
Overview
Inference deployment is an important part of AI and machine learning. Inference deployment moves a trained machine learning or deep learning model from the development environment to the production environment. This allows the model to predict outcomes for new, unseen data. The goal is to ensure the model works efficiently and reliably in real-world applications, meeting real-time and resource needs. Simply put, it makes the model operational, providing outputs like image classification, text sentiment analysis, and trend predictions based on input data.
ModelArts offers you compute, storage, and network resources to deploy, use, manage, and monitor your AI model after development. ModelArts supports cloud, edge, and on-device deployments. It also supports real-time, batch, and edge inference.
Deployment Modes
ModelArts supports cloud deployments. It also supports real-time and batch inference.
- Real-time inference: Processes a single request instantly and returns the result right away. ModelArts allows you to deploy a model as a web service that provides a real-time test UI and monitoring capabilities. This service provides a callable API. Real-time inference is used in situations that need fast responses, like online intelligent customer service and autonomous driving decisions.
- Batch inference: Processes multiple inputs at once and returns all results together. ModelArts allows you to deploy a model as a batch service. This service runs inference on batch data and stops automatically when done. Batch inference works well for offline tasks like big data analysis, batch data labeling, and model evaluation.
Description
Deploying a service in ModelArts uses compute and storage resources, which are billed. Compute resources are billed for running the inference service. Storage resources are billed for storing data in OBS. For details, see Table 1.
|
Billing Item |
Description |
Billing Mode |
Billing Formula |
|
|---|---|---|---|---|
|
Compute resource |
Public resource pools |
Usage of compute resources. For details, see ModelArts Pricing Details. |
Pay-per-use |
Specification unit price x Number of compute nodes x Usage duration |
|
Dedicated resource pools |
Fees for dedicated resource pools are paid upfront upon purchase. There are no additional charges for service deployment. For details about dedicated resource pool fees, see Dedicated Resource Pool Billing Items. |
N/A |
N/A |
|
|
Storage resource |
Object Storage Service (OBS) |
OBS is used to store the input and output data for service deployment. For details, see Object Storage Service Pricing Details.
CAUTION:
OBS resources for storing data are continuously billed. To stop billing, delete the data stored in OBS. |
Pay-per-use Yearly/Monthly |
Creating an OBS bucket is free of charge. You pay only for the storage capacity and duration you actually use. |
|
Event notification (billed only when enabled) |
This function uses Simple Message Notification (SMN) to send a message to you when the event you selected occurs. To use this function, enable event notification when creating a training job. For pricing details, see Simple Message Notification Pricing Details. |
Pay by actual usage |
|
|
|
Run logs (billed only when enabled) |
Log Tank Service (LTS) collects, analyzes, and stores logs. If Runtime Log Output is enabled during service deployment, you will be billed if the log data exceeds the LTS free quota. For details, see Log Tank Service Pricing Details. |
Pay by actual log size |
After the free quota is exceeded, you are billed based on the actual log volume and retention duration. |
|
Inference Deployment Process
You can import and deploy AI models as inference services. These services can be integrated into your IT platform by calling APIs or generate batch results.

- Prepare inference resources: Select required resources based on the site requirements. ModelArts provides you with public resource pools and dedicated resource pools. To use dedicated compute resources, you need to purchase and create a dedicated resource pool first. For details, see Creating a Dedicated Resource Pool.
- Train a model: Models can be trained in ModelArts or your local development environment. A locally developed model must be uploaded to Huawei Cloud OBS.
- Create a model: Import the model file and inference file to the ModelArts model repository and manage them by version. Use these files to build an executable model.
- Deploy a service: Deploy the model as a service type based on your needs.
- Deploying a Model as Real-Time Inference Jobs
Deploy a model as a web service with real-time UI and monitoring. This service provides you a callable API.
- Deploying a Model as a Batch Inference Service
Deploy an AI application as a batch service that performs inference on batch data and automatically stops after data processing is complete.
Figure 2 Different inference scenarios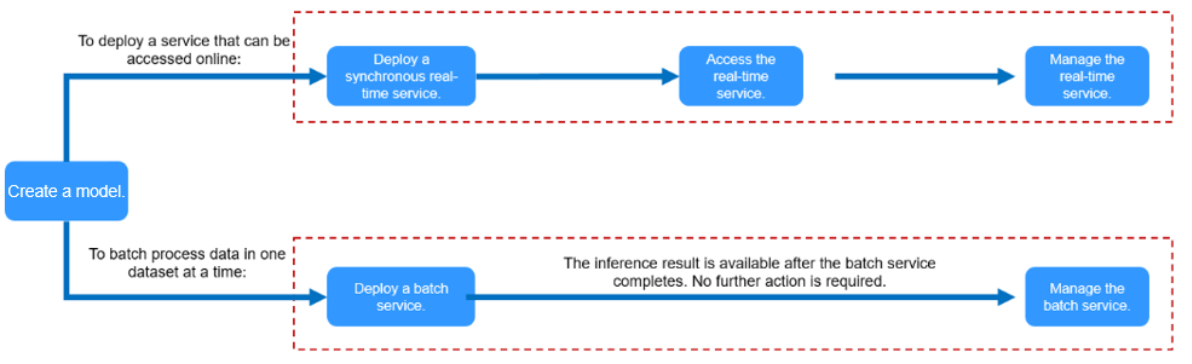
- Deploying a Model as Real-Time Inference Jobs
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



