
What Should I Do If Data Fails to Be Written to Hudi Using Spark SQL?
Error: hoodie table path not found

Cause
The metastore contains a table that is not a Hudi table, or does not contain a table directory. The root cause is that the table directory does not contain the .hoodie directory. During table deletion, only the file is deleted but the table is not dropped.
Solution
Run drop table on the DataArts Studio console, Hue, or spark-beeline to delete the table from the metastore, enable auto table creation, and rerun the job. Alternatively, run the table creation statement to create a Hudi table.
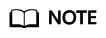
To delete an MOR table, you must also delete the ro and rt tables. Otherwise, residual schemas may exist.
Error: Written Records Contain Null Values and the Writing Fails
Cause
The column that is set as the primary key or pre-aggregation key contains an empty value, and data fails to be written to hoodie.
Troubleshooting Method
Check whether the columns configured for hoodie.datasource.write.recordkey.field, hoodie.datasource.write.precombine.field, and hoodie.datasource.write.partitionpath.field in the table attributes contain null values in the source data.
Solution
Delete the null values and run the job again.
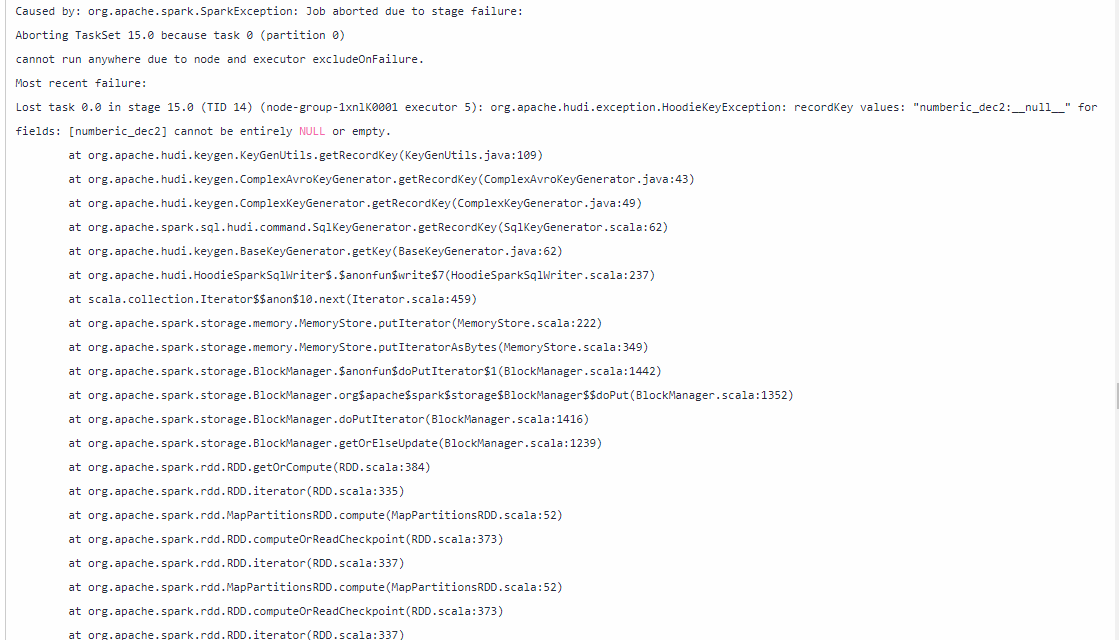
Error: killed by external signal
Cause
The memory used by the executor may have reached the upper limit due to data skew. For details, contact MRS engineers to locate the fault. You can obtain the Yarn application ID from the log. Search for Yarn Application Id in the log and query the Yarn Application ID nearest to the error message.
Troubleshooting
- Log in to Yarn, query the Yarn task based on the application ID, and start ApplicationManager.
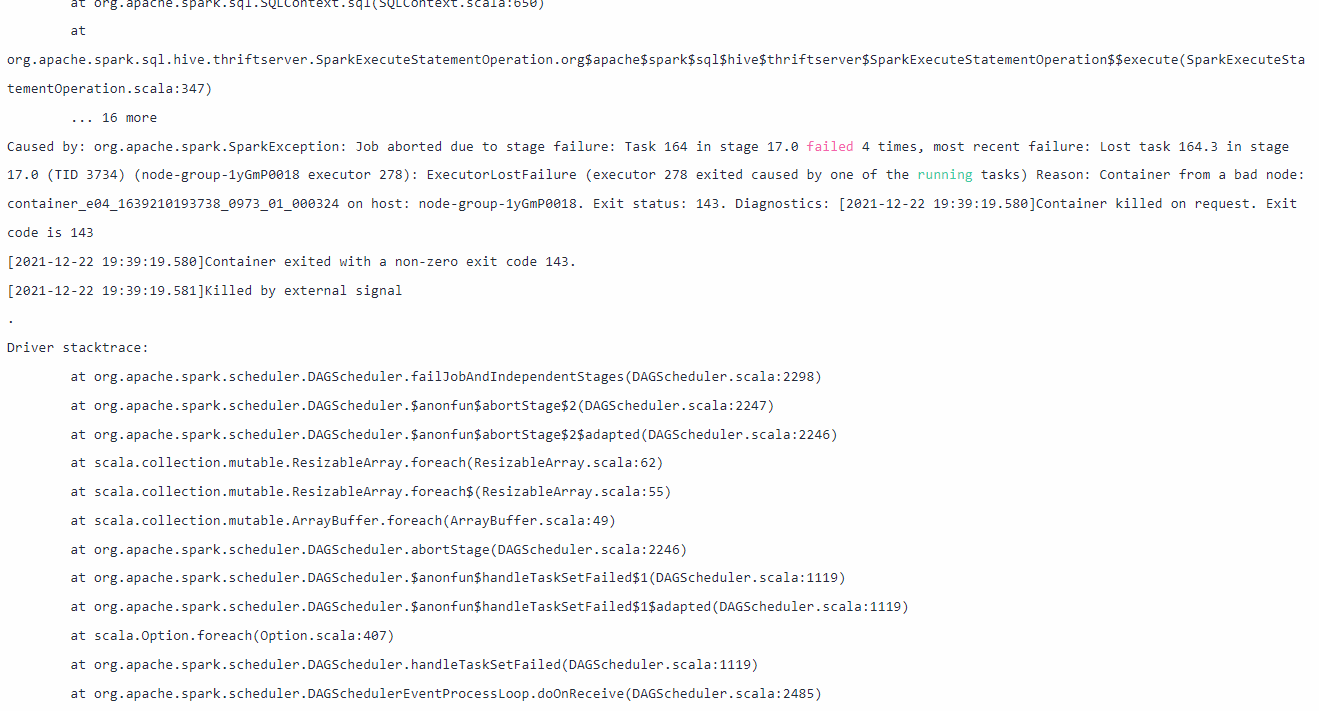
- Start stage, view the tasks in failed state. You can view the failure cause in the log or on the GUI. Generally, the following error is reported:
transferring unroll memory to storage memory failed (The cache in the RDD runs out of the executor memory.)
Workarounds:
- On the Job Management page, click More in the Operation column and select Retry to execute Spark SQL again.
- Use DataArts Studio to execute Spark SQL, and set execution parameters or adjust the SQL statement.
set spark.sql.files.maxPartitionBytes=xxM; The default size is 128 MB. You can change it to 64 MB or 32 MB.
If data is not evenly split, modify the SQL configuration DISTRIBUTE BY rand() and add a shuffle process to split data evenly. (This requires a large number of resources. Exercise caution when the number of available resources is limited.)
insert into xx select * from xxx DISTRIBUTE BY rand();
- Use DataArts Studio APIs to submit Spark SQL to increase the executor memory.
Error: java.lang.IllegalArgumentException
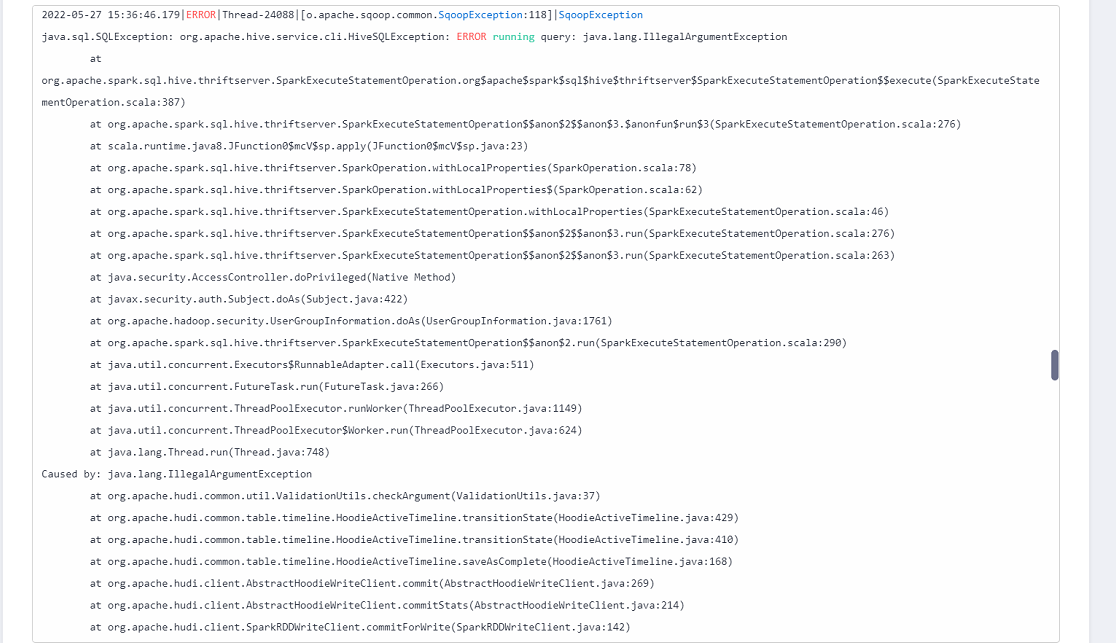
Cause
Hudi does not support concurrent write which causes commit conflicts.
Solution
Check whether other connections are writing data to the Hudi table. If yes, stop the connections and run the CDM job again.
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



