
Interconnecting Hudi with OBS Using an IAM Agency
After configuring decoupled storage and compute for a cluster by referring to Interconnecting an MRS Cluster with OBS Using an IAM Agency, you can create Hudi COW tables in spark-shell and store them to OBS.
Interconnecting Hudi with OBS
- Log in to the client installation node as the client installation user.
- Run the following commands to configure environment variables:
source Client installation directory/bigdata_env
source Client installation directory/Hudi/component_env
- Modify the configuration file:
vim Client installation directory/Hudi/hudi/conf/hdfs-site.xml
<property> <name>dfs.namenode.acls.enabled</name> <value>false</value> </property>
- For a security cluster, run the following command to perform user authentication. If Kerberos authentication is not enabled for the current cluster, you do not need to run this command.
kinit Username
- Start spark-shell and run the following commands to create a COW table and save it in OBS:
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val tableName = "hudi_cow_table"
val basePath = "obs://testhudi/cow_table/"
val dataGen = new DataGenerator
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
df.write.format("org.apache.hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Overwrite).
save(basePath);
"obs://testhudi/cow_table/" is the OBS path, and testhudi is the name of the parallel file system. Change them based on site requirements.
- Use DataSource to check whether the table is created and whether the data is normal.
val roViewDF = spark.
read.
format("org.apache.hudi").
load(basePath + "/*/*/*/*")
roViewDF.createOrReplaceTempView("hudi_ro_table")
spark.sql("select * from hudi_ro_table").show()
Figure 1 Viewing table data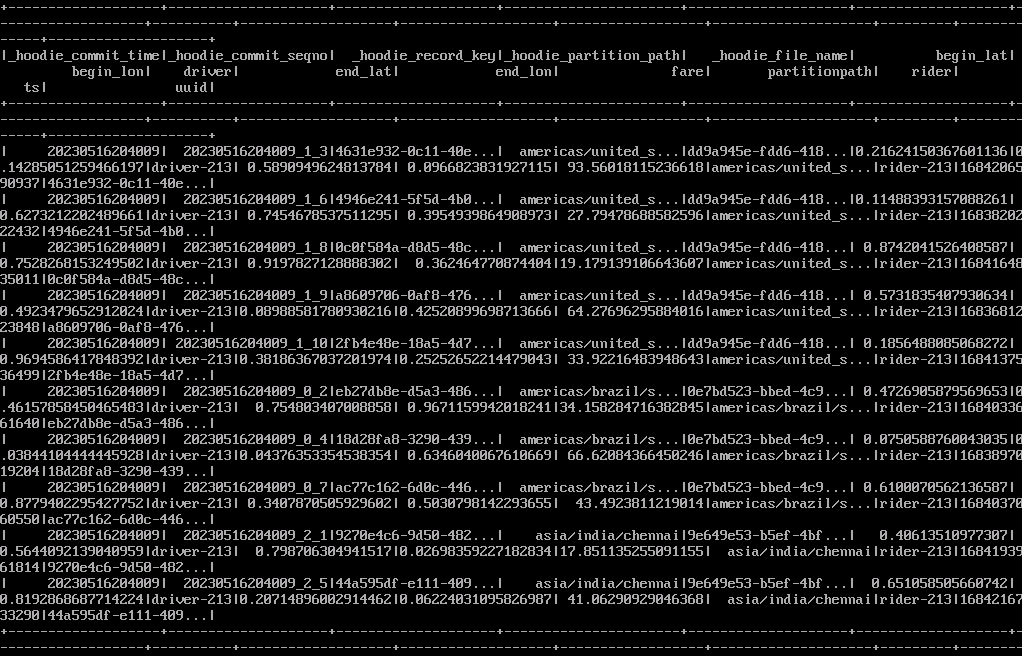
- Run :q to exit the spark-shell CLI.
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.




