
NUMA Affinity Scheduling
In non-uniform memory access (NUMA) architecture, a NUMA node is a fundamental component that includes a processor and local memory. These nodes are physically separate but interconnected through a high-speed bus to form a complete system. To boost system performance, NUMA nodes allow for quicker access to local memory. However, accessing memory across multiple NUMA nodes within a node can cause delays. To enhance memory access efficiency and overall performance, it is crucial to optimize task scheduling and memory allocation.
When working with high-performance computing (HPC), real-time applications, or memory-intensive workloads that require frequent communication between CPUs, accessing nodes across NUMA in a cloud native environment can lead to decreased system performance due to increased latency and overhead. Volcano's NUMA affinity scheduling resolves the issue by scheduling pods to the worker node that requires the least number of cross-NUMA nodes. This reduces data transmission overheads, optimizes resource utilization, and enhances overall system performance.
For more information, see https://github.com/volcano-sh/volcano/blob/master/docs/design/numa-aware.md.
Prerequisites
- A CCE standard or Turbo cluster is available. For details, see Buying a CCE Standard/Turbo Cluster.
- The Volcano add-on has been installed in the cluster. For details, see Volcano Scheduler.
Pod Scheduling Process
After a topology policy is configured for pods, Volcano predicts the nodes that match the policy. For details about how to configure a pod topology policy, see Example of NUMA Affinity Scheduling. The scheduling process is as follows:
- Volcano filters nodes with the same policy based on the topology policy configured for pods. The topology policy provided by Volcano is the same as that provided by the topology manager.
- Among the nodes where the same policy applies, Volcano selects the nodes whose CPU topology meets the policy requirements for scheduling.
|
Pod Topology Policy |
How to Filter Nodes During Pod Scheduling |
|
|---|---|---|
|
1. Filter nodes that meet the topology policy set for the pod. |
2. Further filter the node whose CPU topology meets the policy. |
|
|
none |
Nodes with the following topology policies will not be filtered during scheduling:
|
None |
|
best-effort |
Nodes with the best-effort topology policy will be filtered.
|
Best-effort scheduling: Pods are preferentially scheduled to a single NUMA node. If a single NUMA node cannot meet the requested CPU cores, the pods can be scheduled to multiple NUMA nodes. |
|
restricted |
Nodes with the restricted topology policy will be filtered.
|
Restricted scheduling:
|
|
single-numa-node |
Nodes with the single-numa-node topology policy will be filtered.
|
Pods can only be scheduled to a single NUMA node. |
For example, two NUMA nodes provide resources, each with a total of 32 CPU cores. The following table lists resource allocation.
|
Worker Node |
Node Topology Policy |
Total CPU Cores on NUMA Node 1 |
Total CPU Cores on NUMA Node 2 |
||
|---|---|---|---|---|---|
|
Total CPU Cores |
Available CPU Cores |
Total CPU Cores |
Available CPU Cores |
||
|
Node 1 |
best-effort |
16 |
7 |
16 |
7 |
|
Node 2 |
restricted |
16 |
7 |
16 |
7 |
|
Node 3 |
restricted |
16 |
7 |
16 |
10 |
|
Node 4 |
single-numa-node |
16 |
7 |
16 |
10 |
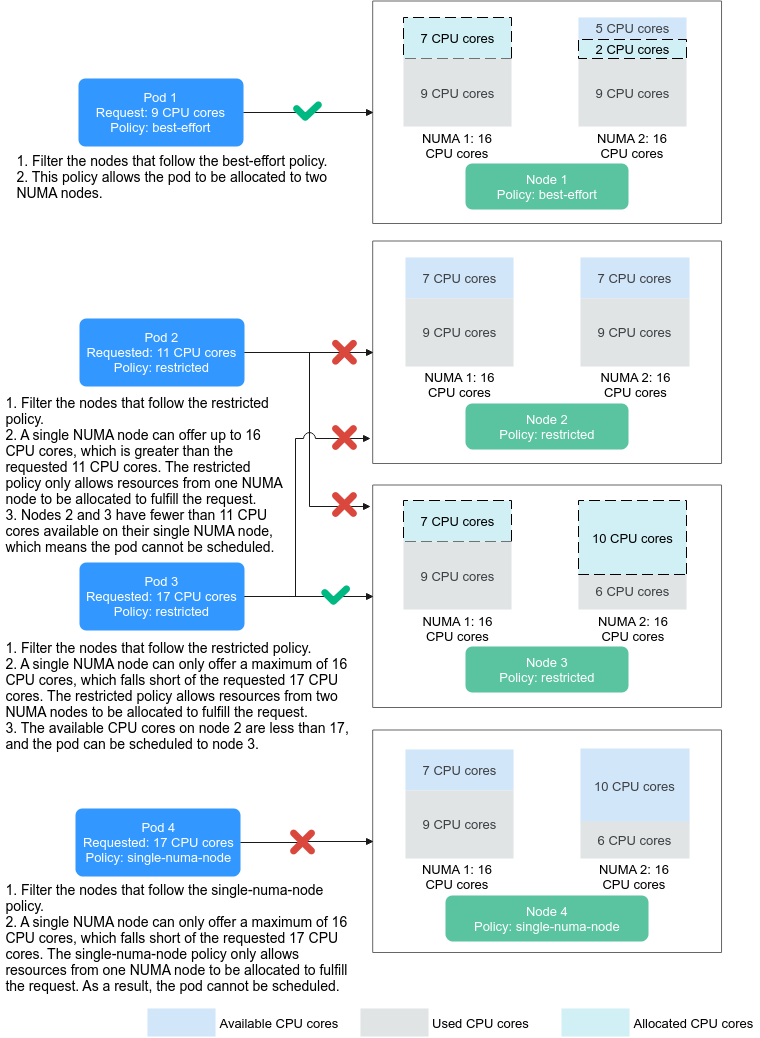
Figure 1 shows the scheduling of a pod after a topology policy is configured.
- When 9 CPU cores are requested by a pod and the best-effort topology policy is used, Volcano selects node 1 whose topology policy is also best-effort, and this policy allows the pod to be scheduled to multiple NUMA nodes. Therefore, the requested 9 CPU cores will be allocated to two NUMA nodes, and the pod can be scheduled to node 1.
- When 11 CPU cores are requested by a pod and the restricted topology policy is used, Volcano selects nodes 2 and 3 whose topology policy is also restricted, and each node provides at least 11 CPU cores. However, the remaining CPU cores on node 2 or 3 are less than the requested. Therefore, the pod cannot be scheduled.
- When 17 CPU cores are requested by a pod and the restricted topology policy is used, Volcano selects nodes 2 and 3 whose topology policy is also restricted, this policy allows the pod to be scheduled to multiple NUMA nodes, and the upper CPU limit of both the nodes is less than 17. Then, the pod can be scheduled to node 3.
- When 17 CPU cores are requested by a pod and the single-numa-node topology policy is used, Volcano selects nodes whose topology policy is also single-numa-node. However, no node can provide a total of 17 CPU cores. Therefore, the pod cannot be scheduled.
Scheduling Priority
A topology policy aims to schedule pods to the optimal node. In this example, each node is scored to sort out the optimal node.
Principle: Schedule pods to the worker nodes that require the fewest NUMA nodes.
The scoring formula is as follows:
score = weight x (100 - 100 x numaNodeNum/maxNumaNodeNum)
Parameters:
- weight: the weight of NUMA Aware Plugin.
- numaNodeNum: the number of NUMA nodes required for running the pod on worker nodes.
- maxNumaNodeNum: the maximum number of NUMA nodes required for running the pod among all worker nodes.
For example, three nodes meet the CPU topology policy for a pod and the weight of NUMA Aware Plugin is set to 10.
- Node A: One NUMA node provides the CPU resources required by the pod (numaNodeNum = 1).
- Node B: Two NUMA nodes provide the CPU resources required by the pod (numaNodeNum = 2).
- Node C: Four NUMA nodes provide the CPU resources required by the pod (numaNodeNum = 4).
According to the preceding formula, maxNumaNodeNum is 4.
- score (Node A) = 10 x (100 - 100 x 1/4) = 750
- score (Node B) = 10 x (100 - 100 x 2/4) = 500
- score (Node C) = 10 x (100 - 100 x 4/4) = 0
Therefore, the optimal node is Node A.
Enabling NUMA Affinity Scheduling for Volcano
- Enable static CPU management in the node pool. For details, see Enabling CPU Management for a Custom Node Pool.
- Log in to the CCE console and click the cluster name to access the cluster console.
- Choose Nodes in the navigation pane and click the Node Pools tab on the right. Locate the target node pool and choose More > Manage.
- On the Manage Configurations page, change the cpu-manager-policy value to static in the kubelet area.
- Click OK.
- Configure a CPU topology policy in the node pool.
- Log in to the CCE console and click the cluster name to access the cluster console. In the navigation pane, choose Nodes. On the right of the page, click the Node Pools tab and choose More > Manage in the Operation column of the target node pool.
- Change the kubelet Topology Management Policy (topology-manager-policy) value to the required CPU topology policy.
Valid topology policies include none, best-effort, restricted, and single-numa-node. For details, see Pod Scheduling Process.
- Enable the numa-aware add-on and the resource_exporter function.
Volcano 1.7.1 or later
- Log in to the CCE console and click the cluster name to access the cluster console. Choose Add-ons in the navigation pane, locate Volcano Scheduler on the right, and click Edit.
- In the Extended Functions area, enable NUMA Topology Scheduling and click OK.
Volcano earlier than 1.7.1- Log in to the CCE console and click the cluster name to access the cluster console. In the navigation pane, choose Settings and click the Scheduling tab. Select Volcano scheduler, find the expert mode, and click Try Now.
- Enable resource_exporter_enable to collect node NUMA information. The following is an example in JSON format:
{ "plugins": { "eas_service": { "availability_zone_id": "", "driver_id": "", "enable": "false", "endpoint": "", "flavor_id": "", "network_type": "", "network_virtual_subnet_id": "", "pool_id": "", "project_id": "", "secret_name": "eas-service-secret" } }, "resource_exporter_enable": "true" }After this function is enabled, you can view the NUMA topology information of the current node.kubectl get numatopo NAME AGE node-1 4h8m node-2 4h8m node-3 4h8m
- Enable the Volcano numa-aware algorithm add-on.
kubectl edit cm -n kube-system volcano-scheduler-configmap
kind: ConfigMap apiVersion: v1 metadata: name: volcano-scheduler-configmap namespace: kube-system data: default-scheduler.conf: |- actions: "allocate, backfill, preempt" tiers: - plugins: - name: priority - name: gang - name: conformance - plugins: - name: overcommit - name: drf - name: predicates - name: nodeorder - plugins: - name: cce-gpu-topology-predicate - name: cce-gpu-topology-priority - name: cce-gpu - plugins: - name: nodelocalvolume - name: nodeemptydirvolume - name: nodeCSIscheduling - name: networkresource arguments: NetworkType: vpc-router - name: numa-aware # add it to enable numa-aware plugin arguments: weight: 10 # the weight of the NUMA Aware Plugin
Example of NUMA Affinity Scheduling
The following describes how to choose NUMA nodes for scheduling pods according to pod scheduling policies. For details, see Pod Scheduling Process.
- single-numa-node: When pods are scheduled, nodes in the node pool with the single-numa-node topology management policy will be chosen, and a single NUMA node must provide the CPU cores. If none of the nodes in the pool meet these requirements, the pod cannot be scheduled.
- restricted: When pods are scheduled, nodes in the node pool with the restricted topology management policy will be chosen, and a set of NUMA nodes on the same node must provide the CPU cores. If none of the nodes in the pool meet these requirements, the pod cannot be scheduled.
- best-effort: When pods are scheduled, nodes in the node pool with the best-effort topology management policy will be chosen, and a single NUMA node needs to provide the CPU cores. If none of the nodes in the pool meet these requirements, the pod will be scheduled to the most suitable node.
- Refer to the following examples for configuration.
- Example 1: Configure NUMA affinity for a Deployment.
kind: Deployment apiVersion: apps/v1 metadata: name: numa-tset spec: replicas: 1 selector: matchLabels: app: numa-tset template: metadata: labels: app: numa-tset annotations: volcano.sh/numa-topology-policy: single-numa-node # Configure the topology policy. spec: containers: - name: container-1 image: nginx:alpine resources: requests: cpu: 2 # The value must be an integer and must be the same as that in limits. memory: 2048Mi limits: cpu: 2 # The value must be an integer and must be the same as that in requests. memory: 2048Mi imagePullSecrets: - name: default-secret - Example 2: Create a Volcano job and enable NUMA affinity for it.
apiVersion: batch.volcano.sh/v1alpha1 kind: Job metadata: name: vj-test spec: schedulerName: volcano minAvailable: 1 tasks: - replicas: 1 name: "test" topologyPolicy: best-effort # set the topology policy for task template: spec: containers: - image: alpine command: ["/bin/sh", "-c", "sleep 1000"] imagePullPolicy: IfNotPresent name: running resources: limits: cpu: 20 memory: "100Mi" restartPolicy: OnFailure
- Example 1: Configure NUMA affinity for a Deployment.
- Analyze NUMA scheduling.
The following table shows example NUMA nodes.
Worker Node
Topology Manager Policy
Allocatable CPU Cores on NUMA Node 0
Allocatable CPU Cores on NUMA Node 1
Node 1
single-numa-node
16
16
Node 2
best-effort
16
16
Node 3
best-effort
20
20
In the preceding examples,
- In example 1, 2 CPU cores are requested by a pod, and the single-numa-node topology policy is used. Therefore, the pod will be scheduled to node 1 with the same policy.
- In example 2, 20 CPU cores are requested by a pod, and the best-effort topology policy is used. The pod will be scheduled to node 3 because it can allocate all the requested 20 CPU cores onto one NUMA node, while node 2 can do so on two NUMA nodes.
Checking NUMA Node Usage
Run the lscpu command to check the CPU usage of the current node.
# Check the CPU usage of the current node. lscpu ... CPU(s): 32 NUMA node(s): 2 NUMA node0 CPU(s): 0-15 NUMA node1 CPU(s): 16-31
Then, check the NUMA node usage.
# Check the CPU allocation of the current node.
cat /var/lib/kubelet/cpu_manager_state
{"policyName":"static","defaultCpuSet":"0,10-15,25-31","entries":{"777870b5-c64f-42f5-9296-688b9dc212ba":{"container-1":"16-24"},"fb15e10a-b6a5-4aaa-8fcd-76c1aa64e6fd":{"container-1":"1-9"}},"checksum":318470969}
The preceding example shows that two containers are running on the node. One container uses CPU cores 1 to 9 of NUMA node 0, and the other container uses CPU cores 16 to 24 of NUMA node 1.
Common Issues
Schedule pods failed.
If Volcano is set as the scheduler and only NUMA is enabled without configuring CPU management during pod scheduling, job scheduling may fail. To fix this issue, do as follows:
- Before using NUMA affinity scheduling, make sure that Volcano has been deployed and is running properly.
- When using NUMA affinity scheduling:
- Set the CPU management policy (cpu-manager-policy) of the node pool to static.
- Correctly configure the topology management policy (topology-manager-policy) in the node pool.
- Configure a correct topology policy for pods to filter nodes with the same topology policy in the node pool. For details, see Example of NUMA Affinity Scheduling.
- Configure the Volcano scheduler to schedule application pods. For details, see Scheduling Workloads. Make sure that the CPU requests for all containers within the pods are integers (measured in cores) and that the requests and limits are identical.
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



