
Parameter Tuning
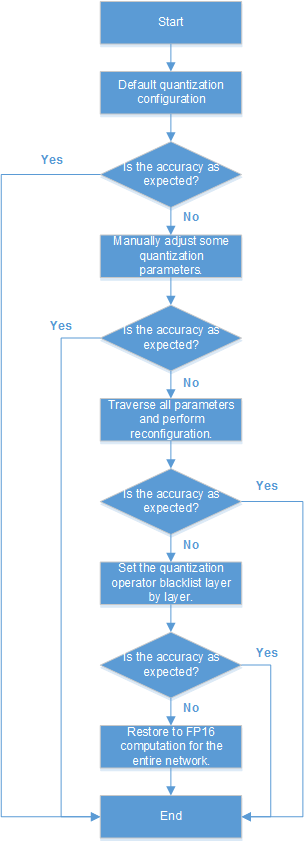
The weight, offset, and data are quantized based on the quantization parameters set during model conversion. If the accuracy does not meet requirements, you can perform the following steps to adjust the quantization parameters.
- Calibrate the model data and parameters based on the default parameter values described in Configuration File Template.
- If the quantization accuracy obtained in Step 1 is as expected, the parameter tuning ends. Otherwise, go to Step 3.
- Manually perform the following modifications and then perform quantization.
- Modify the search range parameters.
Table 1 Search scope parameters As It Is
To Be
start_ratio: 0.7
end_ratio: 1.3
step_ratio: 0.01
start_ratio: 0.3
end_ratio: 1.7
step_ratio: 0.01
- Change the value of bin from 150 to 200 or 250.
- For a detection network, you are advised to set max_percentile to PERCENTILE_MID (indicating 0.99999).
- Modify the search range parameters.
- If the quantization accuracy obtained in Step 3 is as expected, the parameter tuning ends. Otherwise, go to Step 5.
- Traverse the configuration options of the quantization parameters described in Table 2. (You can adjust the search range based on the calibration time requirement.)
Table 2 Parameter Settings Parameter
Configuration Description
quantize_algo
HALF_OFFSET: The data is offset while the weight is not.
weight_type
VECTOR_TYPE: Each filter uses a separate group of quantization parameters.
bin
The statistics histogram is required during the divergence computation. The value of this parameter determines the maximum value of the histogram. If this parameter is not set or set to 0, the default value 150 is used. 100, 150, and 200 are recommended.
type
Different divergence types correspond to different computation methods. The default value is KL.
- KL: Kullback-Leibler Divergence
- SYMKL: Symmetric Kullback-Leibler Divergence
- JSD: Jensen-Shannon Divergence
- start_ratio
- end_ratio
- step_ratio
start_ratio indicates the search start. end_ratio indicates the search end. step_ratio indicates the search step.
The following two sets of configurations are recommended:
- start_ratio: 0.7 end_ratio: 1.3 step_ratio: 0.01
- start_ratio: 0.3 end_ratio: 1.7 step_ratio: 0.01
max_percentile
Maximum number to be considered as the search result among a group of numbers in descending order
1.0 and 0.99999 are recommended.
batch_count
Number of images in the quantization calibration set to be processed
The value can be an integer greater than 1. 10, 20, and 50 are recommended.
- If the quantization accuracy obtained in Step 5 is as expected, the parameter tuning ends. Otherwise, go to Step 7.
- Use the exclude_op parameter to set the quantization operator blacklist. Operators are blacklisted layer by layer from the first layer. Operators in the operator blacklist are not quantized, narrowing down the operators that affect the accuracy.
Only the operators in the blacklist are not quantized. In this case, int8 computation and FP16 computation are not separated.
- If the quantization accuracy obtained in Step 7 is as expected, the parameter tuning ends. Otherwise, it indicates that the quantization does not affect the accuracy, and the quantization configuration is not required. Remove the quantization configuration, and restore the network-wide FP16 computation.
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



