
Help Center/
ModelArts/
ModelArts User Guide (Standard)/
History/
Inference Deployment(To go offline)/
Overview
Updated on 2025-09-08 GMT+08:00
Overview
You can import and deploy AI models as inference services. These services can be integrated into your IT platform by calling APIs or generate batch results.
Figure 1 Introduction to inference

- Train a model: Models can be trained in ModelArts or your local development environment. A locally developed model must be uploaded to OBS.
- Create a model: Import the model file and inference file to the ModelArts model repository and manage them by version. Use these files to build an executable model.
- Deploy a service: Deploy the model as a service type based on your needs.
- Deploying a Model as Real-Time Inference Jobs
Deploy a model as a web service with real-time UI and monitoring. This service provides you a callable API.
- Deploying a Model as a Batch Inference Service
Deploy an AI application as a batch service that performs inference on batch data and automatically stops after data processing is complete.
Figure 2 Different inference scenarios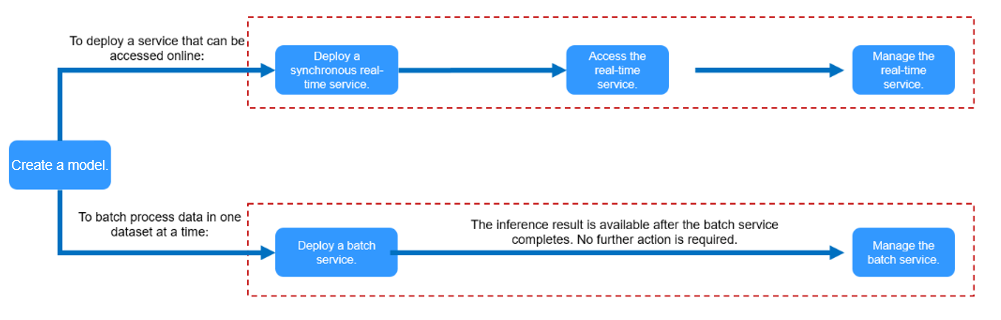
- Deploying a Model as Real-Time Inference Jobs
Parent topic: Inference Deployment(To go offline)
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.
The system is busy. Please try again later.




