
- What's New
- Function Overview
-
Product Bulletin
- Latest Notices
-
Product Change Notices
- EOM of CentOS
- Billing Changes for Huawei Cloud CCE Autopilot Data Plane
- CCE Autopilot for Commercial Use on September 30, 2024, 00:00 GMT+08:00
- Reliability Hardening for Cluster Networks and Storage Functions
- Support for Docker
- Service Account Token Security Improvement
- Upgrade of Helm v2 to Helm v3
- Problems Caused by conn_reuse_mode Settings in the IPVS Forwarding Mode of CCE Clusters
- Optimized Key Authentication of the everest Add-on
-
Cluster Version Release Notes
- End of Maintenance for Clusters 1.25
- End of Maintenance for Clusters 1.23
- End of Maintenance for Clusters 1.21
- End of Maintenance for Clusters 1.19
- End of Maintenance for Clusters 1.17
- End of Maintenance for Clusters 1.15
- End of Maintenance for Clusters 1.13
- Creation of CCE Clusters 1.13 and Earlier Not Supported
- Upgrade for Kubernetes Clusters 1.9
-
Vulnerability Notices
- Vulnerability Fixing Policies
- Notice of Kubernetes Security Vulnerability (CVE-2024-10220)
- Notice of Kubernetes Security Vulnerabilities (CVE-2024-9486 and CVE-2024-9594)
- Notice of Container Escape Vulnerability in NVIDIA Container Toolkit (CVE-2024-0132)
- Notice of Linux Remote Code Execution Vulnerability in CUPS (CVE-2024-47076, CVE-2024-47175, CVE-2024-47176, and CVE-2024-47177)
- Notice of the NGINX Ingress Controller Vulnerability That Allows Attackers to Bypass Annotation Validation (CVE-2024-7646)
- Notice of Docker Engine Vulnerability That Allows Attackers to Bypass AuthZ (CVE-2024-41110)
- Notice of Linux Kernel Privilege Escalation Vulnerability (CVE-2024-1086)
- Notice of OpenSSH Remote Code Execution Vulnerability (CVE-2024-6387)
- Notice of Fluent Bit Memory Corruption Vulnerability (CVE-2024-4323)
- Notice of runC systemd Attribute Injection Vulnerability (CVE-2024-3154)
- Notice of the Impact of runC Vulnerability (CVE-2024-21626)
- Notice of Kubernetes Security Vulnerability (CVE-2022-3172)
- Notice of Privilege Escalation Vulnerability in Linux Kernel openvswitch Module (CVE-2022-2639)
- Notice of nginx-ingress Add-on Security Vulnerability (CVE-2021-25748)
- Notice of nginx-ingress Security Vulnerabilities (CVE-2021-25745 and CVE-2021-25746)
- Notice of containerd Process Privilege Escalation Vulnerability (CVE-2022-24769)
- Notice of CRI-O Container Runtime Engine Arbitrary Code Execution Vulnerability (CVE-2022-0811)
- Notice of Container Escape Vulnerability Caused by the Linux Kernel (CVE-2022-0492)
- Notice of Non-Security Handling Vulnerability of containerd Image Volumes (CVE-2022-23648)
- Notice of Linux Kernel Integer Overflow Vulnerability (CVE-2022-0185)
- Notice of Linux Polkit Privilege Escalation Vulnerability (CVE-2021-4034)
- Notice of Vulnerability of Kubernetes subPath Symlink Exchange (CVE-2021-25741)
- Notice of runC Vulnerability That Allows a Container Filesystem Breakout via Directory Traversal (CVE-2021-30465)
- Notice of Docker Resource Management Vulnerability (CVE-2021-21285)
- Notice of NVIDIA GPU Driver Vulnerability (CVE-2021-1056)
- Notice of the Sudo Buffer Vulnerability (CVE-2021-3156)
- Notice of the Kubernetes Security Vulnerability (CVE-2020-8554)
- Notice of Apache containerd Security Vulnerability (CVE-2020-15257)
- Notice of Docker Engine Input Verification Vulnerability (CVE-2020-13401)
- Notice of Kubernetes kube-apiserver Input Verification Vulnerability (CVE-2020-8559)
- Notice of Kubernetes kubelet Resource Management Vulnerability (CVE-2020-8557)
- Notice of Kubernetes kubelet and kube-proxy Authorization Vulnerability (CVE-2020-8558)
- Notice of Fixing the Kubernetes HTTP/2 Vulnerability
- Notice of Fixing the Linux Kernel SACK Vulnerabilities
- Notice of Fixing the Docker Command Injection Vulnerability (CVE-2019-5736)
- Notice of Fixing the Kubernetes Permission and Access Control Vulnerability (CVE-2018-1002105)
- Notice of Fixing the Kubernetes Dashboard Security Vulnerability (CVE-2018-18264)
-
Product Release Notes
-
Cluster Versions
- Kubernetes Version Policy
-
Kubernetes Version Release Notes
- Kubernetes 1.31 Release Notes
- Kubernetes 1.30 Release Notes
- Kubernetes 1.29 Release Notes
- Kubernetes 1.28 Release Notes
- Kubernetes 1.27 Release Notes
- Kubernetes 1.25 Release Notes
- Kubernetes 1.23 Release Notes
- Kubernetes 1.21 (EOM) Release Notes
- Kubernetes 1.19 (EOM) Release Notes
- Kubernetes 1.17 (EOM) Release Notes
- Kubernetes 1.15 (EOM) Release Notes
- Kubernetes 1.13 (EOM) Release Notes
- Kubernetes 1.11 (EOM) Release Notes
- Kubernetes 1.9 (EOM) and Earlier Versions Release Notes
- Patch Versions
- OS Images
-
Add-on Versions
- CoreDNS Release History
- CCE Container Storage (Everest) Release History
- CCE Node Problem Detector Release History
- Kubernetes Dashboard Release History
- CCE Cluster Autoscaler Release History
- NGINX Ingress Controller Release History
- Kubernetes Metrics Server Release History
- CCE Advanced HPA Release History
- CCE Cloud Bursting Engine for CCI Release History
- CCE AI Suite (NVIDIA GPU) Release History
- CCE AI Suite (Ascend NPU) Release History
- Volcano Scheduler Release History
- CCE Secrets Manager for DEW Release History
- CCE Network Metrics Exporter Release History
- NodeLocal DNSCache Release History
- Cloud Native Cluster Monitoring Release History
- Cloud Native Log Collection Release History
- Container Image Signature Verification Release History
- Grafana Release History
- OpenKruise Release History
- Gatekeeper Release History
- Vertical Pod Autoscaler Release History
- CCE Cluster Backup & Recovery (End of Maintenance) Release History
- Kubernetes Web Terminal (End of Maintenance) Release History
- Prometheus (End of Maintenance) Release History
-
Cluster Versions
- Service Overview
- Billing
- Kubernetes Basics
- Getting Started
-
User Guide
- High-Risk Operations
-
Clusters
- Basic Cluster Information
-
Cluster Version Release Notes
-
Kubernetes Version Release Notes
- Kubernetes 1.31 Release Notes
- Kubernetes 1.30 Release Notes
- Kubernetes 1.29 Release Notes
- Kubernetes 1.28 Release Notes
- Kubernetes 1.27 Release Notes
- Kubernetes 1.25 Release Notes
- Kubernetes 1.23 Release Notes
- Kubernetes 1.21 (EOM) Release Notes
- Kubernetes 1.19 (EOM) Release Notes
- Kubernetes 1.17 (EOM) Release Notes
- Kubernetes 1.15 (EOM) Release Notes
- Kubernetes 1.13 (EOM) Release Notes
- Kubernetes 1.11 (EOM) Release Notes
- Release Notes for Kubernetes 1.9 (EOM) and Earlier Versions
- Patch Version Release Notes
-
Kubernetes Version Release Notes
- Buying a Cluster
- Connecting to a Cluster
-
Managing a Cluster
- Modifying Cluster Configurations
- Enabling Overload Control for a Cluster
- Changing Cluster Scale
- Changing the Default Security Group of a Node
- Deleting a Cluster
- Hibernating or Waking Up a Pay-per-Use Cluster
- Renewing a Yearly/Monthly Cluster
- Changing the Billing Mode of a Cluster from Pay-per-Use to Yearly/Monthly
-
Upgrading a Cluster
- Process and Method of Upgrading a Cluster
- Before You Start
- Performing Post-Upgrade Verification
- Migrating Services Across Clusters of Different Versions
-
Troubleshooting for Pre-upgrade Check Exceptions
- Pre-upgrade Check
- Node Restrictions
- Upgrade Management
- Add-ons
- Helm Charts
- SSH Connectivity of Master Nodes
- Node Pools
- Security Groups
- Residual Nodes
- Discarded Kubernetes Resources
- Compatibility Risks
- CCE Agent Versions
- Node CPU Usage
- CRDs
- Node Disks
- Node DNS
- Node Key Directory File Permissions
- kubelet
- Node Memory
- Node Clock Synchronization Server
- Node OS
- Node CPU Cores
- Node Python Commands
- ASM Version
- Node Readiness
- Node journald
- containerd.sock
- Internal Error
- Node Mount Points
- Kubernetes Node Taints
- Everest Restrictions
- cce-hpa-controller Limitations
- Enhanced CPU Policies
- Health of Worker Node Components
- Health of Master Node Components
- Memory Resource Limit of Kubernetes Components
- Discarded Kubernetes APIs
- NetworkManager
- Node ID File
- Node Configuration Consistency
- Node Configuration File
- CoreDNS Configuration Consistency
- sudo
- Key Node Commands
- Mounting of a Sock File on a Node
- HTTPS Load Balancer Certificate Consistency
- Node Mounting
- Login Permissions of User paas on a Node
- Private IPv4 Addresses of Load Balancers
- Historical Upgrade Records
- CIDR Block of the Cluster Management Plane
- GPU Add-on
- Nodes' System Parameters
- Residual Package Version Data
- Node Commands
- Node Swap
- NGINX Ingress Controller
- Upgrade of Cloud Native Cluster Monitoring
- containerd Pod Restart Risks
- Key GPU Add-on Parameters
- GPU or NPU Pod Rebuild Risks
- ELB Listener Access Control
- Master Node Flavor
- Subnet Quota of Master Nodes
- Node Runtime
- Node Pool Runtime
- Number of Node Images
- OpenKruise Compatibility Check
- Compatibility Check of Secret Encryption
- Compatibility Between the Ubuntu Kernel and GPU Driver
- Drainage Tasks
- Image Layers on a Node
- Cluster Rolling Upgrade
- Rotation Certificates
- Ingress and ELB Configuration Consistency
- Network Policies of Cluster Network Components
- Cluster and Node Pool Configurations
- Time Zone of Master Nodes
-
Nodes
- Node Overview
- Container Engines
- Node OSs
- Node Specifications
- Creating a Node
- Accepting Nodes for Management
- Logging In to a Node
-
Management Nodes
- Managing Node Labels
- Managing Node Taints
- Resetting a Node
- Removing a Node
- Synchronizing the Data of Cloud Servers
- Draining a Node
- Deleting or Unsubscribing from a Node
- Changing the Billing Mode of a Node to Yearly/Monthly
- Modifying the Auto-Renewal Configuration of a Yearly/Monthly Node
- Stopping a Node
- Performing Rolling Upgrade for Nodes
-
Node O&M
- Node Resource Reservation Policy
- Space Allocation of a Data Disk
- Maximum Number of Pods That Can Be Created on a Node
- Differences in kubelet and Runtime Component Configurations Between CCE and the Native Community
- Migrating Nodes from Docker to containerd
- Optimizing Node System Parameters
- Configuring Node Fault Detection Policies
- Executing the Pre- or Post-installation Commands During Node Creation
- ECS Event Handling Suggestions
- Node Pools
-
Workloads
- Overview
- Creating a Workload
-
Configuring a Workload
- Secure Runtime and Common Runtime
- Configuring Time Zone Synchronization
- Configuring an Image Pull Policy
- Using Third-Party Images
- Configuring Container Specifications
- Configuring Container Lifecycle Parameters
- Configuring Container Health Check
- Configuring Environment Variables
- Configuring APM
- Configuring Workload Upgrade Policies
- Configuring Tolerance Policies
- Configuring Labels and Annotations
- Scheduling a Workload
- Logging In to a Container
- Managing Workloads
- Managing Custom Resources
- Pod Security
-
Scheduling
- Overview
- CPU Scheduling
- GPU Scheduling
- NPU Scheduling
- Volcano Scheduling
- Cloud Native Hybrid Deployment
-
Network
- Overview
-
Container Network
- Overview
-
Cloud Native Network 2.0 Settings
- Cloud Native Network 2.0
- Configuring a Default Container Subnet for a CCE Turbo Cluster
- Binding a Security Group to a Pod Using an Annotation
- Binding a Security Group to a Workload Using a Security Group Policy
- Binding a Subnet and Security Group to a Namespace or Workload Using a Container Network Configuration
- Configuring a Static IP Address for a Pod
- Configuring an EIP for a Pod
- Configuring a Static EIP for a Pod
- Configuring Shared Bandwidth for a Pod with IPv6 Dual-Stack ENIs
- VPC Network Settings
- Tunnel Network Settings
- Pod Network Settings
-
Service
- Overview
- ClusterIP
- NodePort
-
LoadBalancer
- Creating a LoadBalancer Service
- Configuring LoadBalancer Services Using Annotations
- Configuring HTTP/HTTPS for a LoadBalancer Service
- Configuring SNI for a LoadBalancer Service
- Configuring HTTP/2 for a LoadBalancer Service
- Configuring an HTTP/HTTPS Header for a LoadBalancer Service
- Configuring Timeout for a LoadBalancer Service
- Configuring TLS for a LoadBalancer Service
- Configuring GZIP Data Compression for a LoadBalancer Service
- Configuring a Blocklist/Trustlist Access Policy for a LoadBalancer Service
- Configuring Health Check on Multiple Ports of a LoadBalancer Service
- Configuring Passthrough Networking for a LoadBalancer Service
- Enabling a LoadBalancer Service to Obtain the Client IP Address
- Configuring a Custom EIP for a LoadBalancer Service
- Configuring a Range of Listening Ports for LoadBalancer Services
- Setting the Pod Ready Status Through the ELB Health Check
- Enabling ICMP Security Group Rules
- DNAT
- Headless Services
-
Ingresses
- Overview
- Comparison Between ELB Ingress and Nginx Ingress
-
LoadBalancer Ingresses
- Creating a LoadBalancer Ingress on the Console
- Creating a LoadBalancer Ingress Using kubectl
- Annotations for Configuring LoadBalancer Ingresses
-
Advanced Setting Examples of LoadBalancer Ingresses
- Configuring an HTTPS Certificate for a LoadBalancer Ingress
- Updating the HTTPS Certificate for a LoadBalancer Ingress
- Configuring SNI for a LoadBalancer Ingress
- Configuring Multiple Forwarding Policies for a LoadBalancer Ingress
- Configuring HTTP/2 for a LoadBalancer Ingress
- Configuring HTTPS Backend Services for a LoadBalancer Ingress
- Configuring gRPC Backend Services for a LoadBalancer Ingress
- Configuring Timeout for a LoadBalancer Ingress
- Configuring a Slow Start for a LoadBalancer Ingress
- Configuring Grayscale Release for a LoadBalancer Ingress
- Configuring a Blocklist/Trustlist Access Policy for a LoadBalancer Ingress
- Configuring a Range of Listening Ports for a LoadBalancer Ingress
- Configuring an HTTP/HTTPS Header for a LoadBalancer Ingress
- Configuring GZIP Data Compression for a LoadBalancer Ingress
- Configuring URL Redirection for a LoadBalancer Ingress
- Configuring URL Rewriting for a LoadBalancer Ingress
- Redirecting HTTP to HTTPS for a LoadBalancer Ingress
- Configuring the Priorities of Forwarding Rules for LoadBalancer Ingresses
- Configuring a Custom Header Forwarding Policy for a LoadBalancer Ingress
- Configuring a Custom EIP for a LoadBalancer Ingress
- Configuring Cross-Origin Access for LoadBalancer Ingresses
- Configuring Advanced Forwarding Rules for a LoadBalancer Ingress
- Configuring Advanced Forwarding Actions for a LoadBalancer Ingress
- Forwarding Policy Priorities of LoadBalancer Ingresses
- Configuring Multiple Ingresses to Use the Same External ELB Port
-
Nginx Ingresses
- Creating an Nginx Ingress on the Console
- Creating an Nginx Ingress Using kubectl
- Annotations for Configuring Nginx Ingresses
-
Advanced Setting Examples of Nginx Ingresses
- Configuring an HTTPS Certificate for an Nginx Ingress
- Configuring Redirection Rules for an Nginx Ingress
- Configuring URL Rewriting Rules for an Nginx Ingress
- Configuring HTTPS Backend Services for an Nginx Ingress
- Configuring gRPC Backend Services for an Nginx Ingress
- Configuring Consistent Hashing for Load Balancing of an Nginx Ingress
- Configuring Application Traffic Mirroring for an Nginx Ingress
- Configuring Cross-Origin Access for Nginx Ingresses
- Nginx Ingress Usage Suggestions
- Optimizing NGINX Ingress Controller in High-Traffic Scenarios
- Configuring an ELB Certificate for NGINX Ingress Controller
- Migrating Data from a Bring-Your-Own Nginx Ingress to a LoadBalancer Ingress
- DNS
- Cluster Network Settings
- Configuring Intra-VPC Access
- Accessing the Internet from a Container
- Storage
- Auto Scaling
-
O&M
- Overview
- Agency Permissions
- Health Center
- Monitoring Center
- Logging
- Alarm Center
- Log Auditing
- O&M FAQ
-
O&M Best Practices
- Cloud Native Cluster Monitoring Is Compatible with Self-Built Prometheus
- Monitoring Custom Metrics Using Cloud Native Cluster Monitoring
- Monitoring Custom Metrics on AOM
- Monitoring Metrics of Master Node Components Using Prometheus
- Monitoring Metrics of NGINX Ingress Controller
- Monitoring Container Network Metrics of CCE Turbo Clusters
- Cloud Native Cost Governance
- Namespaces
- ConfigMaps and Secrets
- Add-ons
- Helm Chart
- Permissions
- Settings
- Storage Management: FlexVolume (Deprecated)
-
Best Practices
- Checklist for Deploying Containerized Applications in the Cloud
- Containerization
- Migration
- DevOps
- Disaster Recovery
-
Security
- Overview
- Configuration Suggestions on CCE Cluster Security
- Configuration Suggestions on CCE Node Security
- Configuration Suggestions on CCE Container Runtime Security
- Configuration Suggestions on CCE Container Security
- Configuration Suggestions on CCE Container Image Security
- Configuration Suggestions on CCE Secret Security
- Configuration Suggestions on CCE Workload Identity Security
- Auto Scaling
- Monitoring
-
Cluster
- Suggestions on CCE Cluster Selection
- Creating an IPv4/IPv6 Dual-Stack Cluster in CCE
- Creating a Custom CCE Node Image
- Executing the Pre- or Post-installation Commands During Node Creation
- Using OBS Buckets to Implement Custom Script Injection During Node Creation
- Connecting to Multiple Clusters Using kubectl
- Selecting a Data Disk for the Node
- Implementing Cost Visualization for a CCE Cluster
- Creating a CCE Turbo Cluster Using a Shared VPC
- Protecting a CCE Cluster Against Overload
- Managing Costs for a Cluster
-
Networking
- Planning CIDR Blocks for a Cluster
- Selecting a Network Model
- Enabling Cross-VPC Network Communications Between CCE Clusters
- Implementing Network Communications Between Containers and IDCs Using VPC and Direct Connect
- Enabling a CCE Cluster to Resolve Domain Names on Both On-Premises IDCs and HUAWEI CLOUD
- Implementing Sticky Session Through Load Balancing
- Obtaining the Client Source IP Address for a Container
- Increasing the Listening Queue Length by Configuring Container Kernel Parameters
- Configuring Passthrough Networking for a LoadBalancer Service
- Accessing an External Network from a Pod
- Deploying Nginx Ingress Controllers Using a Chart
- CoreDNS Configuration Optimization
- Pre-Binding Container ENI for CCE Turbo Clusters
- Connecting a Cluster to the Peer VPC Through an Enterprise Router
- Accessing an IP Address Outside a Cluster That Uses a VPC Network Using Source Pod IP Addresses in the Cluster
-
Storage
- Expanding the Storage Space
- Mounting Object Storage Across Accounts
- Dynamically Creating an SFS Turbo Subdirectory Using StorageClass
- Changing the Storage Class Used by a Cluster of v1.15 from FlexVolume to CSI Everest
- Using Custom Storage Classes
- Scheduling EVS Disks Across AZs Using csi-disk-topology
- Automatically Collecting JVM Dump Files That Exit Unexpectedly Using SFS 3.0
- Deploying Storage Volumes in Multiple AZs
-
Container
- Recommended Configurations for Workloads
- Properly Allocating Container Computing Resources
- Upgrading Pods Without Interrupting Services
- Modifying Kernel Parameters Using a Privileged Container
- Using Init Containers to Initialize an Application
- Setting Time Zone Synchronization
- Configuration Suggestions on Container Network Bandwidth Limit
- Configuring the /etc/hosts File of a Pod Using hostAliases
- Configuring Domain Name Resolution for CCE Containers
- Using Dual-Architecture Images (x86 and Arm) in CCE
- Locating Container Faults Using the Core Dump File
- Configuring Parameters to Delay the Pod Startup in a CCE Turbo Cluster
- Automatically Updating a Workload Version Using SWR Triggers
- Permission
- Release
- Batch Computing
-
API Reference
- Before You Start
- API Overview
- Calling APIs
-
APIs
- API URL
-
Cluster Management
- Creating a Cluster
- Reading a Specified Cluster
- Listing Clusters in a Specified Project
- Updating a Specified Cluster
- Deleting a Cluster
- Hibernating a Cluster
- Waking Up a Cluster
- Obtaining a Cluster Certificate
- Revoking a Cluster Certificate of a User
- Modifying Cluster Specifications
- Querying a Job
- Binding/Unbinding Public API Server Address
- Obtaining Cluster Access Address
- Obtaining a Cluster's Logging Configurations
- Configuring Cluster Logs
- Obtaining the Partition List
- Creating a Partition
- Obtaining Partition Details
- Updating a Partition
-
Node Management
- Creating a Node
- Reading a Specified Node
- Listing All Nodes in a Cluster
- Updating a Specified Node
- Deleting a Node
- Enabling Scale-In Protection for a Node
- Disabling Scale-In Protection for a Node
- Synchronizing Nodes
- Synchronizing Nodes in Batches
- Accepting a Node
- Managing a Node in a Customized Node Pool
- Resetting a Node
- Removing a Node
- Migrating a Node
- Migrating a Node to a Custom Node Pool
- Node Pool Management
- Storage Management
- Add-on Management
-
Cluster Upgrade
- Upgrading a Cluster
- Obtaining Cluster Upgrade Task Details
- Retrying a Cluster Upgrade Task
- Suspending a Cluster Upgrade Task (Deprecated)
- Continuing to Execute a Cluster Upgrade Task (Deprecated)
- Obtaining a List of Cluster Upgrade Task Details
- Pre-upgrade Check
- Obtaining Details About a Pre-upgrade Check Task of a Cluster
- Obtaining a List of Pre-upgrade Check Tasks of a Cluster
- Post-upgrade Check
- Cluster Backup
- Obtaining a List of Cluster Backup Task Details
- Obtaining the Cluster Upgrade Information
- Obtaining a Cluster Upgrade Path
- Obtaining the Configuration of Cluster Upgrade Feature Gates
- Enabling the Cluster Upgrade Process Booting Task
- Obtaining a List of Upgrade Workflows
- Obtaining Details About a Specified Cluster Upgrade Task
- Updating the Status of a Specified Cluster Upgrade Booting Task
- Quota Management
- API Versions
- Tag Management
- Configuration Management
-
Chart Management
- Uploading a Chart
- Obtaining a Chart List
- Obtaining a Release List
- Updating a Chart
- Creating a Release
- Deleting a Chart
- Updating a Release
- Obtaining a Chart
- Deleting a Release
- Downloading a Chart
- Obtaining a Release
- Obtaining Chart Values
- Obtaining Historical Records of a Release
- Obtaining the Quota of a User Chart
-
Add-on Instance Parameters
- CoreDNS
- CCE Container Storage (Everest)
- CCE Node Problem Detector
- Kubernetes Dashboard
- CCE Cluster Autoscaler
- NGINX Ingress Controller
- Kubernetes Metrics Server
- CCE Advanced HPA
- CCE Cloud Bursting Engine for CCI
- CCE AI Suite (NVIDIA GPU)
- CCE AI Suite (Ascend NPU)
- Volcano Scheduler
- CCE Secrets Manager for DEW
- CCE Network Metrics Exporter
- NodeLocal DNSCache
- Cloud Native Cluster Monitoring
- Cloud Native Logging
- Kubernetes APIs
- Out-of-Date APIs
- Permissions and Supported Actions
-
Appendix
- Status Code
- Error Codes
- Obtaining a Project ID
- Obtaining an Account ID
- Specifying Add-ons to Be Installed During Cluster Creation
- How to Obtain Parameters in the API URI
- Creating a VPC and Subnet
- Creating a Key Pair
- Node Flavor Description
- Adding a Salt in the password Field When Creating a Node
- Maximum Number of Pods That Can Be Created on a Node
- Node OS
- Space Allocation of a Data Disk
- Attaching Disks to a Node
- SDK Reference
-
FAQs
- Common FAQ
-
Billing
- How Is CCE Billed?
- How Do I Change the Billing Mode of a CCE Cluster from Pay-per-Use to Yearly/Monthly?
- Can I Change the Billing Mode of CCE Nodes from Pay-per-Use to Yearly/Monthly?
- Which Invoice Modes Are Supported by Huawei Cloud?
- Will I Be Notified When My Balance Is Insufficient?
- Will I Be Notified When My Account Balance Changes?
- Can I Delete a Yearly/Monthly-Billed CCE Cluster Directly When It Expires?
- How Do I Unsubscribe From CCE?
-
Cluster
- Cluster Creation
-
Cluster Running
- How Do I Locate the Fault When a Cluster Is Unavailable?
- How Do I Reset or Reinstall a CCE Cluster?
- How Do I Check Whether a Cluster Is in Multi-Master Mode?
- Can I Directly Connect to the Master Node of a CCE Cluster?
- How Do I Retrieve Data After a CCE Cluster Is Deleted?
- Why Does CCE Display Node Disk Usage Inconsistently with Cloud Eye?
- How Do I Change the Name of a CCE Cluster?
- Cluster Deletion
- Cluster Upgrade
-
Node
- Node Creation
-
Node Running
- What Should I Do If a Cluster Is Available But Some Nodes Are Unavailable?
- How Do I Troubleshoot the Failure to Remotely Log In to a Node in a CCE Cluster?
- How Do I Log In to a Node Using a Password and Reset the Password?
- How Do I Collect Logs of Nodes in a CCE Cluster?
- What Can I Do If the Container Network Becomes Unavailable After yum update Is Used to Upgrade the OS?
- What Should I Do If the vdb Disk of a Node Is Damaged and the Node Cannot Be Recovered After Reset?
- Which Ports Are Used to Install kubelet on CCE Cluster Nodes?
- How Do I Configure a Pod to Use the Acceleration Capability of a GPU Node?
- What Should I Do If I/O Suspension Occasionally Occurs When SCSI EVS Disks Are Used?
- What Should I Do If Excessive Docker Audit Logs Affect the Disk I/O?
- How Do I Fix an Abnormal Container or Node Due to No Thin Pool Disk Space?
- Where Can I Get the Listening Ports of CCE Worker Nodes?
- How Do I Rectify Failures When the NVIDIA Driver Is Used to Start Containers on GPU Nodes?
- What Can I Do If the Time of CCE Nodes Is Not Synchronized with the NTP Server?
- What Should I Do If the Data Disk Usage Is High Because a Large Volume of Data Is Written Into the Log File?
- Why Does My Node Memory Usage Obtained by Running the kubelet top node Command Exceed 100%?
- What Should I Do If "Failed to reclaim image" Is Displayed in the Node Events?
- Specification Change
-
OSs
- What Can I Do If cgroup kmem Leakage Occasionally Occurs When an Application Is Repeatedly Created or Deleted on a Node Running CentOS with an Earlier Kernel Version?
- What Should I Do If There Is a Service Access Failure After a Backend Service Upgrade or a 1-Second Latency When a Service Accesses a CCE Cluster?
- Why Are Pods Evicted by kubelet Due to Abnormal cgroup Statistics?
- When Container OOM Occurs on the CentOS Node with an Earlier Kernel Version, the Ext4 File System Is Occasionally Suspended
- What Should I Do If a DNS Resolution Failure Occurs Due to a Defect in IPVS?
- What Should I Do If the Number of ARP Entries Exceeds the Upper Limit?
- What Should I Do If a VM Is Suspended Due to an EulerOS 2.9 Kernel Defect?
-
Node Pool
- What Should I Do If a Node Pool Is Abnormal?
- What Should I Do If No Node Creation Record Is Displayed When the Node Pool Is Being Expanding?
- What Should I Do If a Node Pool Scale-Out Fails?
- What Should I Do If Some Kubernetes Events Fail to Display After Nodes Were Added to or Deleted from a Node Pool in Batches?
- How Do I Modify ECS Configurations When an ECS Cannot Be Managed by a Node Pool?
-
Workload
-
Workload Exception Troubleshooting
- How Can I Find the Fault for an Abnormal Workload?
- What Should I Do If Pod Scheduling Fails?
- What Should I Do If a Pod Fails to Pull the Image?
- What Should I Do If Container Startup Fails?
- What Should I Do If a Pod Fails to Be Evicted?
- What Should I Do If a Storage Volume Cannot Be Mounted or the Mounting Times Out?
- What Should I Do If a Workload Remains in the Creating State?
- What Should I Do If a Pod Remains in the Terminating State?
- What Should I Do If a Workload Is Stopped Caused by Pod Deletion?
- What Should I Do If an Error Occurs When I Deploy a Service on the GPU Node?
- What Should I Do If a Workload Exception Occurs Due to a Storage Volume Mount Failure?
- Why Does Pod Fail to Write Data?
- Why Is Pod Creation or Deletion Suspended on a Node Where File Storage Is Mounted?
- How Can I Locate Faults Using an Exit Code?
- Container Configuration
- Monitoring Log
-
Scheduling Policies
- How Do I Evenly Distribute Multiple Pods to Each Node?
- How Do I Prevent a Container on a Node from Being Evicted?
- Why Are Pods Not Evenly Distributed on Nodes?
- How Do I Evict All Pods on a Node?
- How Do I Check Whether a Pod Is Bound with vCPUs?
- What Should I Do If Pods Cannot Be Rescheduled After the Node Is Stopped?
- How Do I Prevent a Non-GPU or Non-NPU Workload from Being Scheduled to a GPU or NPU Node?
- Why Cannot a Pod Be Scheduled to a Node?
-
Others
- What Should I Do If a Cron Job Cannot Be Restarted After Being Stopped for a Period of Time?
- What Is a Headless Service When I Create a StatefulSet?
- What Should I Do If Error Message "Auth is empty" Is Displayed When a Private Image Is Pulled?
- What Is the Image Pull Policy for Containers in a CCE Cluster?
- Why Is the Mount Point of a Docker Container in the Kunpeng Cluster Uninstalled?
- What Can I Do If a Layer Is Missing During Image Pull?
- Why the File Permission and User in the Container Are Question Marks?
-
Workload Exception Troubleshooting
-
Networking
-
Network Exception Troubleshooting
- How Do I Locate a Workload Networking Fault?
- Why the ELB Address Cannot Be used to Access Workloads in a Cluster?
- Why the Ingress Cannot Be Accessed Outside the Cluster?
- Why Does the Browser Return Error Code 404 When I Access a Deployed Application?
- What Should I Do If a Container Fails to Access the Internet?
- What Can I Do If a VPC Subnet Cannot Be Deleted?
- How Do I Restore a Faulty Container NIC?
- What Should I Do If a Node Fails to Connect to the Internet (Public Network)?
- How Do I Resolve a Conflict Between the VPC CIDR Block and the Container CIDR Block?
- What Should I Do If the Java Error "Connection reset by peer" Is Reported During Layer-4 ELB Health Check
- How Do I Locate the Service Event Indicating That No Node Is Available for Binding?
- Why Does "Dead loop on virtual device gw_11cbf51a, fix it urgently" Intermittently Occur When I Log In to a VM using VNC?
- Why Does a Panic Occasionally Occur When I Use Network Policies on a Cluster Node?
- Why Are Lots of source ip_type Logs Generated on the VNC?
- What Should I Do If Status Code 308 Is Displayed When the Nginx Ingress Controller Is Accessed Using the Internet Explorer?
- What Should I Do If Nginx Ingress Access in the Cluster Is Abnormal After the NGINX Ingress Controller Add-on Is Upgraded?
- What Should I Do If An Error Occurred During a LoadBalancer Update?
- What Could Cause Access Exceptions After Configuring an HTTPS Certificate for a LoadBalancer Ingress?
-
Network Planning
- What Is the Relationship Between Clusters, VPCs, and Subnets?
- How Do I View the VPC CIDR Block?
- How Do I Set the VPC CIDR Block and Subnet CIDR Block for a CCE Cluster?
- How Do I Set a Container CIDR Block for a CCE Cluster?
- When Should I Use Cloud Native Network 2.0?
- What Is an ENI?
- How Can I Configure a Security Group Rule in a Cluster?
- How Do I Configure the IPv6 Service CIDR Block When Creating a CCE Turbo Cluster?
- Can Multiple NICs Be Bound to a Node in a CCE Cluster?
- Security Hardening
-
Network Configuration
- How Does CCE Communicate with Other Huawei Cloud Services over an Intranet?
- How Do I Set the Port When Configuring the Workload Access Mode on CCE?
- How Can I Achieve Compatibility Between Ingress's property and Kubernetes client-go?
- How Do I Obtain the Actual Source IP Address of a Client After a Service Is Added into Istio?
- Why Cannot an Ingress Be Created After the Namespace Is Changed?
- Why Is the Backend Server Group of an ELB Automatically Deleted After a Service Is Published to the ELB?
- How Can Container IP Addresses Survive a Container Restart?
- How Can I Check Whether an ENI Is Used by a Cluster?
- How Can I Delete a Security Group Rule Associated with a Deleted Subnet?
- How Can I Synchronize Certificates When Multiple Ingresses in Different Namespaces Share a Listener?
- How Can I Determine Which Ingress the Listener Settings Have Been Applied To?
-
Network Exception Troubleshooting
-
Storage
- How Do I Expand the Storage Capacity of a Container?
- What Are the Differences Among CCE Storage Classes in Terms of Persistent Storage and Multi-Node Mounting?
- Can I Create a CCE Node Without Adding a Data Disk to the Node?
- Can EVS Volumes in a CCE Cluster Be Restored After They Are Deleted or Expired?
- What Should I Do If the Host Cannot Be Found When Files Need to Be Uploaded to OBS During the Access to the CCE Service from a Public Network?
- How Can I Achieve Compatibility Between ExtendPathMode and Kubernetes client-go?
- What Can I Do If a Storage Volume Fails to Be Created?
- Can CCE PVCs Detect Underlying Storage Faults?
- An Error Is Reported When the Owner Group and Permissions of the Mount Point of the SFS 3.0 File System in the OS Are Modified
- Why Cannot I Delete a PV or PVC Using the kubectl delete Command?
- What Should I Do If "target is busy" Is Displayed When a Pod with Cloud Storage Mounted Is Being Deleted?
- What Should I Do If a Yearly/Monthly EVS Disk Cannot Be Automatically Created?
- Namespace
-
Chart and Add-on
- What Should I Do If the nginx-ingress Add-on Fails to Be Installed on a Cluster and Remains in the Creating State?
- What Should I Do If Residual Process Resources Exist Due to an Earlier npd Add-on Version?
- What Should I Do If a Chart Release Cannot Be Deleted Because the Chart Format Is Incorrect?
- Does CCE Support nginx-ingress?
- What Should I Do If Installation of an Add-on Fails and "The release name is already exist" Is Displayed?
- What Should I Do If a Release Creation or Upgrade Fails and "rendered manifests contain a resource that already exists" Is Displayed?
- What Can I Do If the kube-prometheus-stack Add-on Instance Fails to Be Scheduled?
- What Can I Do If a Chart Fails to Be Uploaded?
- How Do I Configure the Add-on Resource Quotas Based on Cluster Scale?
- How Can I Clean Up Residual Resources After the NGINX Ingress Controller Add-on in the Unknown State Is Deleted?
- Why TLS v1.0 and v1.1 Cannot Be Used After the NGINX Ingress Controller Add-on Is Upgraded?
-
API & kubectl FAQs
- How Can I Access a Cluster API Server?
- Can the Resources Created Using APIs or kubectl Be Displayed on the CCE Console?
- How Do I Download kubeconfig for Connecting to a Cluster Using kubectl?
- How Do I Rectify the Error Reported When Running the kubectl top node Command?
- Why Is "Error from server (Forbidden)" Displayed When I Use kubectl?
-
DNS FAQs
- What Should I Do If Domain Name Resolution Fails in a CCE Cluster?
- Why Does a Container in a CCE Cluster Fail to Perform DNS Resolution?
- Why Cannot the Domain Name of the Tenant Zone Be Resolved After the Subnet DNS Configuration Is Modified?
- How Do I Optimize the Configuration If the External Domain Name Resolution Is Slow or Times Out?
- How Do I Configure a DNS Policy for a Container?
- Image Repository FAQs
- Permissions
- Related Services
- Videos
-
More Documents
-
User Guide (ME-Abu Dhabi Region)
- Service Overview
- Getting Started
- High-Risk Operations and Solutions
-
Clusters
- Cluster Overview
- Buying a Cluster
- Connecting to a Cluster
-
Upgrading a Cluster
- Upgrade Overview
- Before You Start
- Performing an In-place Upgrade
- Performing Post-Upgrade Verification
- Migrating Services Across Clusters of Different Versions
-
Troubleshooting for Pre-upgrade Check Exceptions
- Pre-upgrade Check
- Node Restrictions
- Upgrade Management
- Add-ons
- Helm Charts
- SSH Connectivity of Master Nodes
- Node Pools
- Security Groups
- Arm Node Restrictions
- To-Be-Migrated Nodes
- Discarded Kubernetes Resources
- Compatibility Risks
- Node CCE Agent Versions
- Node CPU Usage
- CRDs
- Node Disks
- Node DNS
- Node Key Directory File Permissions
- Kubelet
- Node Memory
- Node Clock Synchronization Server
- Node OS
- Node CPUs
- Node Python Commands
- ASM Version
- Node Readiness
- Node journald
- containerd.sock
- Internal Errors
- Node Mount Points
- Kubernetes Node Taints
- Everest Restrictions
- cce-hpa-controller Restrictions
- Enhanced CPU Policies
- Health of Worker Node Components
- Health of Master Node Components
- Memory Resource Limit of Kubernetes Components
- Discarded Kubernetes APIs
- IPv6 Capabilities of a CCE Turbo Cluster
- Node NetworkManager
- Node ID File
- Node Configuration Consistency
- Node Configuration File
- CoreDNS Configuration Consistency
- sudo Commands of a Node
- Key Commands of Nodes
- Mounting of a Sock File on a Node
- HTTPS Load Balancer Certificate Consistency
- Node Mounting
- Login Permissions of User paas on a Node
- Private IPv4 Addresses of Load Balancers
- Historical Upgrade Records
- CIDR Block of the Cluster Management Plane
- GPU Add-on
- Nodes' System Parameter Settings
- Residual Package Versions
- Node Commands
- Node Swap
- nginx-ingress Upgrade
- Managing a Cluster
- Nodes
- Node Pools
-
Workloads
- Overview
- Creating a Workload
-
Configuring a Container
- Configuring Time Zone Synchronization
- Configuring an Image Pull Policy
- Using Third-Party Images
- Configuring Container Specifications
- Configuring Container Lifecycle Parameters
- Configuring Container Health Check
- Configuring Environment Variables
- Configuring APM Settings for Performance Bottleneck Analysis
- Workload Upgrade Policies
- Scheduling Policies (Affinity/Anti-affinity)
- Taints and Tolerations
- Labels and Annotations
- Accessing a Container
- Managing Workloads and Jobs
- Kata Runtime and Common Runtime
- Scheduling
-
Network
- Overview
- Container Network Models
-
Service
- Overview
- ClusterIP
- NodePort
-
LoadBalancer
- Creating a LoadBalancer Service
- Using Annotations to Configure Load Balancing
- Service Using HTTP or HTTPS
- Configuring Health Check for Multiple Ports
- Setting the Pod Ready Status Through the ELB Health Check
- Configuring Timeout for a LoadBalancer Service
- Enabling Passthrough Networking for LoadBalancer Services
- Enabling ICMP Security Group Rules
- DNAT
- Headless Service
-
Ingresses
- Overview
-
ELB Ingresses
- Creating an ELB Ingress on the Console
- Using kubectl to Create an ELB Ingress
- Configuring ELB Ingresses Using Annotations
- Configuring HTTPS Certificates for ELB Ingresses
- Configuring the Server Name Indication (SNI) for ELB Ingresses
- ELB Ingresses Routing to Multiple Services
- ELB Ingresses Using HTTP/2
- Interconnecting ELB Ingresses with HTTPS Backend Services
- Configuring Timeout for an ELB Ingress
-
Nginx Ingresses
- Creating Nginx Ingresses on the Console
- Using kubectl to Create an Nginx Ingress
- Configuring Nginx Ingresses Using Annotations
- Configuring HTTPS Certificates for Nginx Ingresses
- Configuring URL Rewriting Rules for Nginx Ingresses
- Interconnecting Nginx Ingresses with HTTPS Backend Services
- Nginx Ingresses Using Consistent Hashing for Load Balancing
- DNS
- Container Network Settings
- Cluster Network Settings
- Configuring Intra-VPC Access
- Accessing Public Networks from a Container
- Storage
- Observability
- Namespaces
- ConfigMaps and Secrets
- Auto Scaling
-
Add-ons
- Overview
- CoreDNS
- CCE Container Storage (Everest)
- CCE Node Problem Detector
- Kubernetes Dashboard
- CCE Cluster Autoscaler
- Nginx Ingress Controller
- Kubernetes Metrics Server
- CCE Advanced HPA
- CCE AI Suite (NVIDIA GPU)
- CCE AI Suite (Ascend NPU)
- Volcano Scheduler
- CCE Secrets Manager for DEW
- CCE Network Metrics Exporter
- NodeLocal DNSCache
- Prometheus
- Helm Chart
- Permissions
-
Best Practices
- Checklist for Deploying Containerized Applications in the Cloud
- Containerization
- Disaster Recovery
- Security
- Auto Scaling
- Monitoring
- Cluster
- Networking
- Storage
- Container
- Permission
- Release
-
FAQs
- Common Questions
- Cluster
-
Node
- Node Creation
-
Node Running
- What Should I Do If a Cluster Is Available But Some Nodes Are Unavailable?
- How Do I Log In to a Node Using a Password and Reset the Password?
- How Do I Collect Logs of Nodes in a CCE Cluster?
- What Should I Do If the vdb Disk of a Node Is Damaged and the Node Cannot Be Recovered After Reset?
- What Should I Do If I/O Suspension Occasionally Occurs When SCSI EVS Disks Are Used?
- How Do I Fix an Abnormal Container or Node Due to No Thin Pool Disk Space?
- How Do I Rectify Failures When the NVIDIA Driver Is Used to Start Containers on GPU Nodes?
- Specification Change
- Node Pool
-
Workload
-
Workload Abnormalities
- How Do I Use Events to Fix Abnormal Workloads?
- What Should I Do If Pod Scheduling Fails?
- What Should I Do If a Pod Fails to Pull the Image?
- What Should I Do If Container Startup Fails?
- What Should I Do If a Pod Fails to Be Evicted?
- What Should I Do If a Storage Volume Cannot Be Mounted or the Mounting Times Out?
- What Should I Do If a Workload Remains in the Creating State?
- What Should I Do If Pods in the Terminating State Cannot Be Deleted?
- What Should I Do If a Workload Is Stopped Caused by Pod Deletion?
- What Should I Do If an Error Occurs When Deploying a Service on the GPU Node?
-
Container Configuration
- When Is Pre-stop Processing Used?
- How Do I Set an FQDN for Accessing a Specified Container in the Same Namespace?
- What Should I Do If Health Check Probes Occasionally Fail?
- How Do I Set the umask Value for a Container?
- What Can I Do If an Error Is Reported When a Deployed Container Is Started After the JVM Startup Heap Memory Parameter Is Specified for ENTRYPOINT in Dockerfile?
- What Is the Retry Mechanism When CCE Fails to Start a Pod?
- Scheduling Policies
-
Others
- What Should I Do If a Scheduled Task Cannot Be Restarted After Being Stopped for a Period of Time?
- What Is a Headless Service When I Create a StatefulSet?
- What Should I Do If Error Message "Auth is empty" Is Displayed When a Private Image Is Pulled?
- Why Cannot a Pod Be Scheduled to a Node?
- What Is the Image Pull Policy for Containers in a CCE Cluster?
- What Can I Do If a Layer Is Missing During Image Pull?
-
Workload Abnormalities
- Networking
-
Storage
- What Are the Differences Among CCE Storage Classes in Terms of Persistent Storage and Multi-node Mounting?
- Can I Add a Node Without a Data Disk?
- What Should I Do If the Host Cannot Be Found When Files Need to Be Uploaded to OBS During the Access to the CCE Service from a Public Network?
- How Can I Achieve Compatibility Between ExtendPathMode and Kubernetes client-go?
- Can CCE PVCs Detect Underlying Storage Faults?
- Namespace
- Chart and Add-on
-
API & kubectl FAQs
- How Can I Access a CCE Cluster?
- Can the Resources Created Using APIs or kubectl Be Displayed on the CCE Console?
- How Do I Download kubeconfig for Connecting to a Cluster Using kubectl?
- How Do I Rectify the Error Reported When Running the kubectl top node Command?
- Why Is "Error from server (Forbidden)" Displayed When I Use kubectl?
- DNS FAQs
- Image Repository FAQs
- Permissions
- Reference
-
API Reference (ME-Abu Dhabi Region)
- Before You Start
- API Overview
- Calling APIs
-
APIs
- API URL
-
Cluster Management
- Creating a Cluster
- Reading a Specified Cluster
- Listing Clusters in a Specified Project
- Updating a Specified Cluster
- Deleting a Cluster
- Hibernating a Cluster
- Waking Up a Cluster
- Obtaining a Cluster Certificate
- Querying a Job
- Binding/Unbinding Public API Server Address
- Obtaining Cluster Access Address
- Node Management
- Node Pool Management
- Storage Management
- Add-on Management
- Quota Management
- API Versions
- Kubernetes APIs
- Permissions Policies and Supported Actions
-
Appendix
- Status Code
- Error Codes
- Obtaining a Project ID
- Obtaining the Account ID
- Specifying Add-ons to Be Installed During Cluster Creation
- How to Obtain Parameters in the API URI
- Creating a VPC and Subnet
- Creating a Key Pair
- Node Flavor Description
- Adding a Salt in the password Field When Creating a Node
- Maximum Number of Pods That Can Be Created on a Node
- Node OS
- Data Disk Space Allocation
- Attaching Disks to a Node
- Change History
-
User Guide (Paris Regions)
- Service Overview
-
Product Bulletin
- Risky Operations on Cluster Nodes
- CCE Security Guide
- Cluster Node OS Patch Notes
-
Vulnerability Notice
- Notice on the Kubernetes Security Vulnerability (CVE-2022-3172)
- Privilege Escalation Vulnerability in Linux openvswitch Kernel Module (CVE-2022-2639)
- Notice on CRI-O Container Runtime Engine Arbitrary Code Execution Vulnerability (CVE-2022-0811)
- Notice on the Container Escape Vulnerability Caused by the Linux Kernel (CVE-2022-0492)
- Linux Kernel Integer Overflow Vulnerability (CVE-2022-0185)
- Kubernetes Basics
- Getting Started
- High-Risk Operations and Solutions
-
Clusters
- Cluster Overview
- Creating a Cluster
- Connecting to a Cluster
-
Upgrading a Cluster
- Upgrade Overview
- Before You Start
- Performing In-place Upgrade
- Performing Post-Upgrade Verification
- Migrating Services Across Clusters of Different Versions
-
Troubleshooting for Pre-upgrade Check Exceptions
- Pre-upgrade Check
- Node Restrictions
- Upgrade Management
- Add-ons
- Helm Charts
- SSH Connectivity of Master Nodes
- Node Pools
- Security Groups
- Arm Node Restrictions
- To-Be-Migrated Nodes
- Discarded Kubernetes Resources
- Compatibility Risks
- Node CCE Agent Versions
- Node CPU Usage
- CRDs
- Node Disks
- Node DNS
- Node Key Directory File Permissions
- Kubelet
- Node Memory
- Node Clock Synchronization Server
- Node OS
- Node CPUs
- Node Python Commands
- ASM Version
- Node Readiness
- Node journald
- containerd.sock
- Internal Errors
- Node Mount Points
- Kubernetes Node Taints
- everest Restrictions
- cce-hpa-controller Restrictions
- Enhanced CPU Policies
- Health of Worker Node Components
- Health of Master Node Components
- Memory Resource Limit of Kubernetes Components
- Discarded Kubernetes APIs
- IPv6 Capabilities of a CCE Turbo Cluster
- Node NetworkManager
- Node ID File
- Node Configuration Consistency
- Node Configuration File
- CoreDNS Configuration Consistency
- sudo Commands of a Node
- Key Commands of Nodes
- Mounting of a Sock File on a Node
- HTTPS Load Balancer Certificate Consistency
- Node Mounting
- Login Permissions of User paas on a Node
- Private IPv4 Addresses of Load Balancers
- Historical Upgrade Records
- CIDR Block of the Cluster Management Plane
- GPU Add-on
- Nodes' System Parameter Settings
- Residual Package Versions
- Node Commands
- Node Swap
- nginx-ingress Upgrade
- Managing a Cluster
- Nodes
- Node Pools
-
Workloads
- Overview
- Creating a Workload
-
Configuring a Container
- Configuring Time Zone Synchronization
- Configuring an Image Pull Policy
- Using Third-Party Images
- Setting Container Specifications
- Setting Container Lifecycle Parameters
- Setting Health Check for a Container
- Setting an Environment Variable
- Configuring the Workload Upgrade Policy
- Scheduling Policy (Affinity/Anti-affinity)
- Taints and Tolerations
- Labels and Annotations
- Accessing a Container
- Managing Workloads and Jobs
- Scheduling
-
Network
- Overview
- Container Network Models
- Service
-
Ingresses
- Overview
-
ELB Ingresses
- Creating an ELB Ingress on the Console
- Using kubectl to Create an ELB Ingress
- Configuring ELB Ingresses Using Annotations
- Configuring HTTPS Certificates for ELB Ingresses
- Configuring the Server Name Indication (SNI) for ELB Ingresses
- ELB Ingresses Routing to Multiple Services
- ELB Ingresses Using HTTP/2
- Interconnecting ELB Ingresses with HTTPS Backend Services
- Configuring Timeout for an ELB Ingress
-
Nginx Ingresses
- Creating Nginx Ingresses on the Console
- Using kubectl to Create an Nginx Ingress
- Configuring HTTPS Certificates for Nginx Ingresses
- Configuring URL Rewriting Rules for Nginx Ingresses
- Interconnecting Nginx Ingresses with HTTPS Backend Services
- Nginx Ingresses Using Consistent Hashing for Load Balancing
- Configuring Nginx Ingresses Using Annotations
- DNS
- Container Network Settings
- Cluster Network Settings
- Configuring Intra-VPC Access
- Accessing Public Networks from a Container
- Storage
- Observability
- Namespaces
- ConfigMaps and Secrets
- Auto Scaling
- Add-ons
- Helm Chart
- Permissions
-
FAQs
- Common Questions
- Billing
- Cluster
-
Node
- Node Creation
-
Node Running
- What Should I Do If a Cluster Is Available But Some Nodes Are Unavailable?
- How Do I Log In to a Node Using a Password and Reset the Password?
- How Do I Collect Logs of Nodes in a CCE Cluster?
- What Should I Do If the vdb Disk of a Node Is Damaged and the Node Cannot Be Recovered After Reset?
- What Should I Do If I/O Suspension Occasionally Occurs When SCSI EVS Disks Are Used?
- How Do I Fix an Abnormal Container or Node Due to No Thin Pool Disk Space?
- How Do I Rectify Failures When the NVIDIA Driver Is Used to Start Containers on GPU Nodes?
- Specification Change
- Node Pool
-
Workload
-
Workload Abnormalities
- How Do I Use Events to Fix Abnormal Workloads?
- What Should I Do If Pod Scheduling Fails?
- What Should I Do If a Pod Fails to Pull the Image?
- What Should I Do If Container Startup Fails?
- What Should I Do If a Pod Fails to Be Evicted?
- What Should I Do If a Storage Volume Cannot Be Mounted or the Mounting Times Out?
- What Should I Do If a Workload Remains in the Creating State?
- What Should I Do If Pods in the Terminating State Cannot Be Deleted?
- What Should I Do If a Workload Is Stopped Caused by Pod Deletion?
- What Should I Do If an Error Occurs When Deploying a Service on the GPU Node?
- What Should I Do If Sandbox-Related Errors Are Reported When the Pod Remains in the Creating State?
-
Container Configuration
- When Is Pre-stop Processing Used?
- How Do I Set an FQDN for Accessing a Specified Container in the Same Namespace?
- What Should I Do If Health Check Probes Occasionally Fail?
- How Do I Set the umask Value for a Container?
- What Can I Do If an Error Is Reported When a Deployed Container Is Started After the JVM Startup Heap Memory Parameter Is Specified for ENTRYPOINT in Dockerfile?
- What Is the Retry Mechanism When CCE Fails to Start a Pod?
- Scheduling Policies
-
Others
- What Should I Do If a Scheduled Task Cannot Be Restarted After Being Stopped for a Period of Time?
- What Is a Headless Service When I Create a StatefulSet?
- What Should I Do If Error Message "Auth is empty" Is Displayed When a Private Image Is Pulled?
- Why Cannot a Pod Be Scheduled to a Node?
- What Is the Image Pull Policy for Containers in a CCE Cluster?
- What Can I Do If a Layer Is Missing During Image Pull?
-
Workload Abnormalities
-
Networking
- Network Planning
-
Network Fault
- How Do I Locate a Workload Networking Fault?
- Why Does the Browser Return Error Code 404 When I Access a Deployed Application?
- What Should I Do If a Container Fails to Access the Internet?
- What Should I Do If a Node Fails to Connect to the Internet (Public Network)?
- What Should I Do If an Nginx Ingress Access in the Cluster Is Abnormal After the Add-on Is Upgraded?
-
Storage
- What Are the Differences Among CCE Storage Classes in Terms of Persistent Storage and Multi-node Mounting?
- Can I Add a Node Without a Data Disk?
- What Should I Do If the Host Cannot Be Found When Files Need to Be Uploaded to OBS During the Access to the CCE Service from a Public Network?
- How Can I Achieve Compatibility Between ExtendPathMode and Kubernetes client-go?
- Can CCE PVCs Detect Underlying Storage Faults?
- Namespace
- Chart and Add-on
-
API & kubectl FAQs
- How Can I Access a Cluster API Server?
- Can the Resources Created Using APIs or kubectl Be Displayed on the CCE Console?
- How Do I Download kubeconfig for Connecting to a Cluster Using kubectl?
- How Do I Rectify the Error Reported When Running the kubectl top node Command?
- Why Is "Error from server (Forbidden)" Displayed When I Use kubectl?
- DNS FAQs
- Image Repository FAQs
- Permissions
- Reference
-
Best Practices
- Checklist for Deploying Containerized Applications in the Cloud
- Containerization
- Disaster Recovery
- Security
- Auto Scaling
- Monitoring
- Cluster
- Networking
-
Storage
- Expanding the Storage Space
- Mounting an Object Storage Bucket of a Third-Party Tenant
- Dynamically Creating and Mounting Subdirectories of an SFS Turbo File System
- How Do I Change the Storage Class Used by a Cluster of v1.15 from FlexVolume to CSI Everest?
- Custom Storage Classes
- Enabling Automatic Topology for EVS Disks When Nodes Are Deployed in Different AZs (csi-disk-topology)
- Container
- Permission
- Release
- Migrating Data from CCE 1.0 to CCE 2.0
-
API Reference (Paris Regions)
- Before You Start
- API Overview
- Calling APIs
-
APIs
- API URL
-
Cluster Management
- Creating a Cluster
- Reading a Specified Cluster
- Listing Clusters in a Specified Project
- Updating a Specified Cluster
- Deleting a Cluster
- Hibernating a Cluster
- Waking Up a Cluster
- Obtaining a Cluster Certificate
- Querying a Job
- Binding/Unbinding Public API Server Address
- Obtaining Cluster Access Address
- Node Management
- Node Pool Management
- Add-on Management
- Quota Management
- API Versions
- Kubernetes APIs
- Permissions Policies and Supported Actions
-
Appendix
- Status Code
- Error Codes
- Obtaining a Project ID
- Obtaining the Account ID
- Specifying Add-ons to Be Installed During Cluster Creation
- How to Obtain Parameters in the API URI
- Creating a VPC and Subnet
- Creating a Key Pair
- Node Flavor Description
- Adding a Salt in the password Field When Creating a Node
- Maximum Number of Pods That Can Be Created on a Node
- Node OS
- Data Disk Space Allocation
- Attaching Disks to a Node
- Change History
-
User Guide (Kuala Lumpur Region)
- Service Overview
- CCE Console Upgrade
- Getting Started
- High-Risk Operations
-
Clusters
- Cluster Overview
- Buying a Cluster
- Connecting to a Cluster
- Managing a Cluster
-
Upgrading a Cluster
- Process and Method of Upgrading a Cluster
- Before You Start
- Performing Post-Upgrade Verification
- Migrating Services Across Clusters of Different Versions
-
Troubleshooting for Pre-upgrade Check Exceptions
- Pre-upgrade Check
- Node Restrictions
- Upgrade Management
- Add-ons
- Helm Charts
- SSH Connectivity of Master Nodes
- Node Pools
- Security Groups
- Arm Node Restrictions
- Residual Nodes
- Discarded Kubernetes Resources
- Compatibility Risks
- CCE Agent Versions
- Node CPU Usage
- CRDs
- Node Disks
- Node DNS
- Node Key Directory File Permissions
- kubelet
- Node Memory
- Node Clock Synchronization Server
- Node OS
- Node CPUs
- Node Python Commands
- ASM Version
- Node Readiness
- Node journald
- containerd.sock
- Internal Errors
- Node Mount Points
- Kubernetes Node Taints
- Everest Restrictions
- cce-hpa-controller Restrictions
- Enhanced CPU Policies
- Health of Worker Node Components
- Health of Master Node Components
- Memory Resource Limit of Kubernetes Components
- Discarded Kubernetes APIs
- NetworkManager
- Node ID File
- Node Configuration Consistency
- Node Configuration File
- CoreDNS Configuration Consistency
- sudo
- Key Node Commands
- Mounting of a Sock File on a Node
- HTTPS Load Balancer Certificate Consistency
- Node Mounting
- Login Permissions of User paas on a Node
- Private IPv4 Addresses of Load Balancers
- Historical Upgrade Records
- CIDR Block of the Cluster Management Plane
- GPU Add-on
- Nodes' System Parameters
- Residual Package Version Data
- Node Commands
- Node Swap
- nginx-ingress Upgrade
- Upgrade of Cloud Native Cluster Monitoring
- containerd Pod Restart Risks
- Key GPU Add-on Parameters
- GPU or NPU Pod Rebuild Risks
- ELB Listener Access Control
- Master Node Flavor
- Subnet Quota of Master Nodes
- Node Runtime
- Node Pool Runtime
- Number of Node Images
- Nodes
- Node Pools
-
Workloads
- Overview
- Creating a Workload
-
Configuring a Workload
- Configuring Time Zone Synchronization
- Configuring an Image Pull Policy
- Using Third-Party Images
- Configuring Container Specifications
- Configuring Container Lifecycle Parameters
- Configuring Container Health Check
- Configuring Environment Variables
- Configuring Workload Upgrade Policies
- Scheduling Policies (Affinity/Anti-affinity)
- Configuring Tolerance Policies
- Configuring Labels and Annotations
- Logging In to a Container
- Managing Workloads
- Managing Custom Resources
- Pod Security
- Scheduling
-
Network
- Overview
- Container Network
-
Service
- Overview
- ClusterIP
- NodePort
-
LoadBalancer
- Creating a LoadBalancer Service
- Using Annotations to Balance Load
- Configuring HTTP/HTTPS for a LoadBalancer Service
- Configuring SNI for a LoadBalancer Service
- Configuring HTTP/2 for a LoadBalancer Service
- Configuring Timeout for a LoadBalancer Service
- Configuring Health Check on Multiple Ports of a LoadBalancer Service
- Configuring Passthrough Networking for a LoadBalancer Service
- Enabling ICMP Security Group Rules
- DNAT
- Headless Services
-
Ingresses
- Overview
-
LoadBalancer Ingresses
- Creating a LoadBalancer Ingress on the Console
- Using kubectl to Create a LoadBalancer Ingress
- Configuring a LoadBalancer Ingress Using Annotations
- Configuring an HTTPS Certificate for a LoadBalancer Ingress
- Configuring SNI for a LoadBalancer Ingress
- Routing a LoadBalancer Ingress to Multiple Services
- Configuring HTTP/2 for a LoadBalancer Ingress
- Configuring HTTPS Backend Services for a LoadBalancer Ingress
- Configuring Timeout for a LoadBalancer Ingress
-
Nginx Ingresses
- Creating Nginx Ingresses on the Console
- Using kubectl to Create an Nginx Ingress
- Configuring Nginx Ingresses Using Annotations
- Configuring an HTTPS Certificate for an Nginx Ingress
- Configuring HTTPS Backend Services for an Nginx Ingress
- Configuring Consistent Hashing for Load Balancing of an Nginx Ingress
- DNS
- Configuring Intra-VPC Access
- Accessing the Internet from a Container
- Storage
- Observability
- Auto Scaling
- Namespaces
- ConfigMaps and Secrets
- Add-ons
- Helm Chart
- Permissions
-
Best Practices
- Checklist for Deploying Containerized Applications in the Cloud
- Containerization
- Disaster Recovery
- Security
- Auto Scaling
- Monitoring
- Cluster
- Networking
- Storage
- Container
- Permission
- Release
-
FAQs
- Common Questions
- Cluster
-
Node
- Node Creation
-
Node Running
- What Should I Do If a Cluster Is Available But Some Nodes Are Unavailable?
- How Do I Log In to a Node Using a Password and Reset the Password?
- How Do I Collect Logs of Nodes in a CCE Cluster?
- What Should I Do If the vdb Disk of a Node Is Damaged and the Node Cannot Be Recovered After Reset?
- What Should I Do If I/O Suspension Occasionally Occurs When SCSI EVS Disks Are Used?
- How Do I Fix an Abnormal Container or Node Due to No Thin Pool Disk Space?
- How Do I Rectify Failures When the NVIDIA Driver Is Used to Start Containers on GPU Nodes?
- Specification Change
- OSs
- Node Pool
-
Workload
-
Workload Abnormalities
- How Do I Use Events to Fix Abnormal Workloads?
- What Should I Do If Pod Scheduling Fails?
- What Should I Do If a Pod Fails to Pull the Image?
- What Should I Do If Container Startup Fails?
- What Should I Do If a Pod Fails to Be Evicted?
- What Should I Do If a Storage Volume Cannot Be Mounted or the Mounting Times Out?
- What Should I Do If a Workload Remains in the Creating State?
- What Should I Do If Pods in the Terminating State Cannot Be Deleted?
- What Should I Do If a Workload Is Stopped Caused by Pod Deletion?
- What Should I Do If an Error Occurs When Deploying a Service on the GPU Node?
- Container Configuration
- Scheduling Policies
-
Others
- What Should I Do If a Scheduled Task Cannot Be Restarted After Being Stopped for a Period of Time?
- What Is a Headless Service When I Create a StatefulSet?
- What Should I Do If Error Message "Auth is empty" Is Displayed When a Private Image Is Pulled?
- What Is the Image Pull Policy for Containers in a CCE Cluster?
- What Can I Do If a Layer Is Missing During Image Pull?
-
Workload Abnormalities
-
Networking
- Network Planning
-
Network Fault
- How Do I Locate a Workload Networking Fault?
- Why Does the Browser Return Error Code 404 When I Access a Deployed Application?
- What Should I Do If a Container Fails to Access the Internet?
- What Should I Do If a Node Fails to Connect to the Internet (Public Network)?
- What Should I Do If an Nginx Ingress Access in the Cluster Is Abnormal After the Add-on Is Upgraded?
- Security Hardening
- Network Configuration
-
Storage
- How Do I Expand the Storage Capacity of a Container?
- What Are the Differences Among CCE Storage Classes in Terms of Persistent Storage and Multi-node Mounting?
- Can I Create a CCE Node Without Adding a Data Disk to the Node?
- What Should I Do If the Host Cannot Be Found When Files Need to Be Uploaded to OBS During the Access to the CCE Service from a Public Network?
- How Can I Achieve Compatibility Between ExtendPathMode and Kubernetes client-go?
- Can CCE PVCs Detect Underlying Storage Faults?
- Namespace
-
Chart and Add-on
- What Should I Do If Installation of an Add-on Fails and "The release name is already exist" Is Displayed?
- How Do I Configure the Add-on Resource Quotas Based on Cluster Scale?
- How Can I Clean Up Residual Resources After the NGINX Ingress Controller Add-on in the Unknown State Is Deleted?
- Why TLS v1.0 and v1.1 Cannot Be Used After the NGINX Ingress Controller Add-on Is Upgraded?
-
API & kubectl FAQs
- How Can I Access a Cluster API Server?
- Can the Resources Created Using APIs or kubectl Be Displayed on the CCE Console?
- How Do I Download kubeconfig for Connecting to a Cluster Using kubectl?
- How Do I Rectify the Error Reported When Running the kubectl top node Command?
- Why Is "Error from server (Forbidden)" Displayed When I Use kubectl?
- DNS FAQs
- Image Repository FAQs
- Permissions
-
API Reference (Kuala Lumpur Region)
- Before You Start
- API Overview
- Calling APIs
-
APIs
- API URL
-
Cluster Management
- Creating a Cluster
- Reading a Specified Cluster
- Listing Clusters in a Specified Project
- Updating a Specified Cluster
- Deleting a Cluster
- Hibernating a Cluster
- Waking Up a Cluster
- Obtaining a Cluster Certificate
- Modifying Cluster Specifications
- Querying a Job
- Binding/Unbinding Public API Server Address
- Node Management
- Node Pool Management
- Storage Management
- Add-on Management
- Tag Management
- Configuration Management
-
Chart Management
- Uploading a Chart
- Obtaining a Chart List
- Obtaining a Release List
- Updating a Chart
- Creating a Release
- Deleting a Chart
- Updating a Release
- Obtaining a Chart
- Deleting a Release
- Downloading a Chart
- Obtaining a Release
- Obtaining Chart Values
- Obtaining Historical Records of a Release
- Obtaining the Quota of a User Chart
- Kubernetes APIs
- Permissions Policies and Supported Actions
-
Appendix
- Status Code
- Error Codes
- Obtaining a Project ID
- Obtaining a Domain ID
- Specifying Add-ons to Be Installed During Cluster Creation
- How to Obtain Parameters in the API URI
- Creating a VPC and Subnet
- Creating a Key Pair
- Node Flavor Description
- Adding a Salt in the password Field When Creating a Node
- Maximum Number of Pods That Can Be Created on a Node
- Node OS
- Data Disk Space Allocation
- Attaching Disks to a Node
-
User Guide (Ankara Region)
- Service Overview
- Product Bulletin
- Getting Started
- High-Risk Operations and Solutions
-
Clusters
- Cluster Overview
- Creating a Cluster
- Connecting to a Cluster
-
Upgrading a Cluster
- Upgrade Overview
- Before You Start
- Performing Post-Upgrade Verification
- Migrating Services Across Clusters of Different Versions
-
Troubleshooting for Pre-upgrade Check Exceptions
- Pre-upgrade Check
- Node Restrictions
- Upgrade Management
- Add-ons
- Helm Charts
- SSH Connectivity of Master Nodes
- Node Pools
- Security Groups
- Arm Node Restrictions
- To-Be-Migrated Nodes
- Discarded Kubernetes Resources
- Compatibility Risks
- CCE Agent Versions
- Node CPU Usage
- CRDs
- Node Disks
- Node DNS
- Node Key Directory File Permissions
- Kubelet
- Node Memory
- Node Clock Synchronization Server
- Node OS
- Node CPU Cores
- Node Python Commands
- ASM Version
- Node Readiness
- Node journald
- containerd.sock
- Internal Error
- Node Mount Points
- Kubernetes Node Taints
- Everest Restrictions
- cce-hpa-controller Limitations
- Enhanced CPU Policies
- Health of Worker Node Components
- Health of Master Node Components
- Memory Resource Limit of Kubernetes Components
- Discarded Kubernetes APIs
- Node NetworkManager
- Node ID File
- Node Configuration Consistency
- Node Configuration File
- CoreDNS Configuration Consistency
- sudo Commands of a Node
- Key Commands of Nodes
- Mounting of a Sock File on a Node
- HTTPS Load Balancer Certificate Consistency
- Node Mounting
- Login Permissions of User paas on a Node
- Private IPv4 Addresses of Load Balancers
- Historical Upgrade Records
- CIDR Block of the Cluster Management Plane
- GPU Add-on
- Nodes' System Parameters
- Residual Package Versions
- Node Commands
- Node Swap
- nginx-ingress Upgrade
- Upgrade of Cloud Native Cluster Monitoring
- containerd Pod Restart Risks
- Key GPU Add-on Parameters
- GPU or NPU Pod Rebuild Risks
- ELB Listener Access Control
- Master Node Flavor
- Subnet Quota of Master Nodes
- Node Runtime
- Node Pool Runtime
- Number of Node Images
- Managing a Cluster
- Nodes
- Node Pools
-
Workloads
- Overview
- Creating a Workload
-
Configuring a Container
- Configuring Time Zone Synchronization
- Configuring an Image Pull Policy
- Using Third-Party Images
- Configuring Container Specifications
- Configuring Container Lifecycle Parameters
- Configuring Container Health Check
- Configuring Environment Variables
- Workload Upgrade Policies
- Scheduling Policies (Affinity/Anti-affinity)
- Taints and Tolerations
- Labels and Annotations
- Accessing a Container
- Managing Workloads and Jobs
- Managing Custom Resources
- Scheduling
-
Network
- Overview
- Container Network Models
-
Service
- Overview
- ClusterIP
- NodePort
-
LoadBalancer
- Creating a LoadBalancer Service
- Using Annotations to Balance Load
- Configuring an HTTP or HTTPS Service
- Configuring SNI for a Service
- Configuring HTTP/2 for a Service
- Configuring Timeout for a Service
- Configuring Health Check on Multiple Service Ports
- Enabling Passthrough Networking for LoadBalancer Services
- Enabling ICMP Security Group Rules
- Headless Services
-
Ingresses
- Overview
-
LoadBalancer Ingresses
- Creating a LoadBalancer Ingress on the Console
- Using kubectl to Create a LoadBalancer Ingress
- Configuring a LoadBalancer Ingress Using Annotations
- Configuring an HTTPS Certificate for a LoadBalancer Ingress
- Configuring SNI for a LoadBalancer Ingress
- LoadBalancer Ingresses to Multiple Services
- Configuring HTTP/2 for a LoadBalancer Ingress
- Configuring URL Redirection for a LoadBalancer Ingress
- Configuring URL Rewriting for a LoadBalancer Ingress
- Configuring Timeout for a LoadBalancer Ingress
- Configuring a Custom Header Forwarding Policy for a LoadBalancer Ingress
-
Nginx Ingresses
- Creating Nginx Ingresses on the Console
- Using kubectl to Create an Nginx Ingress
- Configuring Nginx Ingresses Using Annotations
- Configuring HTTPS Certificates for Nginx Ingresses
- Configuring Redirection Rules for an Nginx Ingress
- Configuring URL Rewriting Rules for Nginx Ingresses
- Nginx Ingresses Using Consistent Hashing for Load Balancing
- DNS
- Container Network Settings
- Cluster Network Settings
- Configuring Intra-VPC Access
- Accessing the Internet from a Container
- Storage
- Observability
- Namespaces
- ConfigMaps and Secrets
- Auto Scaling
-
Add-ons
- Overview
- CoreDNS
- CCE Container Storage (Everest)
- CCE Node Problem Detector
- Kubernetes Dashboard
- CCE Cluster Autoscaler
- Nginx Ingress Controller
- Kubernetes Metrics Server
- CCE Advanced HPA
- CCE AI Suite (NVIDIA GPU)
- CCE AI Suite (Ascend NPU)
- Volcano Scheduler
- NodeLocal DNSCache
- Cloud Native Cluster Monitoring
- Cloud Native Logging
- Grafana
- Prometheus
- Helm Chart
- Permissions
-
FAQs
- Common Questions
- Cluster
-
Node
- Node Creation
-
Node Running
- What Should I Do If a Cluster Is Available But Some Nodes Are Unavailable?
- How Do I Log In to a Node Using a Password and Reset the Password?
- How Do I Collect Logs of Nodes in a CCE Cluster?
- What Should I Do If the vdb Disk of a Node Is Damaged and the Node Cannot Be Recovered After Reset?
- What Should I Do If I/O Suspension Occasionally Occurs When SCSI EVS Disks Are Used?
- How Do I Fix an Abnormal Container or Node Due to No Thin Pool Disk Space?
- How Do I Rectify Failures When the NVIDIA Driver Is Used to Start Containers on GPU Nodes?
- Specification Change
- OSs
- Node Pool
-
Workload
-
Workload Abnormalities
- How Do I Use Events to Fix Abnormal Workloads?
- What Should I Do If Pod Scheduling Fails?
- What Should I Do If a Pod Fails to Pull the Image?
- What Should I Do If Container Startup Fails?
- What Should I Do If a Pod Fails to Be Evicted?
- What Should I Do If a Storage Volume Cannot Be Mounted or the Mounting Times Out?
- What Should I Do If a Workload Remains in the Creating State?
- What Should I Do If Pods in the Terminating State Cannot Be Deleted?
- What Should I Do If a Workload Is Stopped Caused by Pod Deletion?
- What Should I Do If an Error Occurs When Deploying a Service on the GPU Node?
- Container Configuration
- Scheduling Policies
-
Others
- What Should I Do If a Scheduled Task Cannot Be Restarted After Being Stopped for a Period of Time?
- What Is a Headless Service When I Create a StatefulSet?
- What Should I Do If Error Message "Auth is empty" Is Displayed When a Private Image Is Pulled?
- Why Cannot a Pod Be Scheduled to a Node?
- What Is the Image Pull Policy for Containers in a CCE Cluster?
- What Can I Do If a Layer Is Missing During Image Pull?
-
Workload Abnormalities
-
Networking
- Network Planning
-
Network Fault
- How Do I Locate a Workload Networking Fault?
- Why Does the Browser Return Error Code 404 When I Access a Deployed Application?
- What Should I Do If a Container Fails to Access the Internet?
- What Should I Do If a Node Fails to Connect to the Internet (Public Network)?
- What Should I Do If an Nginx Ingress Access in the Cluster Is Abnormal After the Add-on Is Upgraded?
- Security Hardening
- Others
-
Storage
- What Are the Differences Among CCE Storage Classes in Terms of Persistent Storage and Multi-node Mounting?
- Can I Add a Node Without a Data Disk?
- What Should I Do If the Host Cannot Be Found When Files Need to Be Uploaded to OBS During the Access to the CCE Service from a Public Network?
- How Can I Achieve Compatibility Between ExtendPathMode and Kubernetes client-go?
- Can CCE PVCs Detect Underlying Storage Faults?
- Namespace
-
Chart and Add-on
- Why Does Add-on Installation Fail and Prompt "The release name is already exist"?
- How Do I Configure the Add-on Resource Quotas Based on Cluster Scale?
- What Should I Do If the Helm Chart Uploaded Before the Tenant Account Name Is Changed Is Abnormal?
- How Can I Clean Up Residual Resources After the NGINX Ingress Controller Add-on in the Unknown State Is Deleted?
- Why TLS v1.0 and v1.1 Cannot Be Used After the NGINX Ingress Controller Add-on Is Upgraded?
-
API & kubectl FAQs
- How Can I Access a Cluster API Server?
- Can the Resources Created Using APIs or kubectl Be Displayed on the CCE Console?
- How Do I Download kubeconfig for Connecting to a Cluster Using kubectl?
- How Do I Rectify the Error Reported When Running the kubectl top node Command?
- Why Is "Error from server (Forbidden)" Displayed When I Use kubectl?
- DNS FAQs
- Permissions
- Reference
-
Best Practices
- Checklist for Deploying Containerized Applications in the Cloud
- Containerization
- Disaster Recovery
- Security
- Auto Scaling
- Monitoring
- Cluster
- Networking
- Storage
- Container
- Permission
- Release
-
API Reference (Ankara Region)
- Before You Start
- API Overview
- Calling APIs
-
APIs
- API URL
-
Cluster Management
- Creating a Cluster
- Reading a Specified Cluster
- Listing Clusters in a Specified Project
- Updating a Specified Cluster
- Deleting a Cluster
- Hibernating a Cluster
- Waking Up a Cluster
- Obtaining a Cluster Certificate
- Modifying Cluster Specifications
- Querying a Job
- Binding/Unbinding Public API Server Address
- Obtaining Cluster Access Address
- Node Management
- Node Pool Management
- Storage Management
- Add-on Management
- Quota Management
- API Versions
- Tag Management
- Configuration Management
-
Chart Management
- Uploading a Chart
- Obtaining a Chart List
- Obtaining a Release List
- Updating a Chart
- Creating a Release
- Deleting a Chart
- Updating a Release
- Obtaining a Chart
- Deleting a Release
- Downloading a Chart
- Obtaining a Release
- Obtaining Chart Values
- Obtaining Historical Records of a Release
- Obtaining the Quota of a User Chart
- Kubernetes APIs
- Permissions and Supported Actions
-
Appendix
- Status Code
- Error Codes
- Obtaining a Project ID
- Obtaining an Account ID
- Specifying Add-ons to Be Installed During Cluster Creation
- How to Obtain Parameters in the API URI
- Creating a VPC and Subnet
- Creating a Key Pair
- Node Flavor Description
- Adding a Salt in the password Field When Creating a Node
- Maximum Number of Pods That Can Be Created on a Node
- Node OS
- Data Disk Space Allocation
- Attaching Disks to a Node
-
User Guide (ME-Abu Dhabi Region)
- General Reference
- Cluster
- Node
- Node Pool
- Virtual Private Cloud (VPC)
- Security Group
- Pod
- Container
- Workload
- Image
- Namespace
- Service
- Layer-7 Load Balancing (Ingress)
- Network Policy
- ConfigMap
- Secret
- Label
- Label Selector
- Annotation
- PersistentVolume
- PersistentVolumeClaim
- Auto Scaling - HPA
- Affinity and Anti-Affinity
- Node Affinity
- Node Anti-Affinity
- Pod Affinity
- Pod Anti-Affinity
- Resource Quota
- Resource Limit (LimitRange)
- Environment Variable
- Chart
Show all
Copied.
Basic Concepts
CCE provides highly scalable, high-performance, enterprise-class Kubernetes clusters and supports Docker containers. With CCE, you can easily deploy, manage, and scale containerized applications in the cloud.
The graphical CCE console enables E2E user experiences. In addition, CCE supports native Kubernetes APIs and kubectl. Before using CCE, you are advised to understand related basic concepts.
Cluster
A cluster is a group of one or more cloud servers (also known as nodes) in the same subnet. It has all the cloud resources (including VPCs and compute resources) required for running containers.
Node
A node is a cloud server (virtual or physical machine) running an instance of the Docker Engine. Containers are deployed, run, and managed on nodes. The node agent (kubelet) runs on each node to manage container instances on the node. The number of nodes in a cluster can be scaled.
Node Pool
A node pool contains one node or a group of nodes with identical configuration in a cluster.
Virtual Private Cloud (VPC)
A VPC is a logically isolated virtual network that facilitates secure internal network management and configurations. Resources in the same VPC can communicate with each other, but those in different VPCs cannot communicate with each other by default. VPCs provide the same network functions as physical networks and also advanced network services, such as elastic IP addresses and security groups.
Security Group
A security group is a collection of access control rules for ECSs that have the same security protection requirements and are mutually trusted in a VPC. After a security group is created, you can create different access rules for the security group to protect the ECSs that are added to this security group.
Relationship Between Clusters, VPCs, Security Groups, and Nodes
- Different clusters are created in different VPCs.
- Different clusters are created in the same subnet.
- Different clusters are created in different subnets.
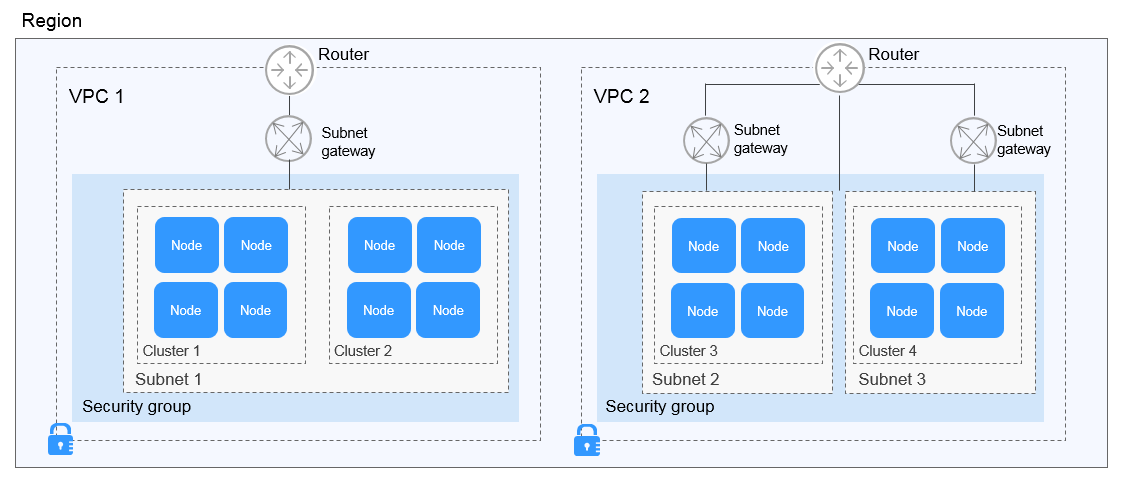
Pod
A pod is the smallest and simplest unit in the Kubernetes object model that you create or deploy. A pod encapsulates an application container (or, in some cases, multiple containers), storage resources, a unique network IP address, and options that govern how the containers should run.
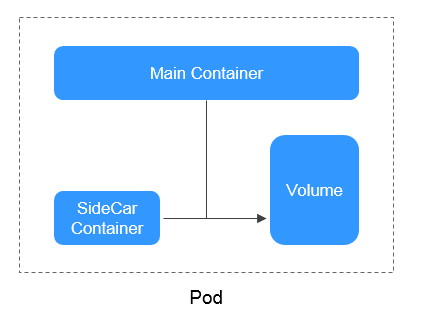
Container
A container is a running instance of a Docker image. Multiple containers can run on one node. Containers are actually software processes. Unlike traditional software processes, containers have separate namespace and do not run directly on a host.
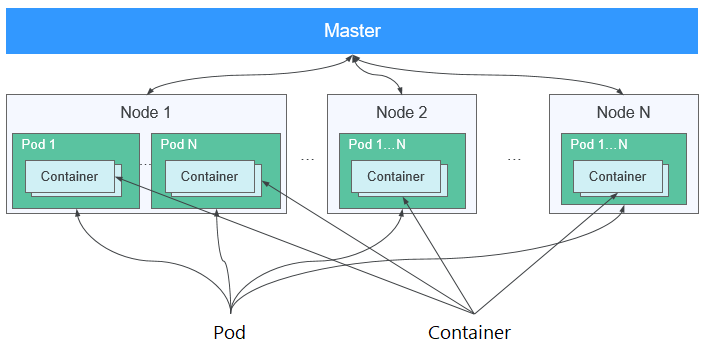
Workload
A workload is an application running on Kubernetes. No matter how many components are there in your workload, you can run it in a group of Kubernetes pods. A workload is an abstract model of a group of pods in Kubernetes. Workloads classified in Kubernetes include Deployments, StatefulSets, DaemonSets, jobs, and cron jobs.
- Deployment: Pods are completely independent of each other and functionally identical. They feature auto scaling and rolling upgrade. Typical examples include Nginx and WordPress.
- StatefulSet: Pods are not completely independent of each other. They have stable persistent storage, and feature orderly deployment and deletion. Typical examples include MySQL-HA and etcd.
- DaemonSet: A DaemonSet ensures that all or some nodes run a pod. It is applicable to pods running on every node. Typical examples include Ceph, Fluentd, and Prometheus Node Exporter.
- Job: It is a one-time task that runs to completion. It can be executed immediately after being created. Before creating a workload, you can execute a job to upload an image to the image repository.
- Cron job: It runs a job periodically on a given schedule. You can perform time synchronization for all active nodes at a fixed time point.
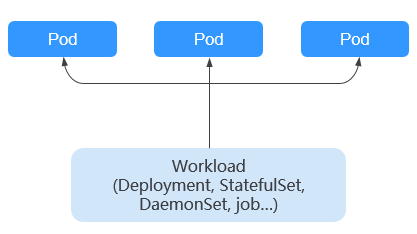
Image
Docker creates an industry standard for packaging containerized applications. Docker images are like templates that include everything needed to run containers, and are used to create Docker containers. In other words, Docker image is a special file system that includes everything needed to run containers: programs, libraries, resources, and configuration files. It also contains configuration parameters (such as anonymous volumes, environment variables, and users) required within a container runtime. An image does not contain any dynamic data. Its content remains unchanged after being built. When deploying containerized applications, you can use images from Docker Hub, SoftWare Repository for Container (SWR), and your private image registries. For example, a Docker image can contain a complete Ubuntu operating system, in which only the required programs and dependencies are installed.
Images become containers at runtime, that is, containers are created from images. Containers can be created, started, stopped, deleted, and suspended.
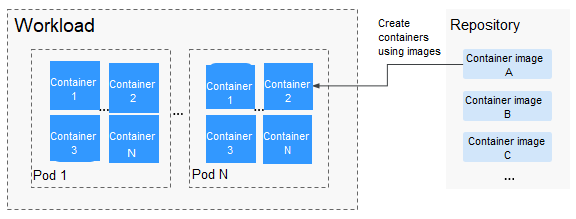
Namespace
A namespace is an abstract collection of resources and objects. It enables resources to be organized into non-overlapping groups. Multiple namespaces can be created inside a cluster and isolated from each other. This enables namespaces to share the same cluster services without affecting each other. Examples:
- You can deploy workloads in a development environment into one namespace, and deploy workloads in a test environment into another namespace.
- Pods, Services, ReplicationControllers, and Deployments belong to a namespace (named default, by default), whereas nodes and PersistentVolumes do not belong to any namespace.
Service
A Service is an abstract method that exposes a group of applications running on a pod as network services.
Kubernetes provides you with a service discovery mechanism without modifying applications. In this mechanism, Kubernetes provides pods with their own IP addresses and a single DNS for a group of pods, and balances load between them.
Kubernetes allows you to specify a Service of a required type. The values and actions of different types of Services are as follows:
- ClusterIP: ClusterIP Service, as the default Service type, is exposed through the internal IP address of the cluster. If this mode is selected, Services can be accessed only within the cluster.
- NodePort: NodePort Services are exposed through the IP address and static port of each node. A ClusterIP Service, to which a NodePort Service will route, is automatically created. By sending a request to <NodeIP>:<NodePort>, you can access a NodePort Service from outside of a cluster.
- LoadBalancer (ELB): LoadBalancer (ELB) Services are exposed by using load balancers of the cloud provider. External load balancers can route to NodePort and ClusterIP Services.
Layer-7 Load Balancing (Ingress)
An ingress is a set of routing rules for requests entering a cluster. It provides Services with URLs, load balancing, SSL termination, and HTTP routing for external access to the cluster.
Network Policy
Network policies provide policy-based network control to isolate applications and reduce the attack surface. A network policy uses label selectors to simulate traditional segmented networks and controls traffic between them and traffic from outside.
ConfigMap
A ConfigMap is used to store configuration data or configuration files as key-value pairs. ConfigMaps are similar to secrets, but provide a means of working with strings that do not contain sensitive information.
Secret
Secrets resolve the configuration problem of sensitive data such as passwords, tokens, and keys, and will not expose the sensitive data in images or pod specs. A secret can be used as a volume or an environment variable.
Label
A label is a key-value pair and is associated with an object, for example, a pod. Labels are used to identify special features of objects and are meaningful to users. However, labels have no direct meaning to the kernel system.
Label Selector
Label selector is the core grouping mechanism of Kubernetes. It identifies a group of resource objects with the same characteristics or attributes through the label selector client or user.
Annotation
Annotations are defined in key-value pairs as labels are.
Labels have strict naming rules. They define the metadata of Kubernetes objects and are used by label selectors.
Annotations are additional user-defined information for external tools to search for a resource object.
PersistentVolume
A PersistentVolume (PV) is a network storage in a cluster. Similar to a node, it is also a cluster resource.
PersistentVolumeClaim
A PV is a storage resource, and a PersistentVolumeClaim (PVC) is a request for a PV. PVC is similar to pod. Pods consume node resources, and PVCs consume PV resources. Pods request CPU and memory resources, and PVCs request data volumes of a specific size and access mode.
Auto Scaling - HPA
Horizontal Pod Autoscaling (HPA) is a function that implements horizontal scaling of pods in Kubernetes. The scaling mechanism of ReplicationController can be used to scale your Kubernetes clusters.
Affinity and Anti-Affinity
If an application is not containerized, multiple components of the application may run on the same virtual machine and processes communicate with each other. However, in the case of containerization, software processes are packed into different containers and each container has its own lifecycle. For example, the transaction process is packed into a container while the monitoring/logging process and local storage process are packed into other containers. If closely related container processes run on distant nodes, routing between them will be costly and slow.
- Affinity: Containers are scheduled onto the nearest node. For example, if application A and application B frequently interact with each other, it is necessary to use the affinity feature to keep the two applications as close as possible or even let them run on the same node. In this way, no performance loss will occur due to slow routing.
- Anti-affinity: Instances of the same application spread across different nodes to achieve higher availability. Once a node is down, instances on other nodes are not affected. For example, if an application has multiple replicas, it is necessary to use the anti-affinity feature to deploy the replicas on different nodes. In this way, no single point of failure will occur.
Node Affinity
By selecting labels, you can schedule pods to specific nodes.
Node Anti-Affinity
By selecting labels, you can prevent pods from being scheduled to specific nodes.
Pod Affinity
You can deploy pods onto the same node to reduce consumption of network resources.
Pod Anti-Affinity
You can deploy pods onto different nodes to reduce the impact of system breakdowns. Anti-affinity deployment is also recommended for workloads that may interfere with each other.
Resource Quota
Resource quotas are used to limit the resource usage of users.
Resource Limit (LimitRange)
By default, all containers in Kubernetes have no CPU or memory limit. LimitRange (limits for short) is used to add a resource limit to a namespace, including the minimum, maximum, and default amounts of resources. When a pod is created, resources are allocated according to the limits parameters.
Environment Variable
An environment variable is a variable whose value can affect the way a running container will behave. A maximum of 30 environment variables can be defined at container creation time. You can modify environment variables even after workloads are deployed, increasing flexibility in workload configuration.
The function of setting environment variables on CCE is the same as that of specifying ENV in a Dockerfile.
Chart
For your Kubernetes clusters, you can use Helm to manage software packages, which are called charts. Helm is to Kubernetes what the apt command is to Ubuntu or what the yum command is to CentOS. Helm can quickly search for, download, and install charts.
Charts are a Helm packaging format. It describes only a group of related cluster resource definitions, not a real container image package. A Helm chart contains only a series of YAML files used to deploy Kubernetes applications. You can customize some parameter settings in a Helm chart. When installing a chart, Helm deploys resources in the cluster based on the YAML files defined in the chart. Related container images are not included in the chart but are pulled from the image repository defined in the YAML files.
Application developers need to push container image packages to the image repository, use Helm charts to package dependencies, and preset some key parameters to simplify application deployment.
Helm directly installs applications and their dependencies in the cluster based on the YAML files in a chart. Application users can search for, install, upgrade, roll back, and uninstall applications without defining complex deployment files.
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



