
Data Mapper
The data mapper processor is used to convert the data format. Subsequent nodes can reference the output data from a data mapper using ${payload}.
Supported types:
- Databases: Db2, MySQL, Oracle, PostgreSQL/openGauss, and SQL Server
- Message systems: ActiveMQ, ArtemisMQ, and RabbitMQ
- Common data types: JSON, XML, and CSV
Configuring Parameters
|
Parameter |
Description |
|---|---|
|
Source Data Source |
If the data source is a database, the field information is automatically displayed after a table is selected. In other cases, manually add fields or import a file. Only JSON, XML, and CSV files can be imported. |
|
Destination Data Source |
If the data source is a database, the field information is automatically displayed after a table is selected. In other cases, manually add fields or import a file. Only JSON, XML, and CSV files can be imported. |
Tips:
- Mapping mode: Click the data field to be mapped in the source data source and then click the corresponding field in the destination data source.
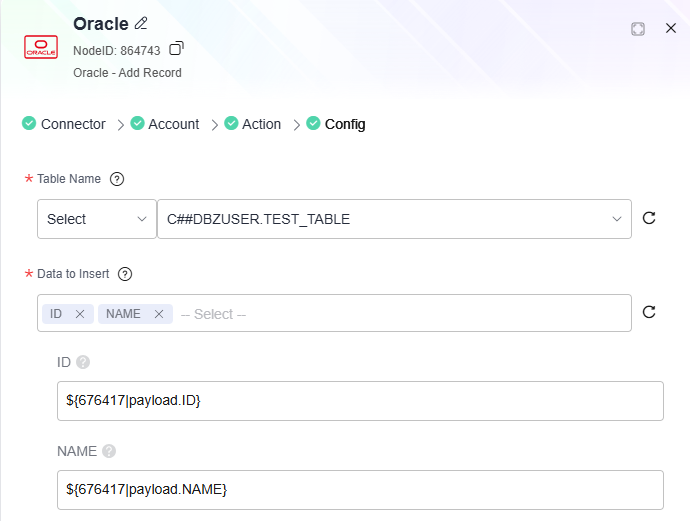
- Output reference: Subsequent nodes can reference the output data from a data mapper using ${payload}. Example: ${075007|payload.ID}.
${075007|payload.ID} is in the format of ${Node ID|payload.xxx}. To reference output data from a data mapper, use this format.
Note: You can click the data mapping processor to obtain the node ID.


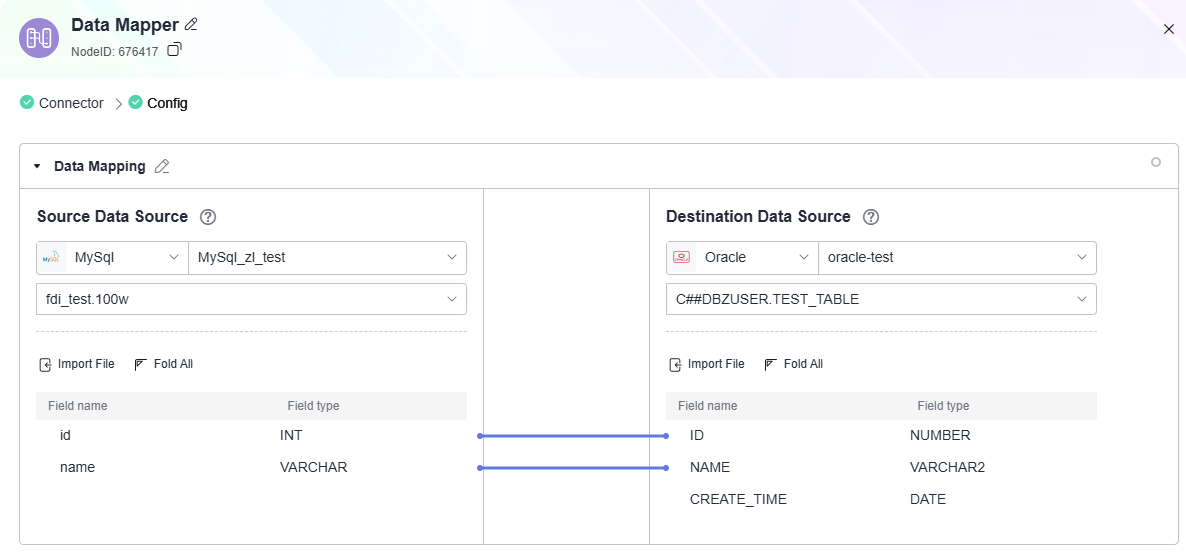
Database as Source and Destination
- Flow: Call the OpenAPI to retrieve MySQL data, map it to Oracle table fields, and use the mapped data to add records to the Oracle database.

Destination - XML Data Example
If destination data source format is XML, Root Tag defaults to root. You can set this parameter to other values but cannot leave it empty.
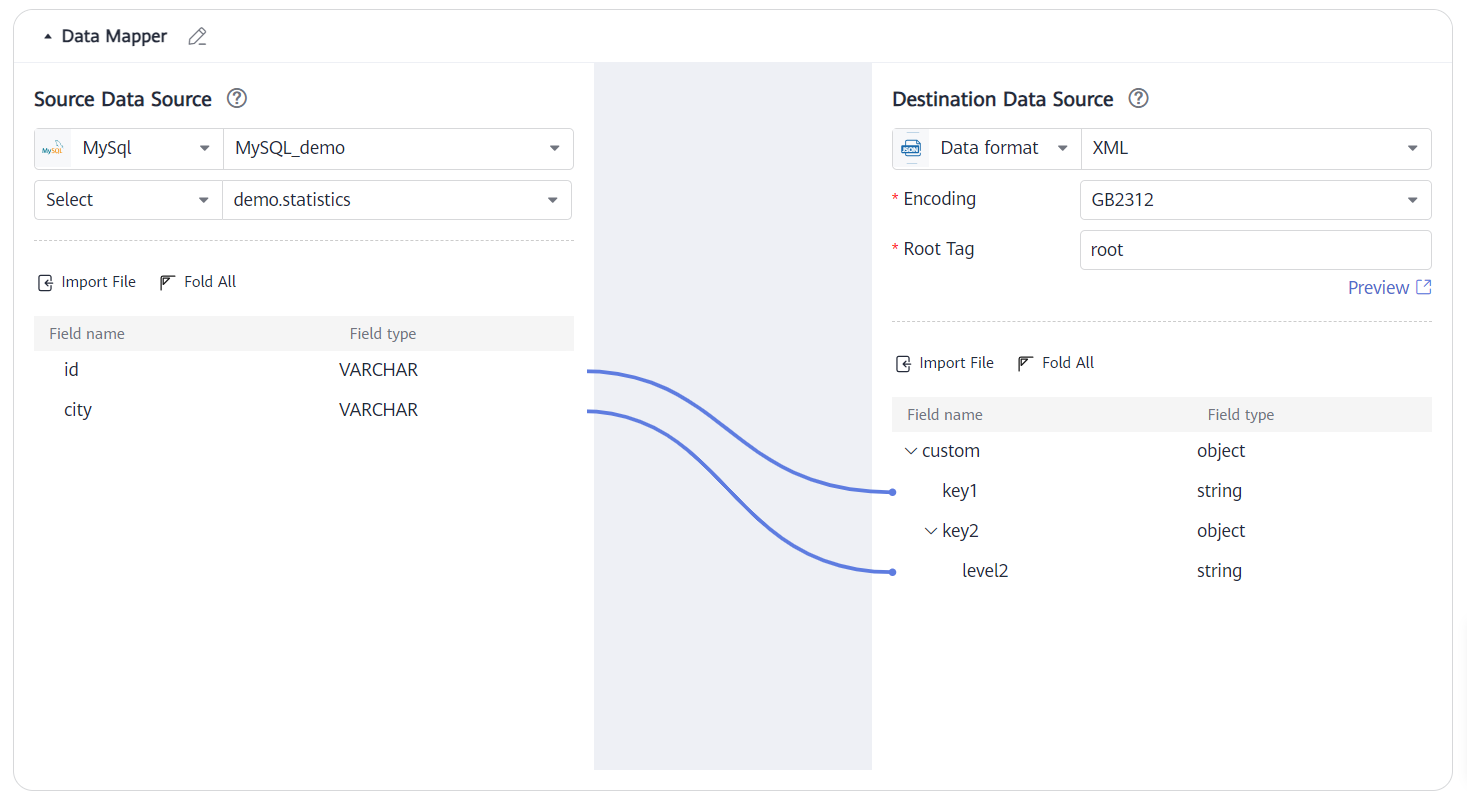
Data in the demo.statistics table of the source MySQL database:
|
id |
city |
|---|---|
|
uuid1 |
suzhou |
|
uuid2 |
shanghai |
Mapping result:
<root>
<custom>
<key1>uuid1</key1>
<key2>
<level2>suzhou</level2>
</key2>
</custom>
<custom>
<key1>uuid2</key1>
<key2>
<level2>shanghai</level2>
</key2>
</custom>
</root>
Destination - CSV Data Example
Header: Whether to include the table header of the CSV file in the output. Options are true and false.
Delimiter: Data in each file column is separated by cells, which can be represented as tab characters, spaces, commas, or semicolons.
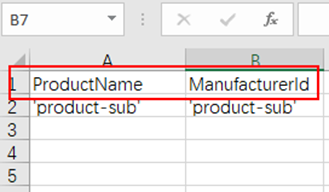
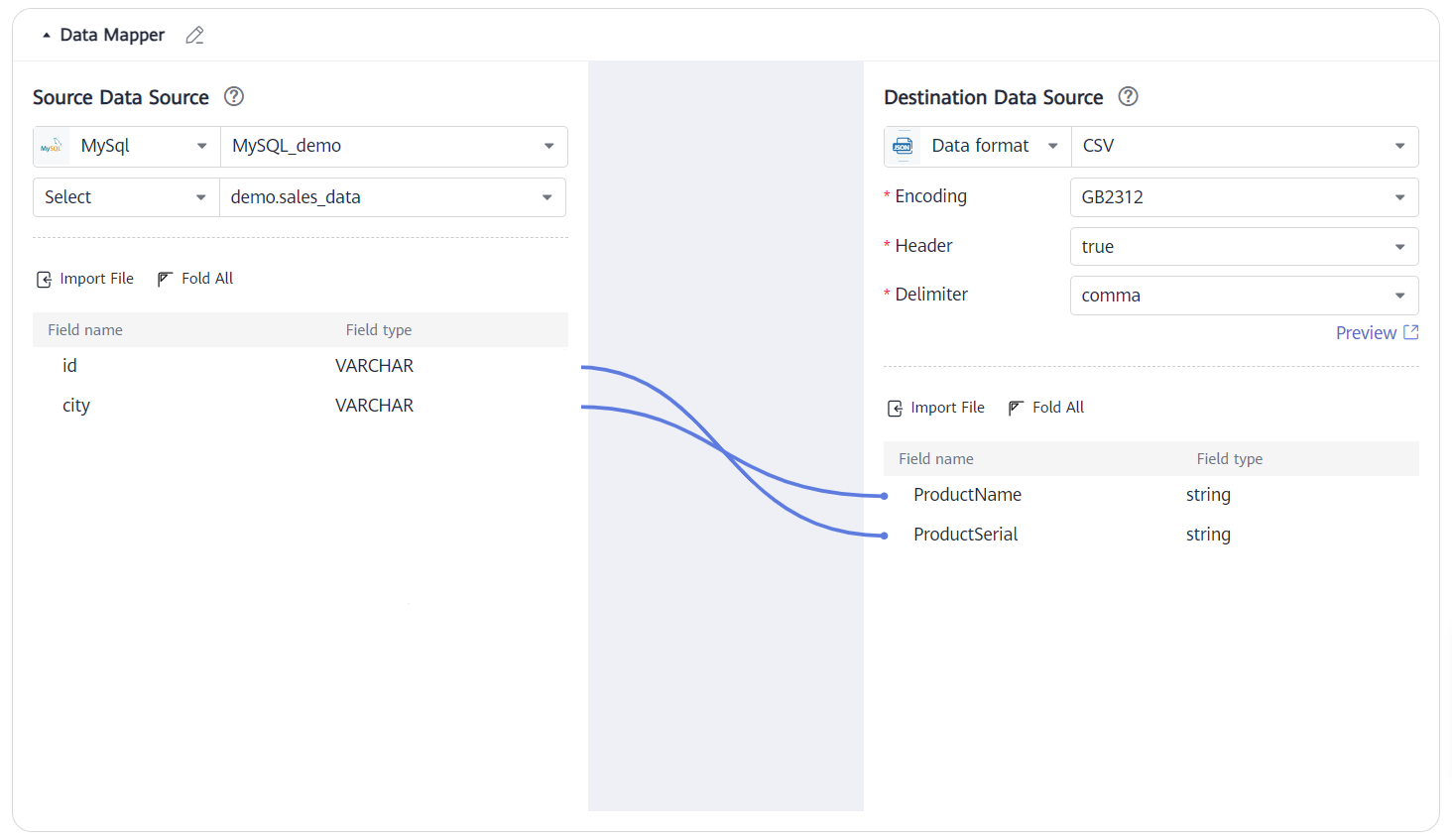
Scenario 1: Set the destination data source format to CSV, Header to true, and Delimiter to comma.
When a file is imported, if Header is set to true, the first line of the CSV file is the field names.
Data in the demo.statistics table of the source MySQL database:
|
id |
city |
|---|---|
|
uuid1 |
suzhou |
|
uuid2 |
shanghai |
Mapping result:
ManufacturerId, ProductName uuid1, suzhou uuid2, shanghai
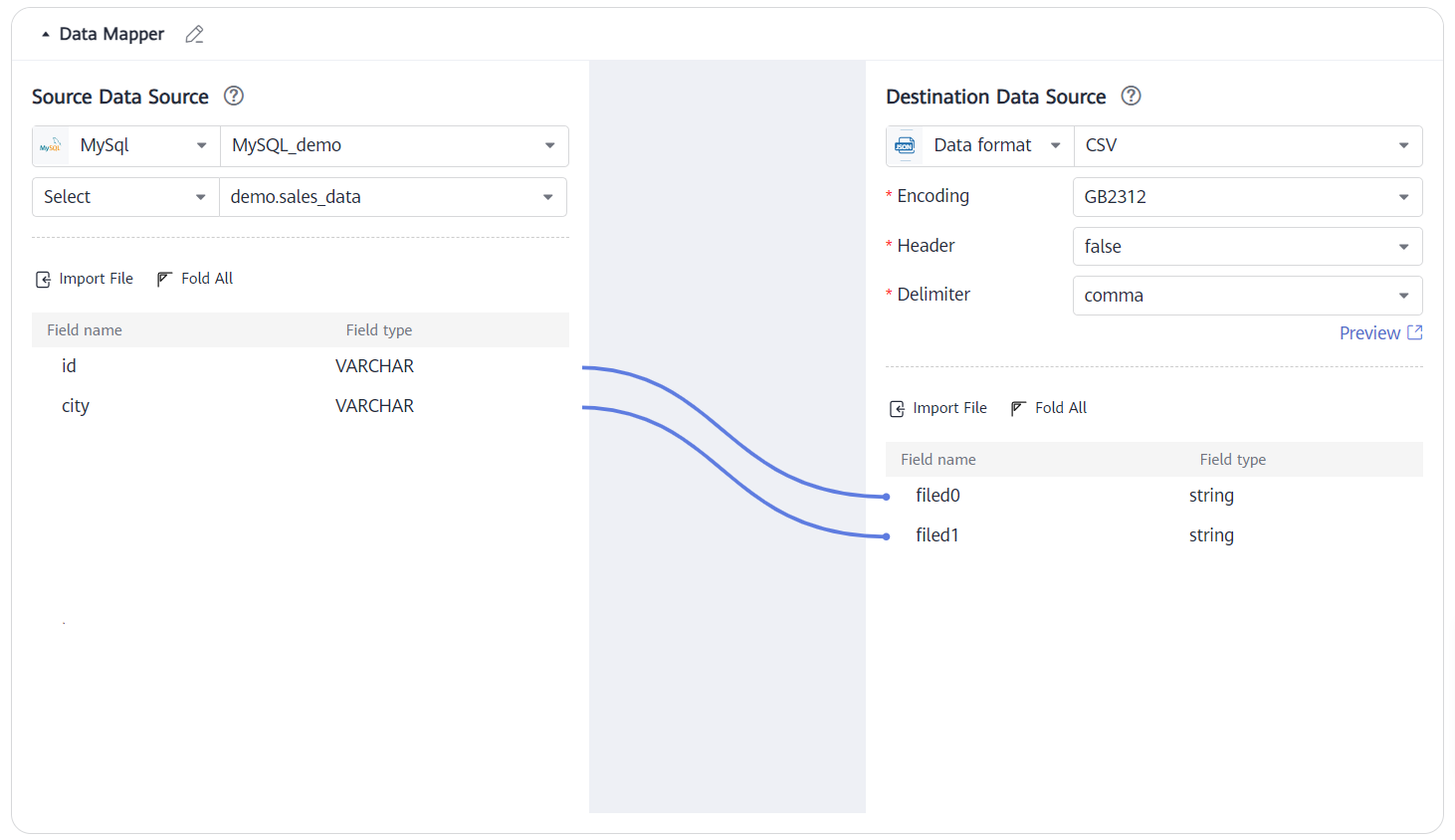
Scenario 2: Set the destination data source format to CSV, Header to false, and Delimiter to comma.
When a file is imported, if Header is set to false, the header field of the imported file is not used. The filedN field is used by default.

Data in the demo.statistics table of the source MySQL database:
|
id |
city |
|---|---|
|
uuid1 |
suzhou |
|
uuid2 |
shanghai |
Mapping result:
uuid1, suzhou uuid2, shanghai
Source - JSON Data Example
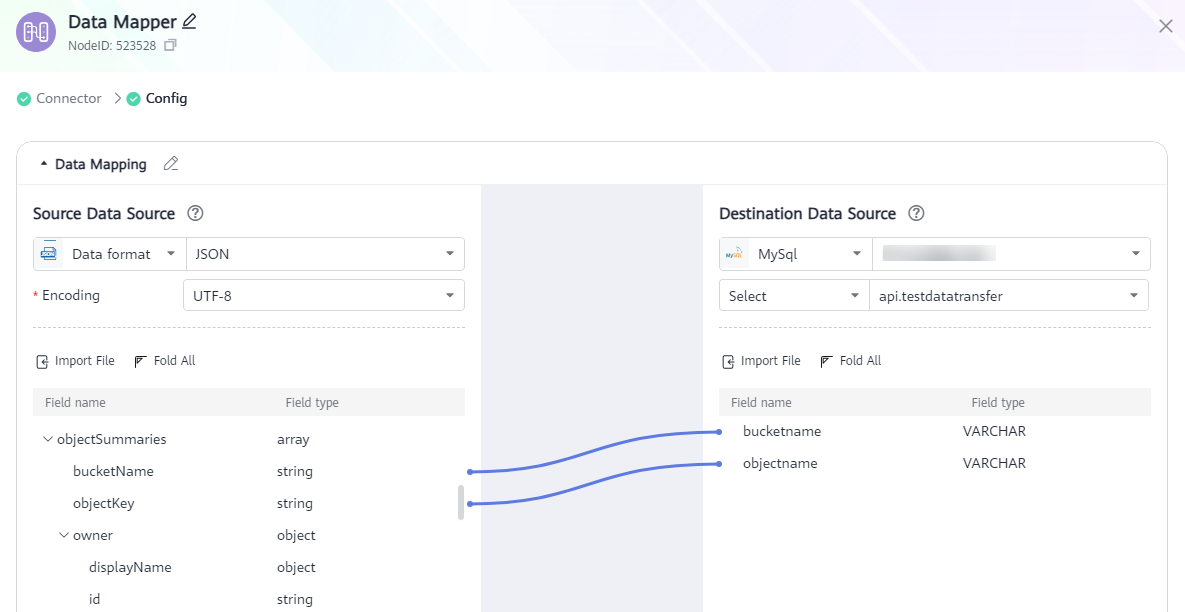
(Example) The following composite application calls the OpenAPI to list objects in a specified OBS bucket and map the bucket name and object names to corresponding fields in a specified MySQL table via data mapping, and then stores the bucket name and object names to MySQL.
In this application, the OBS data serves as the source of data mapping, while MySQL is the destination.
Use the OpenAPI to call the OBS connector to list bucket objects as the import file of the source data source. Alternatively, you can also manually add fields based on the object list.

If the source data format is JSON, use the output of the source data source as the import file of the source, and select the encoding format (GB2312, UTF-8, or ASCII) of the file. The system automatically generates fields accordingly.
Set the destination data format to MySQL, and select a table name. The system automatically generates fields in the database table.
(Example) The following composite application calls he open API to list objects in a specified OBS bucket and map the bucket name and object names to corresponding fields in a specified MySQL table via data mapping, and then stores the bucket name and object names to MySQL. In this application, the OBS data serves as the source of data mapping, while MySQL is the destination. Use the OpenAPI to call the OBS connector to list bucket objects as the import file of the source data source. Alternatively, you can also manually add fields based on the object list.

Content of the imported file:
{
"responseHeaders": {
"bucket-location": "cn",
"connection": "keep-alive"
},
"objectSummaries": [
{
"bucketName": "test0223",
"objectKey": "test0424.txt",
"owner": {
"displayName": null,
"id": "uuid"
},
"metadata": {
"responseHeaders": {},
"originalHeaders": {}
},
"objectContent": null
}
]
}
Data mapping result:

Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



