
Overview
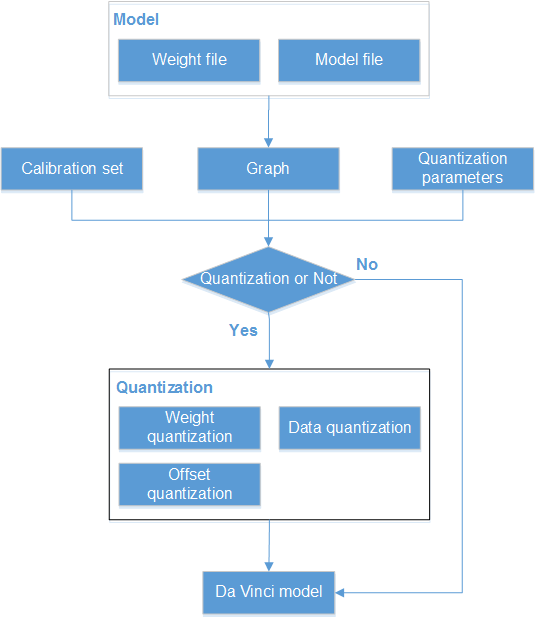
Quantization herein refers to low-bit quantization performed on high-accuracy data, so as to save the network memory usage, reduce the transmission delay, and improve the operation efficiency.
Currently, quantization using the Convolution, Full Connection, and ConvolutionDepthwise operators is supported, including weight, offset, and data quantization. Two quantization modes are supported: non-offset mode and data-offset mode.
The quantized weight and offset are stored in the Da Vinci model during Da Vinci model generation. In model inference, the quantized weight and offset are used for data computation.
The concepts are described as follows:
- Non-offset mode: Both the weight and data are offset.
- Data-offset mode: The data is offset while the weight is not.
- Weight quantification: Performs int8 quantization on the weight file according to the quantization algorithm. In with-offset quantization mode, the int8 weight, scale, and offset are output. In non-offset quantization mode, the int8 weight and scale are output. Currently, only the non-offset quantization mode is supported for weight quantization.
- Data quantification: Performs inference by using limited inputs (a calibration set, used to train quantization parameters and ensure the accuracy). The scale and offset of the quantized data are obtained in the data-offset quantization mode or the scale of the quantized data is obtained in non-offset quantization mode, according to the frequency statistics and divergence algorithm.
- Offset quantization: Quantizes the FP32 offset data into the INT32 output based on the weight-quantized scale and data-quantized scale
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



