Config Set: a group of configuration files required by Solr Core to provide services. A Config Set includes solrconfig.xml and managed-schema.
- Core: refers to Solr Core. A Solr instance includes one or multiple Solr Cores. Each Solr Core independently provides indexing and query functions. Each Solr Core corresponds to an index or a Collection Shard Replica.
- Shard: a logical section of a Collection. Each Shard has multiple Replicas, among which a leader is elected.
- Replica: a copy of a Shard. Each Replica is in a Solr Core.
- Leader: a Shard Replica elected from multiple Replicas. When documents are indexed, SolrCloud transfers them to the leader, and the leader distributes them to Replicas of the Shard.
- ZooKeeper: is mandatory in SolrCloud. It provides distributed lock and Leader election functions.
Principle
- Descending-order Indexing
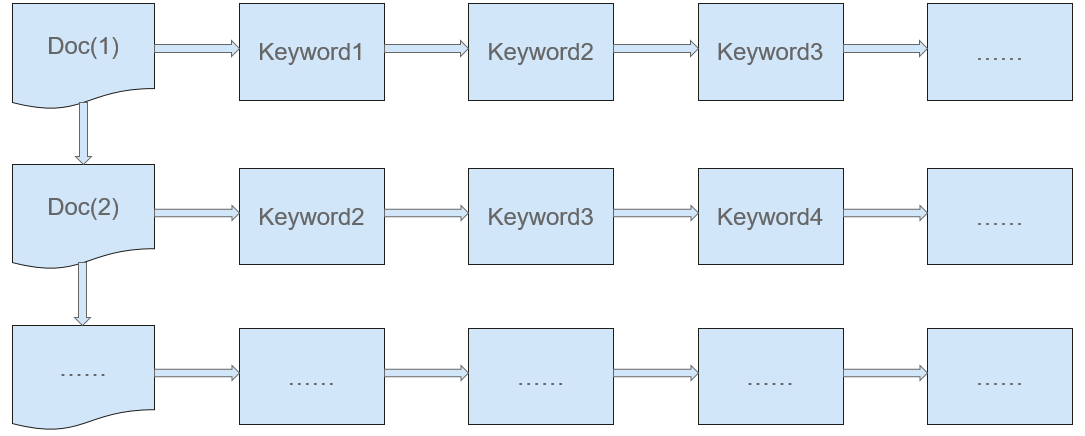
The traditional search (which uses the ascending-order indexing, as shown in Figure 2) starts from keypoints and then uses the keypoints to find the specific information that meets the search criteria. In the traditional mode, values are found according to keys. During search based on the ascending-order indexing, keywords are found by document number.
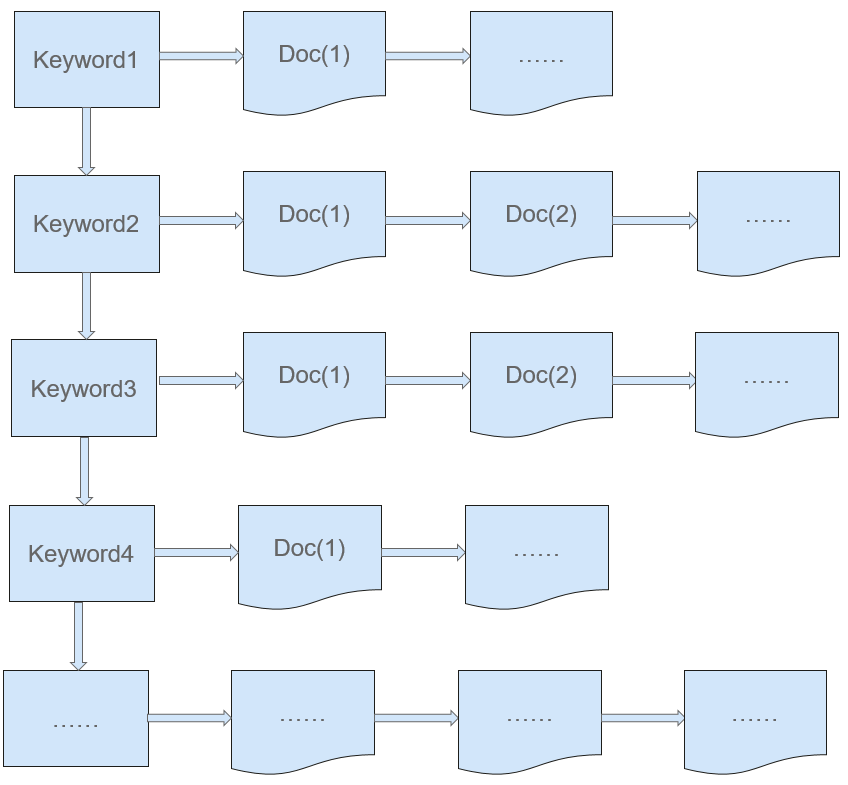
The Solr (Lucene) search uses the descending-order indexing mode (as shown in Figure 3). In this mode, keys are found according to values. Values in the full-text search indicate the keywords that need to be searched. Places where the keywords are stored are called dictionaries. Keys indicate document number lists, with which users can find the documents that contain the search keywords (values), as shown in the following figure. During search based on the descending-order indexing, document numbers are found by keyword and then documents are found by document number.
- Distributed Indexing Operation Procedure
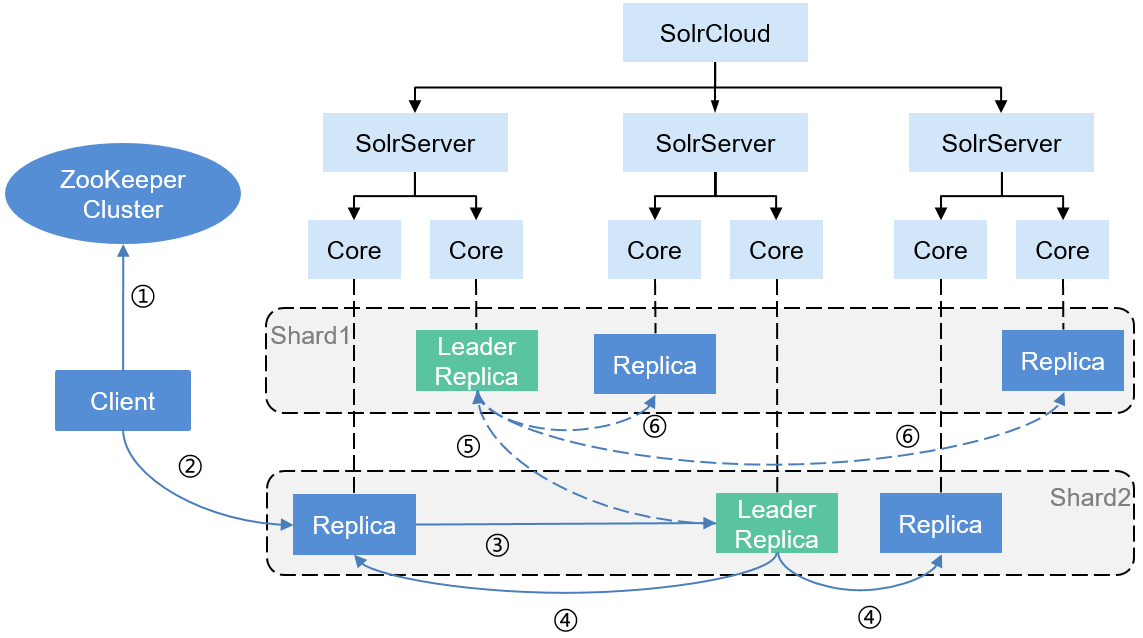
Figure 4 describes the Solr distributed indexing operation procedure.
The procedure is as follows:
- When initiating a document indexing request, the Client obtains the SolrServer cluster information of SolrCloud from the ZooKeeper cluster, and then obtains any SolrServer that contains the Collection information according to the Collection information in the request.
- The Client sends the document indexing request to a Replica of the related Shard in the Collection of the SolrServer.
- If the Replica is not the Leader Replica, the Replica will forward the document indexing request to the Leader Replica in the same Shard.
- After indexing documents locally, the Leader Replica routes the document indexing request to other Replicas for processing.
- If the target Shard of the document indexing is not the Shard of this request, the Leader Replica of the Shard will forward the document indexing request to the Leader Replica of the target Shard.
- After indexing documents locally, the Leader Replica of the target Shard routes the document indexing request to other Replicas of the Shard of the request for processing.
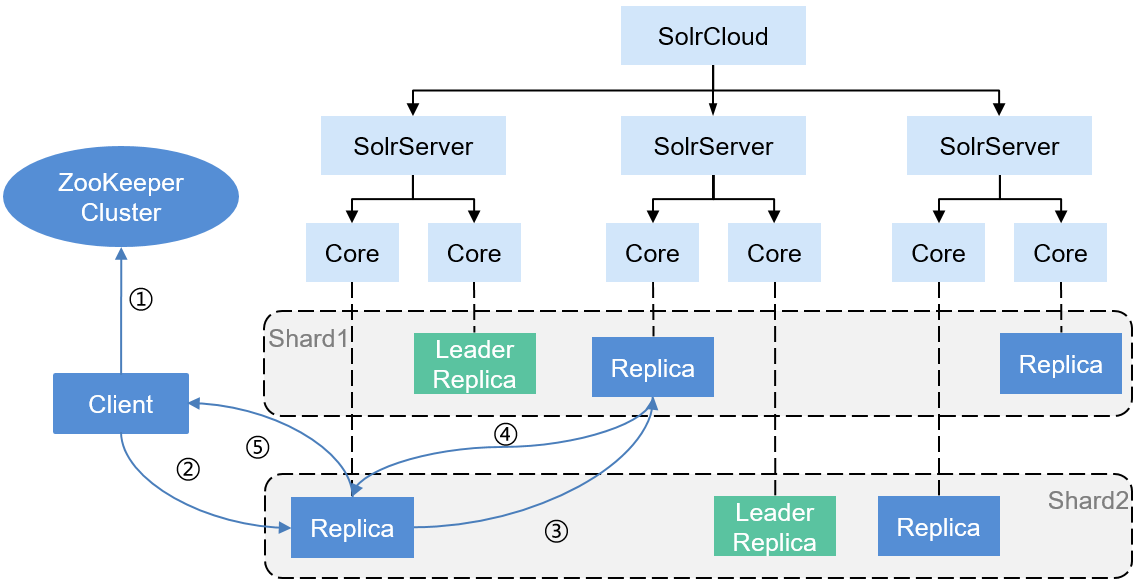
- Distributed Search Operation Procedure
Figure 5 describes the Solr distributed search operation procedure.
The procedure is as follows:
- When initiating a search request, the Client obtains the SolrServer cluster information using ZooKeeper and then randomly selects a SolrServer that contains the Collection.
- The Client sends the search request to any Replica (which does not need to be the Leader Replica) of the related Shard in the Collection of the SolrServer for processing.
- The Replica starts a distributed query, converts the query into multiple subqueries based on the number of Shards of the Collection (there are two Shards in Figure 5, Shard 1 and Shard 2), and distributes each subquery to any Replica (which does not need to be the Leader Replica) of the related Shard for processing.
- After each subquery is completed, the query results are returned.
- After receiving the results of each subquery, the Replicas that receives a query request for the first time combines the query results and then sends the final results to the Client.
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



