
Nuevas características de DCS for Redis 5.0
DCS for Redis 5.0 es compatible con las nuevas características de Redis 5.0 de código abierto, además de todas las mejoras y nuevos comandos de Redis 4.0.
Estructura de datos de flujo
Flujo es un nuevo tipo de datos introducido con Redis 5.0. Soporta persistencia de mensajes y multidifusión.
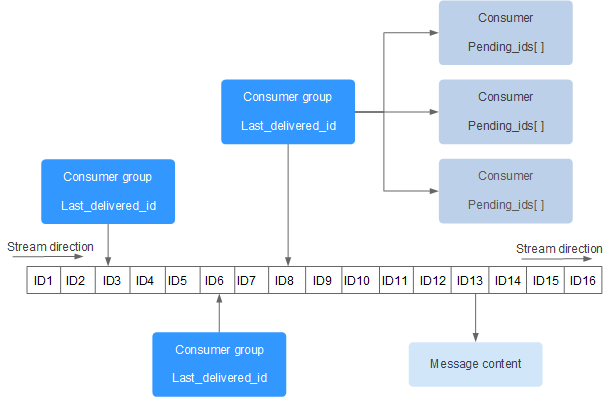
Figura 1 muestra la estructura de un flujo de Redis, que permite que se agregan mensajes al flujo.
- Un flujo puede tener varios grupos de consumidores.
- Cada grupo de consumidores contiene un Last_delivered_id que apunta al último artículo consumido (mensaje) en el grupo de consumidores.
- Cada grupo de consumidores contiene múltiples consumidores. Todos los consumidores comparten el last_delivered_id del grupo de consumidores. Un mensaje puede ser consumido por un solo consumidor.
- pending_ids en el consumidor puede ser utilizado para registrar los ID de los artículos que han sido enviados al cliente, pero no han sido reconocidos.
- Para una comparación detallada entre flujo y otras estructuras de datos de Redis, consulte Tabla 1.
| Concepto | Flujo | List, Pub/Sub, Zset |
|---|---|---|
| Complejidad de buscar artículos | O(log(N)) | List: O(N) |
| Desfase | Admitido. Cada elemento tiene un ID único. El ID no se cambia a medida que se agregan o desalojan otros elementos. | List: no soportado. Si se desaloja un artículo, no se puede localizar el último artículo. |
| Persistencia | Admitido. Flujos se mantienen en archivos de AOF y de RDB. | Pub/Sub: No soportado. |
| Grupo de consumidores | Admitido. | Pub/Sub: No soportado. |
| Confirmación | Admitido. | Pub/Sub: No soportado. |
| Rendimiento | No relacionado con el número de consumidores. | Pub/Sub: Positivamente relacionado con el número de clientes. |
| Desalojo | Flujos son eficientes en la memoria al bloquear para desalojar los datos que son demasiado antiguos y usar un árbol de radix y un paquete de lista. | Zset consume más memoria porque no admite la inserción de los mismos elementos, el bloqueo o la expulsión de datos |
| Eliminación de elementos aleatoria | No se admite. | Zset: Admitido. |
Comandos de flujo
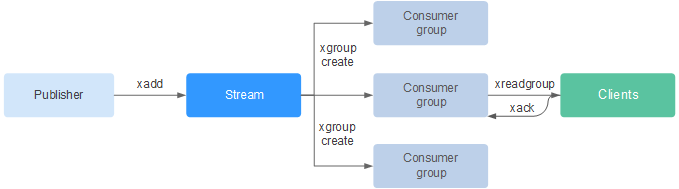
- Ejecute el comando XADD para agregar un elemento de flujo, es decir, crear un flujo. El número máximo de mensajes que se pueden guardar se puede especificar al agregar el elemento.
- Cree un grupo de consumidores ejecutando el comando XGROUP.
- Un consumidor utiliza el comando XREADGROUP para consumir mensajes.
- Después del consumo, el cliente ejecuta el comando XACK para confirmar que el consumo es exitoso.
| Comando | Descripción | Sintaxis |
|---|---|---|
| XACK | Elimina uno o varios mensajes del pending entry list (PEL) de un grupo de consumidores del flujo. | XACK key group ID [ID ...] |
| XADD | Agrega una entrada especificada a flujo en una clave especificada. Si la clave no existe, ejecutar este comando dará como resultado una clave que se creará automáticamente en función de la entrada. | XADD key ID field string [field string ...] |
| XCLAIM | Cambia la propiedad de un mensaje pendiente, de modo que el nuevo propietario sea el consumidor especificado como argumento de comando. | XCLAIM key group consumer min-idle-time ID [ID ...] [IDLE ms] [TIME ms-unix-time] [RETRYCOUNT count] [FORCE] [JUSTID] |
| XDEL | Elimina las entradas especificadas de un flujo y devuelve el número de entradas eliminadas, que puede ser diferente del número de ID pasados al comando en caso de que no existan ciertos ID. | XDEL key ID [ID ...] |
| XGROUP | Gestiona los grupos de consumidores asociados a un flujo. Puede usar XGROUP para:
| XGROUP [CREATE key groupname id-or-$] [SETID key id-or-$] [DESTROY key groupname] [DELCONSUMER key groupname consumername] |
| XINFO | Recupera información diferente sobre los flujos y los grupos de consumidores asociados. | XINFO [CONSUMERS key groupname] key key [HELP] |
| XLEN | Devuelve el número de entradas de un flujo. Si la clave especificada no existe, se devuelve 0, lo que indica una secuencia vacía. | XLEN key |
| XPENDING | Obtiene datos de un flujo a través de un grupo de consumidores. Este comando es la interfaz para inspeccionar la lista de mensajes pendientes con el fin de observar y comprender qué clientes están activos, qué mensajes están pendientes de ser consumidos, o para ver si hay los mensajes inactivos. | XPENDING key group [start end count] [consumer] |
| XRANGE | Devuelve entradas que coinciden con un rango dado de ID. | XRANGE key start end [COUNT count] |
| XREAD | Lee datos de uno o varios flujos, solo devuelve entradas con un ID mayor que el último ID recibido informado por la persona que llama. | XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...] |
| XREADGROUP | Una versión especial del comando XREAD, que se utiliza para especificar un grupo de consumidores para leer. | XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...] |
| XREVRANGE | Este comando es exactamente igual a XRANGE pero con la notable diferencia de devolver las entradas en el orden inverso, y también tomar el rango de inicio-final en el orden inverso. | XREVRANGE key end start [COUNT count] |
| XTRIM | Recorta la secuencia a un número especificado de elementos, si es necesario, desalojando los elementos antiguos (elementos con identificadores inferiores). | XTRIM key MAXLEN [~] count |
Confirmación de mensaje (elemento de flujo)
En comparación con Pub/Sub, las transmisiones no solo admiten grupos de consumidores, sino también la confirmación de mensajes.
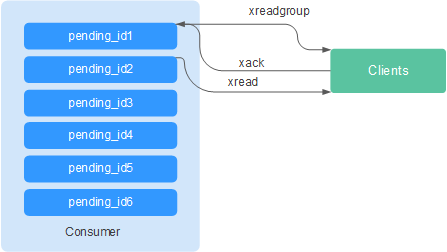
Cuando un consumidor invoca el commando XREADGROUP para leer o invoca el commando XCLAIM para asumir un mensaje, el servidor no sabe si el mensaje se procesa al menos una vez. Por lo tanto, una vez que se ha procesado con éxito un mensaje, el consumidor debe invocar el commando XACK para notificar el flujo de manera que el mensaje no se procesará de nuevo. Además, el mensaje se elimina de PEL y la memoria se liberará del servidor de Redis.
En algunos casos, como las fallas de red, el cliente no invoca XACK después del consumo. En tales casos, el ID del elemento se conserva en PEL. Después de volver a conectar el cliente, establezca el ID de mensaje de inicio de XREADGROUP en 0-0, indicando que todos los mensajes PEL y mensajes después de last_id son leídos. Además, se debe admitir la transmisión de mensajes repetidos cuando los consumidores consumen mensajes.
Optimización del uso de memoria
El uso de memoria de Redis 5.0 está optimizado en función de la versión anterior.
- Desfragmentación activa
Si una clave se modifica con frecuencia y la longitud del valor cambia constantemente, Redis asignará memoria adicional para la clave. Para lograr un alto rendimiento, Redis utiliza el asignador de memoria para gestionar la memoria. La memoria no siempre se libera hasta el sistema operativo. Como resultado, se producen los fragmentos de memoria. Si la relación de fragmentación (used_memory_rss/used_memory) es superior a 1.5, el uso de memoria es ineficiente.
Para reducir los fragmentos de memoria, planifique y use adecuadamente los datos de caché y estandarice la escritura de datos.
Para Redis 3.0 y las versiones anteriores, los problemas de fragmentación de memoria se resuelven reiniciando el proceso regularmente. Se recomienda que los datos de caché reales no excedan el 50% de la memoria disponible.
Para Redis 4.0, se admite la desfragmentación activa y la memoria se desfragmenta mientras está en línea. Además, Redis 4.0 admite la desfragmentación manual de memoria ejecutando el comando memory purge.
Para Redis 5.0, se admite una desfragmentación activa mejorada con Jemalloc actualizado, que es más rápido, más inteligente y proporciona una latencia más baja.
- Mejoras en el despliegue de HyperLogLog
HyperLogLog es una estructura de datos probabilística utilizada para calcular la cardinalidad de un conjunto mientras consume poca memoria. Redis 5.0 mejora HyperLogLog al optimizar aún más su uso de memoria.
Por ejemplo: el árbol B es eficiente en el recuento, pero consume mucha memoria. Utilizando HyperLogLog se puede guardar mucha memoria. Mientras que el árbol B requiere 1 MB de memoria para contar, HyperLogLog solo necesita 1 KB.
- Estadísticas de memoria mejoradas
La información devuelta por el comando INFO es más detallada.
Nuevos y mejores comandos
- Gestión de clientes mejorada
- redis-cli admite la gestión de clústeres.
En Redis 4.0 y versiones anteriores, es necesario instalar el módulo redis-trib para gestionar clústeres.
Redis 5.0 optimiza redis-cli, integrando todas las funciones de gestión de clústeres. Puede ejecutar el comando redis-cli --cluster help para obtener más información.
- redis-cli admite la gestión de clústeres.
- Uso más sencillo de conjuntos ordenados
Los comandos ZPOPMIN y ZPOPMAX se agregan para conjuntos ordenados.
- ZPOPMIN key [count]
Elimina y devuelve hasta miembros count con las puntuaciones más bajas en el conjunto ordenado almacenado en key. Al devolver varios elementos, el que tenga la puntuación más baja será el primero, seguido por los elementos con puntuaciones más altas.
- ZPOPMAX key [count]
Elimina y devuelve hasta miembros de count con las puntuaciones más altas en el conjunto ordenado almacenado en key. Al devolver varios elementos, el que tenga la puntuación más baja será el primero, seguido por los elementos con puntuaciones más bajas.
- ZPOPMIN key [count]
- Agregados más subcomandos en el comando help
El comando help se puede utilizar para ver información de ayuda, ahorrándole el problema de visitar redis.io cada vez. Por ejemplo, ejecute el siguiente comando para ver la información de ayuda de la secuencia xinfo help
127.0.0.1:6379> xinfo help 1) XINFO <subcommand> arg arg ... arg. Subcommands are: 2) CONSUMERS <key> <groupname> -- Show consumer groups of group <groupname>. 3) GROUPS <key> -- Show the stream consumer groups. 4) STREAM <key> -- Show information about the stream. 5) HELP -- Print this help. 127.0.0.1:6379>
- Consejos de entrada de comandos de redis-cli
Después de escribir un comando completo, redis-cli muestra una sugerencia de parámetro que le ayudará a memorizar el formato de sintaxis del comando.
Como se muestra en la siguiente figura, ejecute el comando zadd y redis-cli muestra la sintaxis de zadd en color claro.

Almacenamiento en RDB de LFU y de LRU
En Redis 5.0, se agregaron las políticas de desalojo de claves de almacenamiento LRU y LFU al archivo de instantáneas de RDB.
- FIFO: El primero en entrar, el primero en salir. Los primeros datos almacenados se desalojan primero.
- LRU: Menos utilizado recientemente. Los datos que no se utilizan durante mucho tiempo se desalojan primero.
- LFU: Menos frecuentemente utilizado. Los datos que se utilizan con menos frecuencia se desalojan primero.

El formato de archivo de RDB de Redis 5.0 se modifica y es compatible con las versiones anteriores. Por lo tanto, si se utiliza una instantánea para la migración, los datos se pueden migrar desde las versiones anteriores de Redis a Redis 5.0, pero no se pueden migrar desde Redis 5.0 a las versiones anteriores.




