
Using For Each Nodes
Scenario
During job development, if some jobs have different parameters but the same processing logic, you can use For Each nodes to avoid repeated job development.
You can use a For Each node to execute a subjob in a loop and use a dataset to replace the parameters in the subjob. The key parameters are as follows:
- Subjob in a Loop: Select the subjob to be executed in a loop.
- Dataset: Enter a set of parameter values of the subjobs. The value can be a specified dataset such as [['1'],['3'],['2']] or an EL expression such as #{Job.getNodeOutput('preNodeName')}, which is the output value of the previous node.
- Subjob Parameter Name: The parameter name is the variable defined in the subjob. The parameter value is usually set to a group of data in the dataset. Each time the job is run, the parameter value is transferred to the subjob for use. For example, parameter value #{Loop.current[0]} indicates that the first value of each row of data in the dataset is traversed and transferred to the subjob.
Figure 1 shows an example For Each node. As shown in the figure, the parameter name of the foreach subjob is result, and the parameter value is the traversal of the one-dimensional array dataset [['1'],['3'],['2']] (that is, the value is 1, 3, and 2 in the first, second, and third loop, respectively).

For Each Nodes and EL Expressions
To use For Each nodes properly, you must be familiar with EL expressions. For details about how to use EL expressions, see EL Expressions.
For Each nodes use the following EL expressions most:
- #{Loop.dataArray}: dataset input by the For Each node. It is a two-dimensional array.
- #{Loop.current}: The For Loop node processes a dataset line by line. Loop.current indicates a line of data that is being processed. Loop.current is a one-dimensional array, and its format is #{Loop.current[0]}, #{Loop.current[1]}, or others. The value 0 indicates that the first value in the current line is traversed.
- #{Loop.offset}: current offset when the For Each node processes the dataset. The value starts from 0.
- #{Job.getNodeOutput('preNodeName')}: obtains the output of the previous node.
Examples
Scenario
To meet data normalization requirements, you need to periodically import data from multiple source DLI tables to the corresponding destination DLI tables, as listed in Table 1.
If you use SQL nodes to execute import scripts, a large number of scripts and nodes need to be developed, resulting in repeated work. In this case, you can use the For Each node to perform cyclic jobs to reduce the development workload.
Configuration Method
- Prepare the source and destination tables. To facilitate subsequent job execution and verification, you need to create a source DLI table and a destination DLI table and insert data into the tables.
- Create a DLI table. You can create a DLI SQL script on the DataArts Factory page and run the following commands to create a DLI table. You can also run the following SQL commands in the SQL editor on the DLI console.
/* Create a data table. */ CREATE TABLE a_new (name STRING, score INT) STORED AS PARQUET; CREATE TABLE b_2 (name STRING, score INT) STORED AS PARQUET; CREATE TABLE c_3 (name STRING, score INT) STORED AS PARQUET; CREATE TABLE d_1 (name STRING, score INT) STORED AS PARQUET; CREATE TABLE c_5 (name STRING, score INT) STORED AS PARQUET; CREATE TABLE b_1 (name STRING, score INT) STORED AS PARQUET; CREATE TABLE a (name STRING, score INT) STORED AS PARQUET; CREATE TABLE b (name STRING, score INT) STORED AS PARQUET; CREATE TABLE c (name STRING, score INT) STORED AS PARQUET; CREATE TABLE d (name STRING, score INT) STORED AS PARQUET; CREATE TABLE e (name STRING, score INT) STORED AS PARQUET; CREATE TABLE f (name STRING, score INT) STORED AS PARQUET;
- Insert data into the source data table. You can create a DLI SQL script on the DataArts Factory page and run the following commands to create a DLI table. You can also run the following SQL commands in the SQL editor on the DLI console.
/* Insert data into the source data table. */ INSERT INTO a_new VALUES ('ZHAO','90'),('QIAN','88'),('SUN','93'); INSERT INTO b_2 VALUES ('LI','94'),('ZHOU','85'); INSERT INTO c_3 VALUES ('WU','79'); INSERT INTO d_1 VALUES ('ZHENG','87'),('WANG','97'); INSERT INTO c_5 VALUES ('FENG','83'); INSERT INTO b_1 VALUES ('CHEN','99');
- Create a DLI table. You can create a DLI SQL script on the DataArts Factory page and run the following commands to create a DLI table. You can also run the following SQL commands in the SQL editor on the DLI console.
- Prepare dataset data. You can obtain a dataset in any of the following ways:
- Import the data in Table 1 into the DLI table and use the result read by the SQL script as the dataset.
- You can save the data in Table 1 to a CSV file in the OBS bucket. Then use a DLI SQL or DWS SQL statement to create an OBS foreign table, associate it with the CSV file, and use the query result of the OBS foreign table as the dataset. For details about how to create a foreign table on DLI, see OBS Source Stream. For details about how to create a foreign table on DWS, see Creating a Foreign Table.
- You can save the data in Table 1 to a CSV file in the HDFS. Then use a Hive SQL statement to create a Hive foreign table, associate it with the CSV file, and use the query result of the Hive foreign table as the dataset. For details about how to create an MRS foreign table, see Creating a Table.
This section uses method 1 as an example to describe how to import data from Table 1 to the DLI table (Table_List). You can create a DLI SQL script on the DataArts Factory page and run the following commands to import data into the table. You can also run the following SQL commands in the SQL editor on the DLI console./* Create the Table_List data table, insert data in Table 1 into the table, and check the generated data. */ CREATE TABLE Table_List (Source STRING, Destination STRING) STORED AS PARQUET; INSERT INTO Table_List VALUES ('a_new','a'),('b_2','b'),('c_3','c'),('d_1','d'),('c_5','e'),('b_1','f'); SELECT * FROM Table_List;The generated data in the Table_List table is as follows:
Figure 2 Data in the Table_List table
- Create a subjob named ForeachDemo to be executed cyclically. In this operation, a task containing the DLI SQL node is defined to be executed cyclically.
- Access the DataArts Studio DataArts Factory page, choose Develop Job. Create a job named ForeachDemo, select the DLI SQL node, and configure the job as shown in Figure 3. In the DLI SQL statement, set the variable to be replaced to ${}. The following SQL statement is used to import all data in the ${Source} table to the ${Destination} table. ${fromTable} and ${toTable} are the variables. The SQL statement is as follows:
INSERT INTO ${Destination} select * from ${Source};
Do not use the #{Job.getParam("job_param_name")} EL expression because this expression can only obtain the values of the parameters configured in the current job, but cannot obtain the parameter values transferred from the parent job or the global variables configured in the workspace. The expression only works for the current job.
To obtain the parameter values passed from the parent job and the global variables configured for the workspace, you are advised to use the ${job_param_name} expression.
- After configuring the SQL statement, configure parameters for the subjob. You only need to set the parameter names, which are used by the For Each operator of the ForeachDemo_master job to identify subjob parameters. Figure 4 Configuring subjob parameters

- Save the job.
- Access the DataArts Studio DataArts Factory page, choose Develop Job. Create a job named ForeachDemo, select the DLI SQL node, and configure the job as shown in Figure 3.
- Create a master job named ForeachDemo_master where the For Each node is located.
- Access the DataArts Studio DataArts Studio page and choose Develop Job. Create a data development master job named ForeachDemo_master. Select the DLI SQL and For Each nodes and click and drag
 to compile the job shown in Figure 5.
to compile the job shown in Figure 5. - Configure the properties of the DLI SQL node. Select SQL statement and and enter the following statement. The DLI SQL node reads data from the DLI table Table_List and uses it as the dataset.
SELECT * FROM Table_List;
Figure 6 DLI SQL node configuration
- Configure properties for the For Each node.
- Subjob in a Loop: Select ForeachDemo, which is the subjob that has been developed in step 2.
- Dataset: Enter the execution result of the select statement on the DLI SQL node. Use the #{Job.getNodeOutput('preDLI')} expression, where preDLI is the name of the previous node.
- Subjob Parameter Name: used to transfer data in the dataset to the subjob Source corresponds to the first column in the Table_List table of the dataset, and Destination corresponds to the second column. Therefore, enter EL expression #{Loop.current[0]} for Source and #{Loop.current[1]} for Destination.
Figure 7 Configuring properties for the For Each node
- Save the job.
- Access the DataArts Studio DataArts Studio page and choose Develop Job. Create a data development master job named ForeachDemo_master. Select the DLI SQL and For Each nodes and click and drag
- Test the main job.
- Click Test above the canvas to test the main job. After the main job is executed, the subjob is automatically invoked through the For Each node and executed.
- In the navigation pane on the left, choose Monitor Instance to view the job execution status. After the job is successfully executed, you can view the subjob instances generated on the For Each node. Because the dataset contains six rows of data, six subjob instances are generated. Figure 8 Viewing job instances

- Check whether the data has been inserted into the six DLI destination tables. You can create a DLI SQL script on the DataArts Factory page and run the following commands to import data into the table. You can also run the following SQL commands in the SQL editor on the DLI console.
/* Run the following command to query the data in a table (table a is used as an example): */ SELECT * FROM a;
Compare the obtained data with the data in Insert data into the source data table. The inserted data meets the expectation.
Figure 9 Destination table data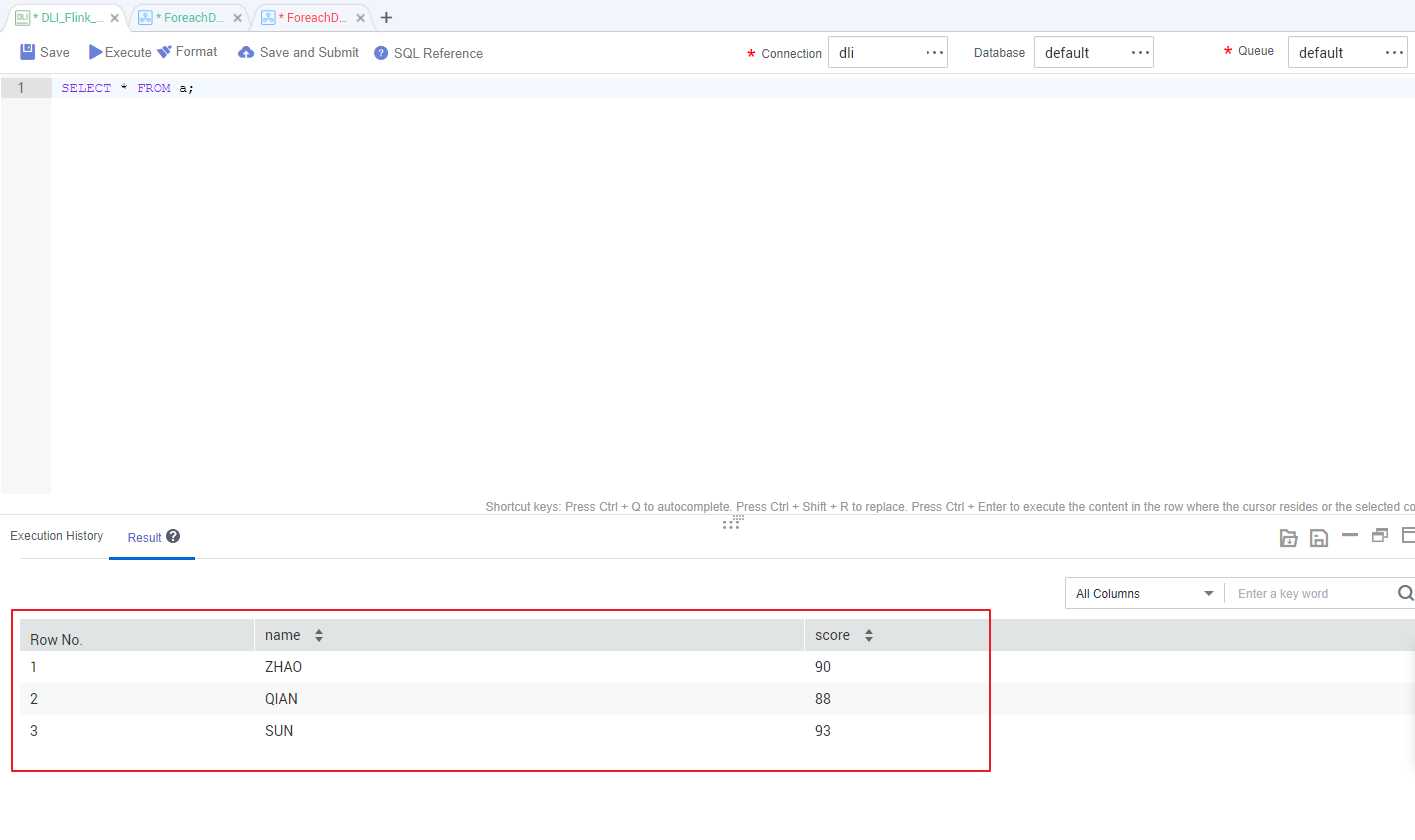


More Cases for Reference
For Each nodes can work with other nodes to implement more functions. You can refer to the following cases to learn more about how to use For Each nodes.
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



