
Interconnecting FlinkServer with Elasticsearch
Scenario
This section introduces how interconnect FlinkServer with Elasticsearch of a cluster by writing Flink SQL queries. Flink 1.12.2 or later versions and Elasticsearch 7.10.2 or later versions are supported.
- Flink clusters in security mode can interconnect with Elasticsearch clusters in both security and normal modes.

To connect a Flink cluster in security mode to an Elasticsearch cluster in non-security mode, set the following parameters:
- Log in to FusionInsight Manager and choose Cluster > Services > Flink. Click Configurations then All Configurations, search for the es.security.indication parameter, and set this parameter to false for the FlinkResource and FlinkServer roles.
- On the Dashboard page, choose More > Restart Service to restart Flink.
- Flink clusters in normal mode can only interconnect with Elasticsearch clusters in normal mode.
In this example, both FlinkServer and Elasticsearch are in security mode.
Prerequisites
- Flink, YARN, ZooKeeper, HDFS, Kafka, and Elasticsearch have been installed in the cluster.
- You have created a user with FlinkServer Admin Privilege (for example, flink_admin) for accessing the Flink web UI by referring to Creating a FlinkServer Role, and have manually added the user to the Elasticsearch user group. If you have interconnected FlinkServer with Elasticsearch of another cluster, ensure that the clusters are mutually trusted, create a user with the same name in the cluster to be connected, and add Elasticsearch permissions to the user on the Ranger web UI. For details about how to add the permissions, see Adding a Ranger Access Permission Policy for Elasticsearch.
- Ensure that the alarm "Elasticsearch Service Has Indexes in the Red State" is not reported in the cluster where Elasticsearch is deployed.
Procedure
- Log in to Manager as user flink_admin and choose Cluster > Services > Flink. In the Basic Information area, click the link next to Flink WebUI to access the Flink web UI.
- Create a Flink SQL job by referring to Creating a Job. On the job development page, configure the job parameters and start the job.
In Basic Parameter, select Enable CheckPoint, set Time Interval(ms) to 60000, and retain the default value for Mode.
-- Creating a KafkaSource table CREATE TABLE kafka(uuid STRING, name STRING, age INT) WITH ( 'connector' = 'kafka', 'topic' = 'kafka2ES', 'properties.bootstrap.servers' = 'IP address of the Kafka broker instance:Kafka port number', 'properties.group.id' = 'testgroup2', 'scan.startup.mode' = 'latest-offset', 'format' = 'csv', 'properties.sasl.kerberos.service.name' = 'kafka', 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.kerberos.domain.name' = 'hadoop.System domain name' ); -- Creating an ESSink table CREATE TABLE es (uuid STRING, name STRING, age INT, PRIMARY KEY (uuid) NOT ENFORCED ) WITH ( 'connector' = 'elasticsearch-7', 'hosts' = 'https://10.10.10.10:24100;https://10.10.10.11:24100', 'index' = 'test_index', 'sink.bulk-flush.max-actions' = '1' ); -- Writing Kafka data to Elasticsearch insert into es select * from kafka;

- The IP address and port number of the Kafka broker instance are as follows:
- To obtain the instance IP address, log in to FusionInsight Manager, choose Cluster > Services > Kafka, click Instance, and query the instance IP address on the instance list page.
- If Kerberos authentication is enabled for the cluster (the cluster is in security mode), the Broker port number is the value of sasl.port. The default value is 21007.
- If Kerberos authentication is disabled for the cluster (the cluster is in normal mode), the broker port number is the value of port. The default value is 9092. If the port number is set to 9092, set allow.everyone.if.no.acl.found to true. The procedure is as follows:
Log in to FusionInsight Manager and choose Cluster > Services > Kafka. Click Configurations then All Configurations. On the page that is displayed, search for allow.everyone.if.no.acl.found, set it to true, and click Save.
- System domain name: You can log in to FusionInsight Manager, choose System > Permission > Domain and Mutual Trust, and check the value of Local Domain.
- 10.10.10.10: service IP address of an EsNode instance in the Elasticsearch cluster. log in to FusionInsight Manager and choose Cluster > Services > Elasticsearch. On the page that is displayed, click Instance and view the service IP addresses of all EsNode instances in the Elasticsearch cluster.
- 24100: Default port number of the Elasticsearch cluster. To view the port number, log in to FusionInsight Manager, choose Cluster > Services > Elasticsearch , and click the Configurations tab then the All Configurations sub-tab. On the page that is displayed, search for SERVER_PORT.
- The IP address and port number of the Kafka broker instance are as follows:
- On the job management page, check whether the job is in the Running status.
- Run the following commands to view the topic and write data to Kafka by referring to Managing Messages in Kafka Topics:
./kafka-topics.sh --list --zookeeper Service IP address of the ZooKeeper quorumpeer instance:Port number of the ZooKeeper client/kafka
sh kafka-console-producer.sh --broker-list IP address of the node where Kafka instances reside:Kafka port number --topic Topic name --producer.config Client directory/Kafka/kafka/config/producer.properties
In this example, the topic name is kafka2ES.
sh kafka-console-producer.sh --broker-list IP address of the node where the Kafka instance is located:Kafka port number --topic kafka2ES --producer.config /opt/client/Kafka/kafka/config/producer.properties
Enter the message content.
3,zhangsan,18 4,wangwu,19 8,zhaosi,20
Press Enter to send the message.
- Service IP address of the ZooKeeper quorumpeer instance:
To obtain the service IP address, log in to FusionInsight Manager and choose Cluster > Services > ZooKeeper. On the page that is displayed, click the Instance tab. On this tab page, view the IP addresses of all the hosts where quorumpeer instances reside.
- Service IP address of the ZooKeeper quorumpeer instance:
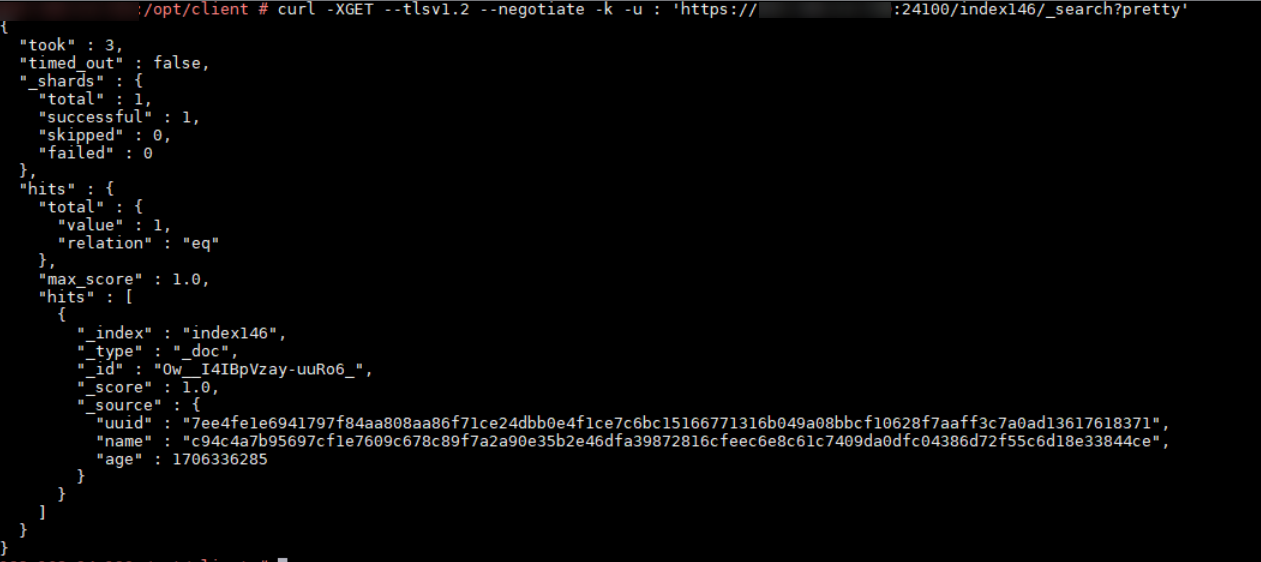
- Run the curl command to obtain the written data by referring to Running curl Commands in Linux. If the data output is normal, FlinkServer is connected to Elasticsearch.
Example: curl -XGET --tlsv1.2 --negotiate -k -u : 'https://10.10.10.10:24100/test_index/_search?pretty'
WITH Parameters
|
Parameter |
Mandatory |
Type |
Description |
|---|---|---|---|
|
connector |
Yes |
String |
Connector to which FlinkServer connects, for example, elasticsearch-7, which means FlinkServer connects to an Elasticsearch 7.x or later cluster. |
|
hosts |
Yes |
String |
IP addresses of one or multiple Elasticsearch hosts to be connected. Example: 'http://10.10.10.10:24100;http://10.10.10.10:24100' |
|
index |
Yes |
String |
Index of each record in Elasticsearch. The index can be a static one (for example, 'myIndex') or a dynamic one (for example, 'index-{log_ts|yyyy-MM-dd}'). |
|
document-id.key-delimiter |
No |
String |
Delimiter of a composite key. The default value is _. If this parameter is set to $, the document ID is KEY1$KEY2$KEY3. |
|
username |
No |
String |
Username for connecting to the Elasticsearch instance. |
|
password |
No |
String |
Password for connecting to the Elasticsearch instance. This parameter must be a non-null string if username is set. |
|
failure-handler |
No |
String |
Policy for handling Elasticsearch request failures. Value options are as follows:
|
|
sink.flush-on-checkpoint |
No |
Boolean |
|
|
sink.bulk-flush.max-actions |
No |
Integer |
Maximum number of buffer operations for each batch request. The default value is 1000. You can set this parameter to 0 to disable this function. |
|
sink.bulk-flush.max-size |
No |
MemorySize |
Maximum size of the buffer operation for each batch request in the memory. The default value is 2 MB. The unit must be MB. You can set this parameter to 0 to disable this function. |
|
sink.bulk-flush.interval |
No |
Duration |
Interval for buffer operations. The default value is 1 s. You can set this parameter to 0 to disable this function. |
|
sink.bulk-flush.backoff.strategy |
No |
String |
Specifies how to perform a retry if any flush operations fail due to a temporary request error. Value options are as follows:
|
|
sink.bulk-flush.backoff.max-retries |
No |
Integer |
Maximum number of rollback retries |
|
sink.bulk-flush.backoff.delay |
No |
Duration |
Delay between backoff retries. Value options are as follows:
|
|
connection.path-prefix |
No |
String |
Prefix string added to each REST communication, for example, '/v1'. |
|
format |
No |
String |
Format supported by the Elasticsearch connector. The default value is json. |
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



