
Interconnecting Sqoop with OBS Using an IAM Agency
After connecting the Sqoop client to an OBS file system by referring to Interconnecting an MRS Cluster with OBS Using an IAM Agency, you can import tables from a relational database to OBS or export tables from OBS to a relational database on the Sqoop client.
Prerequisites
You need to download the MySQL driver package of the required version from the MySQL official website https://downloads.mysql.com/archives/c-j/, decompress the package, and upload it to the Client installation directory/Sqoop/sqoop/lib directory on the node where the Sqoop client is installed.
Exporting Sqoop Table Data to MySQL by Running sqoop export
- Log in to the node where the client is installed.
- Run the following command to initialize environment variables:
source /opt/client/bigdata_env
- Run the following command to perform operations on the Sqoop client:
sqoop export --connect jdbc:mysql://10.100.xxx.xxx:3306/test --username root --password xxx --table component13 -export-dir hdfs://hacluster/user/hive/warehouse/component_test3 --fields-terminated-by ',' -m 1
Table 1 Parameter descriptions Parameter
Description
--connect
URL used to connect to JDBC, in the format of jdbc:mysql://IP address of the MySQL database:MySQL port/Database name.
--username
Username used to log in to the MySQL database.
-password
Password used to log in to the MySQL database. To avoid potential security risks, disable history command recording before executing a command that contains authentication password information.
-table <table-name>
Name of the MySQL table used to store exported data.
-export-dir <dir>
HDFS path where the Sqoop table to be exported is located.
--fields-terminated-by
Delimiter of the data to be exported, which must be the same as that in the HDFS data table to be exported.
-m or -num-mappers <n>
n (4 by default) maps are started to import data concurrently. Make sure that this value is not greater than the maximum number of maps in a cluster.
-direct
A fast mode for importing data into a relational database using a tool like MySQL's mysqlimport, which is faster than using a JDBC connection.
-update-key <col-name>
Followed by a condition column name. You can use this parameter to update the existing data in a relational database.
-update-mode <mode>
How data is updated. The options are updateonly and allowinsert. It can only be used when the record to be imported does not exist in the relational data table. For example, if there is a record with id=1 in the HDFS data to be imported and there is already a record with id=2 in the table, the update will fail.
-input-null-string <null-string>
(Optional) If unset, null will be used.
-input-null-non-string <null-string>
(Optional) If unset, null will be used.
-staging-table <staging-table-name>
This parameter creates a table with the same data structure as the target table, stores all data in it, and then writes the results to the target table through a single transaction.
The parameter ensures transaction security during the process of importing data into a relational database table. Multiple transactions may occur during the import process, and if one transaction fails, it can affect other transactions, resulting in errors or duplicate records in the imported data. This parameter helps to avoid such situations.
-clear-staging-table
This parameter allows you to clear the data in the staging table before running the import process if it is not empty.
Importing MySQL Data to a Hive Table by Running sqoop import
- Log in to the node where the client is installed.
- Run the following command to initialize environment variables:
source /opt/client/bigdata_env
- Run the following command to perform operations on the Sqoop client:
sqoop import --connect jdbc:mysql://10.100.xxx.xxx:3306/test --username root --password xxx --table component --hive-import --hive-table component_test2 --delete-target-dir --fields-terminated-by "," -m 1 --as-textfile
Table 2 Parameter descriptions Parameter
Description
--hive-import
Imports data from a relational database to MRS Hive.
--delete-target-dir
Deletes the existing target file (if any) from Hive and reimports the file.
-append
Appends data to an existing dataset in HDFS. Once used, Sqoop imports data to file in a temporary directory, renames the file, and moves the file to a formal directory. This helps avoid duplicate file names in the directory.
-as-avrodatafile
Imports data to an Avro file.
-as-sequencefile
Imports data to a sequence file.
-as-textfile
Imports data to a text file. Once the file is created, you can query data in Hive by running SQL statements.
-boundary-query <statement>
SQL statement used to query boundaries. Before importing data, run this SQL statement to obtain a result set. Then import the data in the result set. The statement is like -boundary-query 'select id,creationdate from person where id = 3' (importing the record id=3) or select min(<split-by>), max(<split-by>) from <table name>.
If a field's value in the SQL statement is a string, the error message "java.sql.SQLException: Invalid value for getLong()" is displayed.
-columns<col,col,col...>
Fields to be imported, in the format of -columns id,username.
-direct
A fast mode for importing data into a relational database using a tool like MySQL's mysqlimport, which is faster than using a JDBC connection.
-direct-split-size
Splits imported data streams into byte-sized chunks, especially when importing data from PostgreSQL using a direct connection. It can split a file that reaches a set size into several independent files.
-inline-lob-limit
Maximum value of an inline LOB.
-m or -num-mappers
n (4 by default) maps are started to import data concurrently. Make sure that this value is not greater than the maximum number of maps in a cluster.
-query, -e<statement>
Imports data from query results. -target-dir and -hive-table must be specified. When using this parameter, the query statement must include a WHERE clause that contains $CONDITIONS. The following is an example:
-query 'select * from person where $CONDITIONS ' -target-dir /user/hive/warehouse/person -hive-table person
-split-by<column-name>
Column name of a table, which is used to split work units and is generally followed by a primary key ID.
-table <table-name>
Name of the relational database table from which data is obtained.
-target-dir <dir>
HDFS path.
-warehouse-dir <dir>
Directory used to store data to be imported, which must not be used together with -target-dir. It is applicable when data is imported to HDFS but not Hive directories.
-where
WHERE clause when data is imported from a relational database, for example, -where 'id = 2'.
-z,-compress
Compresses sequence, text, and Avro data files using the GZIP compression algorithm. Data is not compressed by default.
-compression-codec
Hadoop compression codec, with GZIP used by default.
-null-string <null-string>
String to be interpreted as null for string columns. If not set, NULL will be used.
-null-non-string<null-string>
String to be interpreted as null for non-string columns. If not set, NULL will be used.
-check-column (col)
Column for checking incremental data import, for example, id.
-incremental (mode) append
or lastmodified
Incrementally imports data.
append: appends records, for example, appending records that are greater than the value specified by last-value.
lastmodified: appends data that is modified after the date specified by last-value.
-last-value (value)
Maximum value (greater than the specified value) of the column after the last import, which can be set as needed.
Example Sqoop Usage
- Importing MySQL data to HDFS by running sqoop import
sqoop import --connect jdbc:mysql://10.100.231.134:3306/test --username root --password xxx --query 'SELECT * FROM component where $CONDITIONS and component_id ="MRS 1.0_002"' --target-dir /tmp/component_test --delete-target-dir --fields-terminated-by "," -m 1 --as-textfile
- Exporting OBS data to MySQL by running sqoop export
sqoop export --connect jdbc:mysql://10.100.231.134:3306/test --username root --password xxx --table component14 -export-dir obs://obs-file-bucket/xx/part-m-00000 --fields-terminated-by ',' -m 1
- Importing MySQL data to OBS by running sqoop import
sqoop import --connect jdbc:mysql://10.100.231.134:3306/test --username root --password xxx --table component --target-dir obs://obs-file-bucket/xx --delete-target-dir --fields-terminated-by "," -m 1 --as-textfile
- Importing MySQL data to a Hive foreign table stored on OBS by running sqoop import
sqoop import --connect jdbc:mysql://10.100.231.134:3306/test --username root --password xxx --table component --hive-import --hive-table component_test01 --fields-terminated-by "," -m 1 --as-textfile
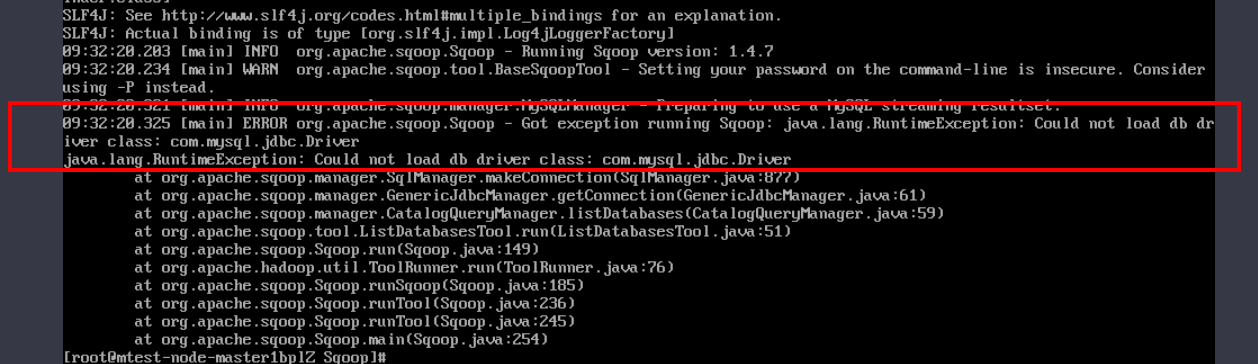
Missing MySQL Driver Package When Importing or Exporting Data
If the error message "Could not load db driver class: com.mysql.jdbc.Driver" is displayed when the sqoop import or sqoop export command is executed, as shown in Figure 1, the MySQL driver package is missing. To address this issue, download the MySQL driver package from the MySQL official website (https://downloads.mysql.com/archives/c-j/), decompress it, upload it to the Client installation directory/Sqoop/sqoop/lib directory, and run sqoop import or sqoop export to import or export data.
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.




