
Elasticsearch Basic Principles
Elasticsearch Architecture
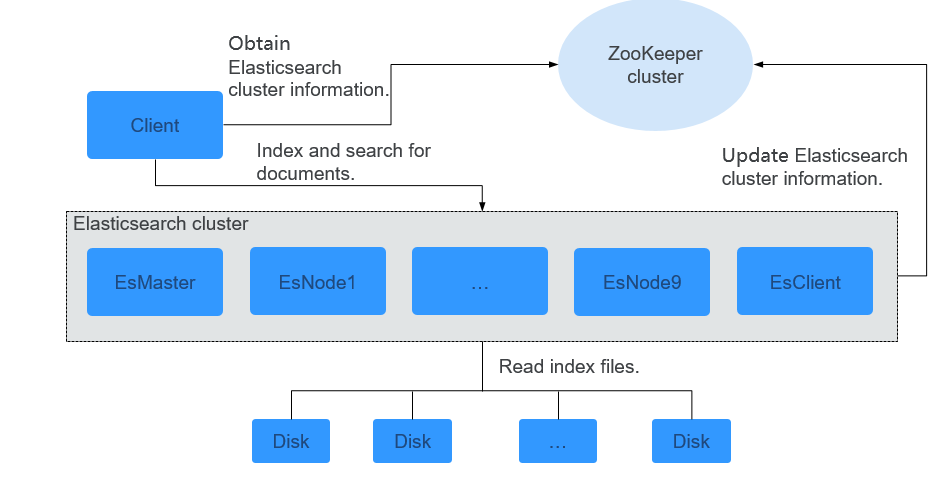
The Elasticsearch cluster solution consists of the EsMaster and EsClient, EsNode1, EsNode2, EsNode3, EsNode4, EsNode5, EsNode6, EsNode7, EsNode8, and EsNode9 processes, as shown in Figure 1. Table 1 describes the modules.
|
Name |
Description |
|---|---|
|
Client |
Client communicates with the EsClient and EsNode instance processes in the Elasticsearch cluster over HTTP or HTTPS to perform distributed collection and search. |
|
EsMaster |
EsMaster is the master node of Elasticsearch. It manages the cluster, such as determining shard allocation and tracing cluster nodes. |
|
EsNode1-9 |
EsNodes 1-9 are data nodes of Elasticsearch. They store index data, and add, delete, modify, query, and aggregate documents. |
|
EsClient |
EsClient is the coordinator node of Elasticsearch. It processes routing requests, searches for data, and dispatches indexes. EsClient neither store data or manage clusters. |
|
ZooKeeper cluster |
Provides heartbeat mechanism for processes in the Elasticsearch cluster. |
Basic Concepts
- Index: An index is a logical namespace in Elasticsearch, consisting of one or multiple shards. Apache Lucene is used to read and write data in the index. It is similar to a relational table instance. One Elasticsearch instance can contain multiple indexes.
- Document: A document is a basic unit of information that can be indexed. This document refers to JSON data at the top-level structure or obtained by serializing the root object. The document is similar to a row in the database. An index contains multiple documents.
- Mapping: A mapping is used to restrict the type of a field and can be automatically created based on data. It is similar to the schema in the database.
- Field: A field is the minimum unit of a document, which is similar to a column in the database. Each document contains multiple fields.
- EsMaster: The master node that temporarily manages some cluster-level changes, such as creating or deleting indexes, and adding or removing nodes. The master node does not participate in document-level change or search. When traffic increases, the master node does not become the bottleneck of the cluster.
- EsNode: an Elasticsearch node. A node is an Elasticsearch instance.
- ESClient: an Elasticsearch node. It processes routing requests, searches for data, and dispatches indexes. It does not store data or manage a cluster.
- Shard: A shard is the smallest work unit in Elasticsearch. It stores documents that can be referenced in the shard.
- Primary shard: Each document in the index belongs to a primary shard. The number of primary shards determines the maximum data that can be stored in the index.
- Replica shard: A replica shard is a copy of the primary shard. It prevents data loss caused by hardware faults and provides read requests, such as searching for or retrieving documents from other shards.
- Recovery: Indicates data restoration or data redistribution. When a node is added or deleted, Elasticsearch redistributes index shards based on the load of the corresponding physical server. When a faulty node is restarted, data recovery is also performed.
- Gateway: Indicates the storage mode of an Elasticsearch index snapshot. By default, Elasticsearch stores an index in the memory. When the memory is full, Elasticsearch saves the index to the local hard disk. A gateway stores index snapshots. When the corresponding Elasticsearch cluster is stopped and then restarted, the index backup data is read from the gateway. Elasticsearch supports multiple types of gateways, including local file systems (default), distributed file systems, and Hadoop HDFS.
- Transport: Indicates the interaction mode between Elasticsearch internal nodes or clusters and the Elasticsearch client. By default, Transmission Control Protocol (TCP) is used for interaction. In addition, HTTP (JSON format), Thrift, Servlet, Memcached, and ZeroMQ transmission protocols (integrated through plug-ins) are supported.
- ZooKeeper cluster: It is mandatory in Elasticsearch and provides functions such as storage of security authentication information.
Principle
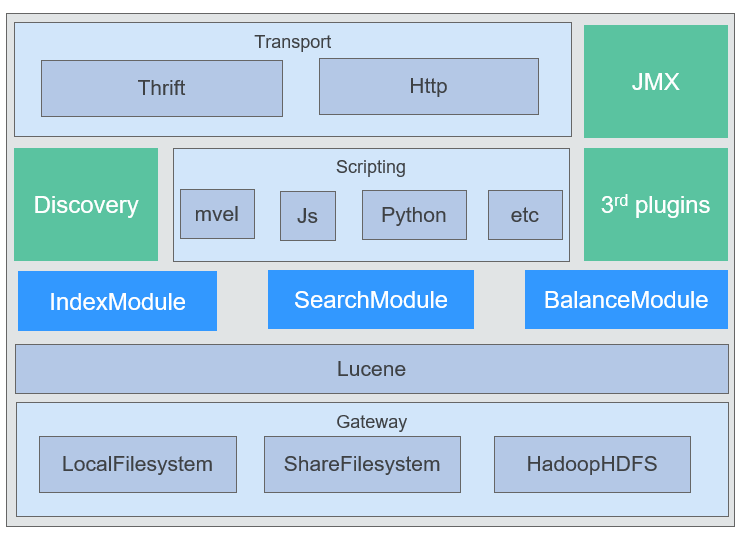
- Elasticsearch Internal Architecture
Elasticsearch provides various access APIs through RESTful APIs or other languages (such as Java), uses the cluster discovery mechanism, and supports script languages and various plug-ins. The underlying layer is based on Lucene, with absolute independence of Lucene, and stores indexes through local files, shared files, and HDFS, as shown in Figure 2.
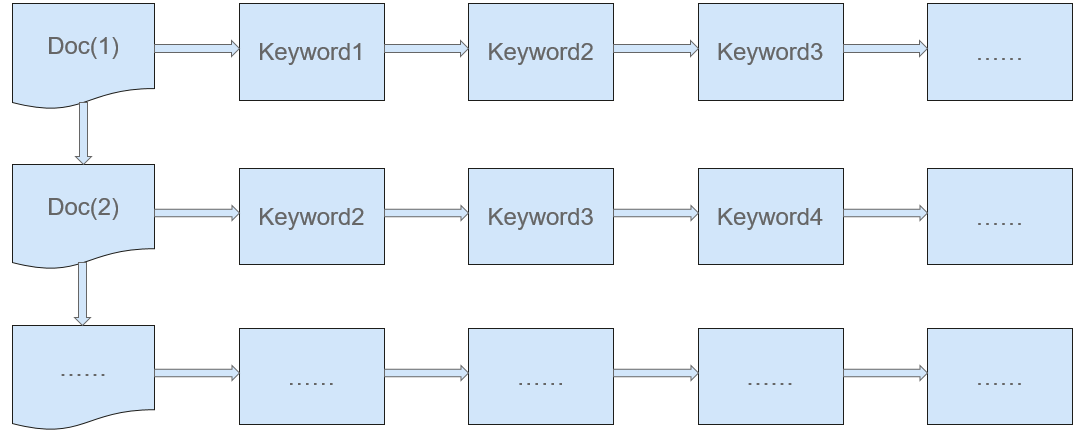
- Inverted indexing
In the traditional search mode (forward indexing, as shown in Figure 3), documents are searched based on their IDs. During the search, keywords of each document are scanned to find the keywords that meet the search criteria. Forward indexing is easy to maintain but is time consuming.
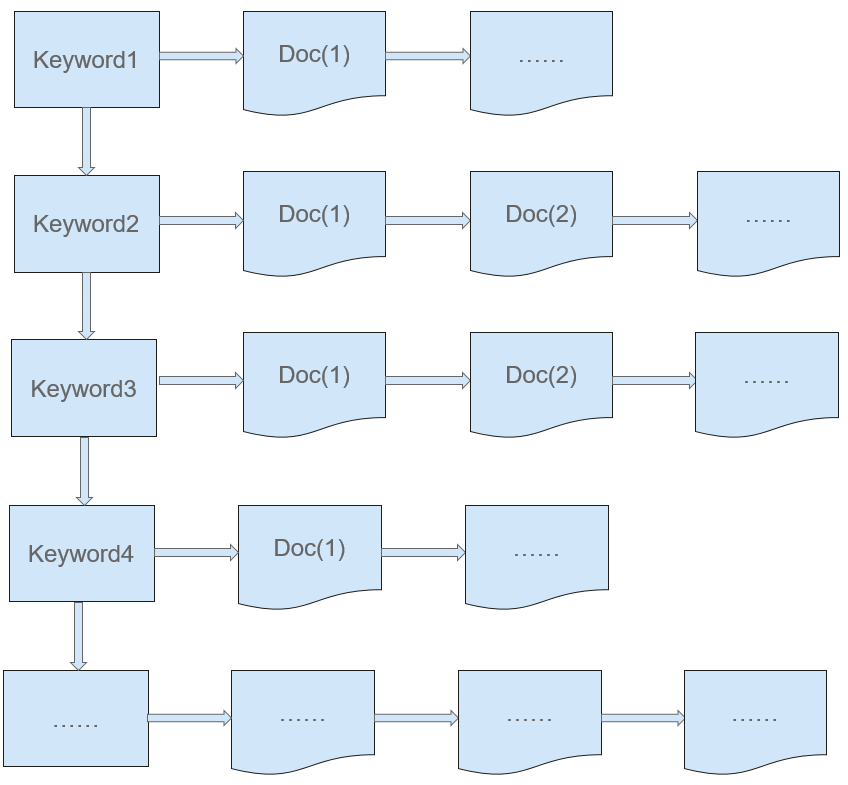
Elasticsearch (Lucene) uses the inverted indexing mode, as shown in Figure 4. A table consisting of different keywords is called a dictionary, which contains various keywords and statistics of the keywords (including the ID of the document where a keyword is located, the location of the keyword in the document, and the frequency of the keyword). In this search mode, Elasticsearch searches for the document ID and location based on a keyword and then finds the document, which is similar to the method of looking for a word in a dictionary or finding the content on a specific book page according to the table of contents of the book. Inverted indexing is time consuming for constructing indexes and costly for maintenance, but it is efficient in search.
- Elasticsearch Distributed Indexing
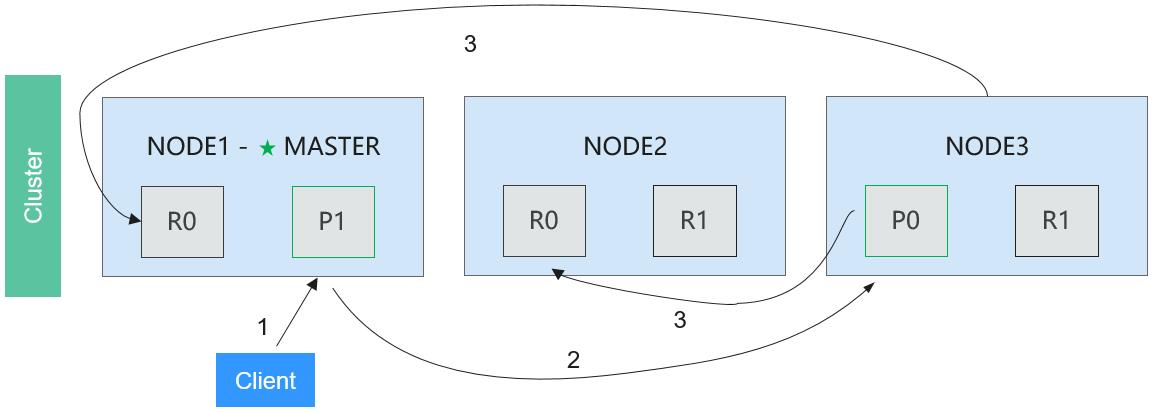
Figure 5 shows the process of Elasticsearch distributed indexing flow.
The procedure is as follows:
Phase 1: The client sends an index request to any node, for example, Node 1.
Phase 2: Node 1 determines the shard (for example, shard 0) to store the file based on the request. Node 1 then forwards the request to Node 3 where primary shard P0 of shard 0 exists.
Phase 3: Node 3 executes the request on primary shard P0 of shard 0. If the request is successfully executed, Node 3 sends the request to all the replica shard R0 in Node 1 and Node 2 concurrently. If all the replica shards successfully execute the request, a verification message is returned to Node 3. After receiving the verification messages from all the replica shards, Node 3 returns a success message to the user.
- Elasticsearch Distributed Searching
The Elasticsearch distributed searching flow consists of query and acquisition.
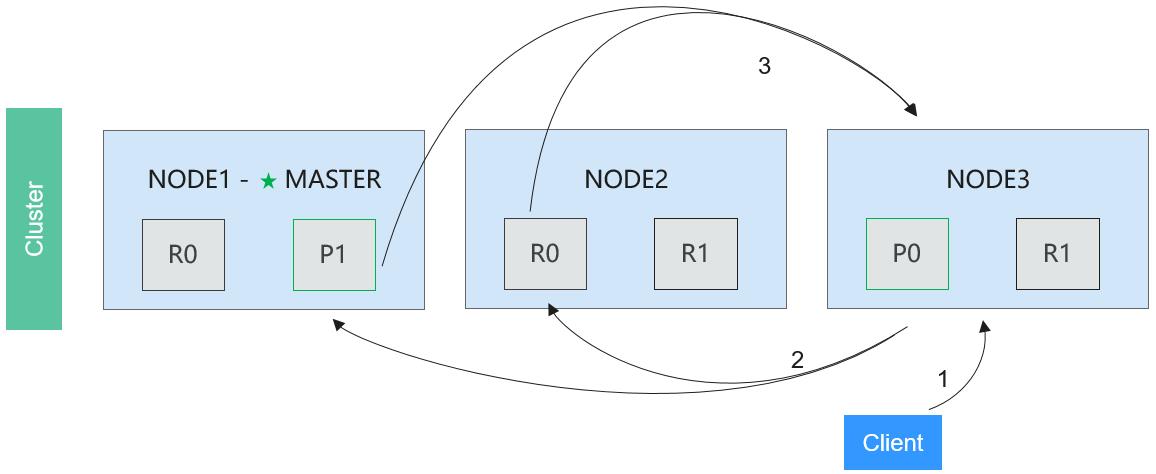
Figure 6 shows the query phase.
The procedure is as follows:
Phase 1: The client sends a retrieval request to any node, for example, Node 3.
Phase 2: Node 3 sends the retrieval request to each shard in the index adopting the polling policy. One of the primary shards and all of its replica shards is randomly selected to balance the read request load. Each shard performs retrieval locally and adds the sorting result to the local node.
Phase 3: Each shard returns the local result to Node 3. Node 3 combines these values and performs global sorting.
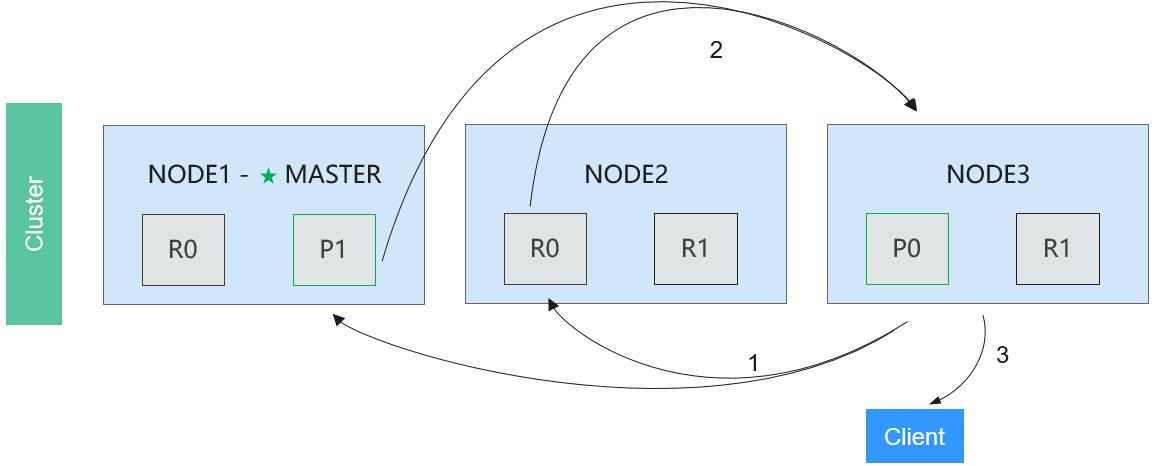
In the query phase, the data to be retrieved is located. In the acquisition phase, these data will be collected and returned to the client. Figure 7 shows the acquisition phase.
The procedure is as follows:
Phase 1: After all data to be retrieved is located, Node 3 sends a request to related shards.
Phase 2: Each shard that receives the request from Node 3 reads the related files and return them to Node 3.
Phase 3: After obtaining all the files returned by the shards, Node 3 combines them into a summary result and returns it to the client.
- Elasticsearch Distributed Bulk Indexing
Figure 8 Distributed bulk indexing flow
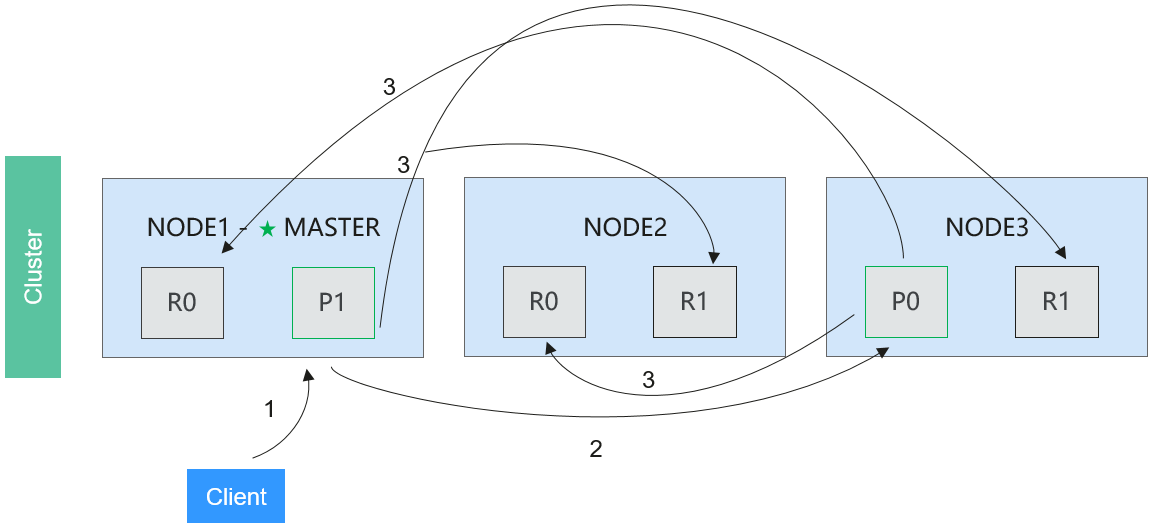
The procedure is as follows:
Phase 1: The client sends a bulk request to Node 1.
Phase 2: Node 1 constructs a bulk request for each shard and forwards the requests to the primary shard according to the request.
Phase 3: The primary shard executes the requests one by one. After an operation is complete, the primary shard forwards the new file (or deleted part) to the corresponding replication node and then performs the next operation. Replica nodes report to the request node that all operations are complete. The request node sorts the response and returns it to the client.
- Elasticsearch Distributed Bulk Searching
Figure 9 Distributed bulk searching flow
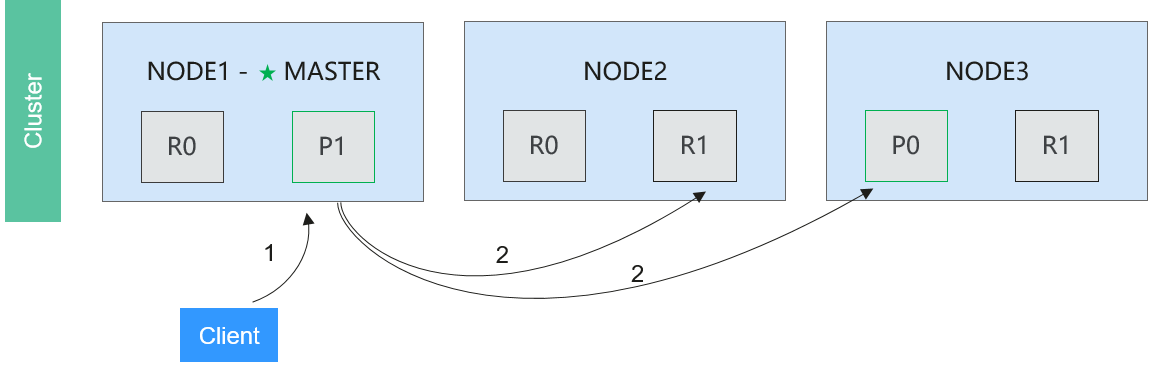
The procedure is as follows:
Phase 1: The client sends an mget request to Node 1.
Phase 2: Node 1 constructs a retrieval request of multi-piece data records for each shard and forwards the requests to the primary shard or its replica shard based on the requests. When all replies are received, Node 1 constructs a response and returns it to the client.
- Elasticsearch Routing Algorithm
Elasticsearch provides two routing algorithms:
- Default route: shard=hash (routing) %number_of_primary_shards.
- Custom route: In this routing mode, the routing can be specified to determine the shard to which the file is written, or only the specified routing can be searched.
- Elasticsearch Balancing Algorithm
Elasticsearch provides the automatic balance function for capacity expansion, capacity reduction, and data import scenarios. The algorithm is as follows:
weight_index(node, index) = indexBalance * (node.numShards(index) - avgShardsPerNode(index))
Weight_node(node, index) = shardBalance * (node.numShards() - avgShardsPerNode)
weight(node, index) = weight_index(node, index) + weight_node(node, index)
- Elasticsearch Multi-Instance Deployment on a Node
Multiple Elasticsearch instances can be deployed on the same node, and differentiated from each other based on the IP address and port number. This method increases the usage of the single-node CPU, memory, and disk, and improves the Elasticsearch indexing and searching capability.
Figure 10 Multi-instance deployment on a node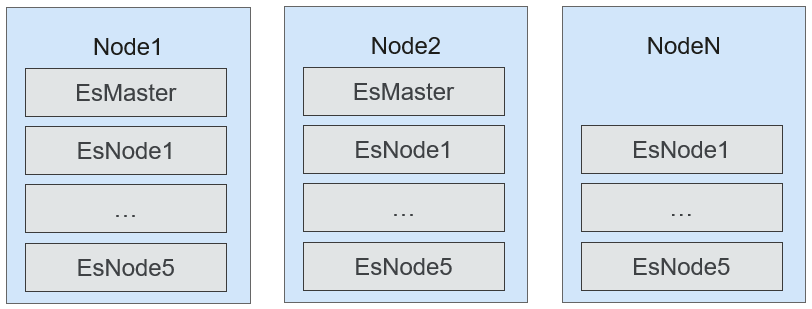
- Elasticsearch Cross-Node Replica Allocation Policy
When multiple instances are deployed on a node and multiple replicas exist, replicas can only be allocated across instances. However, SPOFs may occur. To solve this problem, set cluster.routing.allocation.same_shard.host to true.
Figure 11 Automatic replica distribution across nodes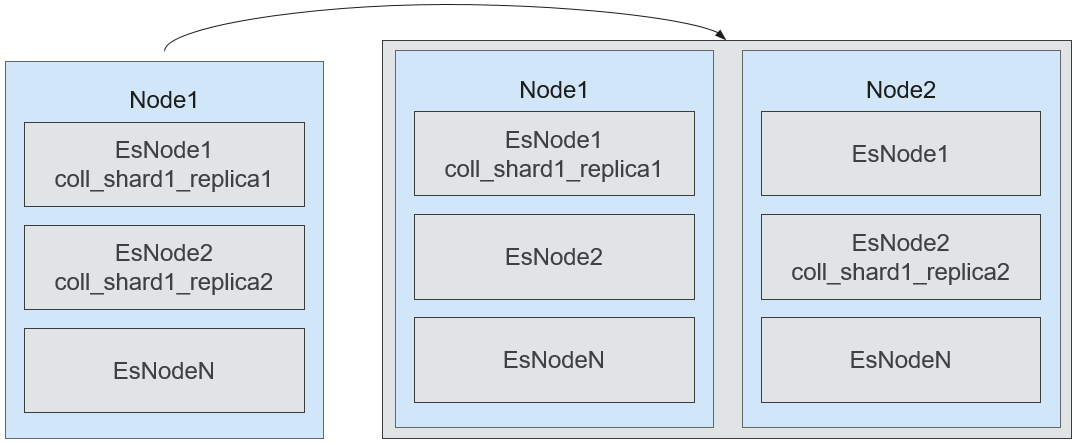
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



