
Step 2: Integrate Data
Migrating Data from OBS to DWS
- Log in to the CDM console and choose Cluster Management in the left navigation pane.
Log in to the DataArts Studio console by following the instructions in . On the DataArts Studio console, locate a workspace and click DataArts Migration to access the CDM console.
Figure 1 Cluster list

The Source column is displayed only when you access the DataArts Migration page from the DataArts Studio console.
- On the displayed Cluster Management page, click Job Management in the Operation column. Figure 2 Job Management

- Click the Links tab and then Create Link.
- On the Create Link page, select Object Storage Service (OBS) and click Next to create a link named obs_link from CDM to OBS.
Table 1 Parameter description Parameter
Description
Example Value
Name
Link name, which should be defined based on the data source type, so it is easier to remember what the link is for
obs_link
OBS Endpoint
An endpoint is the request address for calling an API. Endpoints vary depending on services and regions. You can obtain the OBS bucket endpoint by either of the following means:
To obtain the endpoint of an OBS bucket, go to the OBS console and click the bucket name to go to its details page.
NOTE:- If the CDM cluster and OBS bucket are not in the same region, the CDM cluster cannot access the OBS bucket.
- Do not change the password or user when the job is running. If you do so, the password will not take effect immediately and the job will fail.
obs.myregion.mycloud.com
Port
Data transmission port. The HTTPS port number is 443 and the HTTP port number is 80.
443
OBS Bucket Type
Select a value from the drop-down list, generally, Object Storage.
Object Storage
AK
AK and SK are used to log in to the OBS server.
You need to create an access key for the current account and obtain an AK/SK pair.
To obtain an access key, perform the following steps:- Log in to the management console, move the cursor to the username in the upper right corner, and select My Credentials from the drop-down list.
- On the My Credentials page, choose Access Keys, and click Create Access Key. See Figure 3.
- Click OK and save the access key file as prompted. The access key file will be saved to your browser's configured download location. Open the credentials.csv file to view Access Key Id and Secret Access Key. NOTE:
- Only two access keys can be added for each user.
- To ensure access key security, the access key is automatically downloaded only when it is generated for the first time and cannot be obtained from the management console later. Keep them properly.
-
SK
-
Link Attributes
(Optional) Displayed when you click Show Advanced Attributes.
You can click Add to add custom attributes for the link.
Only connectionTimeout, socketTimeout, and idleConnectionTime are supported.
The following are some examples:
- socketTimeout: timeout interval for data transmission at the socket layer, in milliseconds
- connectionTimeout: timeout interval for establishing an HTTP/HTTPS connection, in milliseconds
-
Figure 4 Creating an OBS link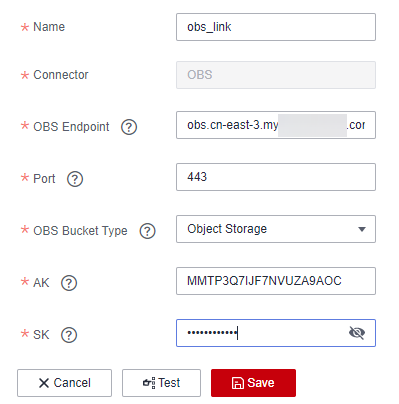
- On the Create Link page, select Data Warehouse Service and click Next to create a link named dws_link from CDM to DWS.
Table 2 DWS link parameters Parameter
Description
Example Value
Name
Link name, which should be defined based on the data source type, so it is easier to remember what the link is for
dws_link
Database Server
Click Select next to the text box to obtain the list of DWS instances.
-
Port
Port of the target database. The DWS database port is 8000 by default.
8000
Database Name
Name of the target database
demo
Username
Username used for accessing the database. This account must have the permissions to read and write data tables and metadata.
dbadmin
Password
User password
-
Use Agent
Whether to extract data from the data source through an agent
No
Figure 5 Creating a DWS link
- After the links are created, click the Table/File Migration tab and then Create Job. Figure 6 Creating a job

- Perform the following steps to configure job parameters:
- As shown in Figure 7, enter movies_obs2dws for Job Name and configure the source job and destination job parameters.
In this example, Yes is selected for Clear Data Before Import, indicating that data is cleared before data import each time the job is executed. Exercise caution when setting this parameter to avoid data loss.
- In the Source Job Configuration and Destination Job Configuration areas, click Show Advanced Attributes. In the Advanced Attributes area, default values are provided. Set the parameters based on the actual data format. In this example, pay attention to the following parameters in the advanced attributes of the source job and retain the default values for other parameters. You do not need to configure the advanced attributes of the destination job.
- Field Delimiter: Retain the default value, which is a comma (,).
- Use Quote Char: Select Yes because some original IMDbURL data contains commas (,).
- First N Rows As Header: The default value is No. In this section, set this parameter to Yes and set The Number of Header Rows to 1.
Figure 8 Source job advanced attributes
- Click Next, configure field mapping, and click Next.
Map Field: In this example, you do not need to adjust the field mapping because the sequence of the source fields is the same as that of the destination fields.
If they are different, you need to map the source fields with the destination fields by meaning. To map a field with another, move the cursor to the arrow start point of the source field. When + is displayed, hold down the mouse left button, move the cursor to the field with the same meaning as the source field, and release the mouse button.
Figure 9 Field mapping
- Configure Retry upon Failure , Schedule Execution, and advanced attributes. In this example, set Write Dirty Data to Yes and retain the default values for other parameters.
Click Show Advanced Attributes and set Concurrent Extractors and Write Dirty Data.
- Concurrent Extractors: Enter the number of extractors to be concurrently executed. The value range is 1 to 1000. If the value is too large, the extractors are queued. The number of concurrent extractors in a CDM migration job is related to the cluster specifications and table size.
- You are advised to set this parameter to 4 for each CU (1 CPU and 4 GB) based on the cluster specifications.
- If each row of the table contains less than or equal to 1 MB data, you can extract data concurrently. If each row contains more than 1 MB data, you are advised to extract data in a single thread.
- Write Dirty Data: You are advised to set this parameter to Yes and set related parameters by referring to Figure 10. Dirty data refers to the data that does not match the destination fields and can be saved in a specified OBS bucket. If you select Yes, normal data can be written to the destination end, and the migration job will not be interrupted by the dirty data.
In this example, set OBS Bucket to fast-demo created in Preparing Data Sources. Go to the OBS console, create a directory, for example, err_data, in the bucket, and set Dirty Data Directory to this directory.
- Concurrent Extractors: Enter the number of extractors to be concurrently executed. The value range is 1 to 1000. If the value is too large, the extractors are queued.
- As shown in Figure 7, enter movies_obs2dws for Job Name and configure the source job and destination job parameters.
- Click Save and Run.
On the Table/File Migration page, you can view the created job.
Figure 11 Execution result of the migration job
- Repeat Step 6 to Step 8 to create another migration job named ratings_obs2dws for migrating data in the ratings.csv file to the ratings_item table of DWS. After the job is successfully executed, the data migration is complete. Figure 12 Data migration result

- After the data migration is complete, you can go to the DataArts Factory page, create a DWS SQL script, and run the following SQL statements to check whether the data in the movies_item and ratings_item tables meets expectations:
- Check the data in the movies_item table.
SET SEARCH_PATH TO dgc; SELECT * FROM movies_item;
- Check the data in the ratings_item table.
SET SEARCH_PATH TO dgc; SELECT * FROM ratings_item;
Figure 13 Viewing data in DWS tables
- Check the data in the movies_item table.



Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.




