
Deploying and Using Real-Time Inference
After creating a model, you can deploy it as a real-time service. If a real-time service is in the Running status, it has been deployed. This service provides a standard, callable RESTful API. When accessing a real-time service, you can choose the authentication method, access channel, and transmission protocol that best suit your needs. These three elements make up your access requests and can be mixed and matched without any interference. For example, you can use different authentication methods for different access channels and transmission protocols.
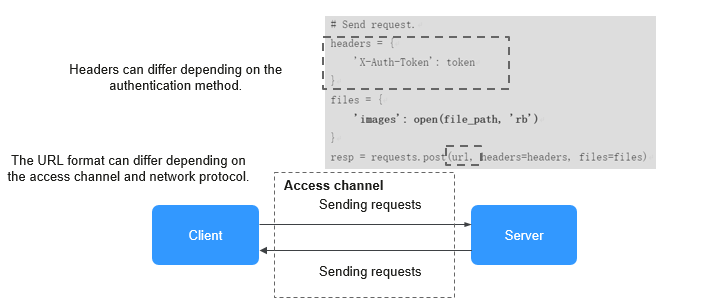
ModelArts supports the following authentication methods for accessing real-time services (HTTPS requests are used as examples):
- Token-based authentication: The validity period of a token is 24 hours. When using a token for authentication, cache it to prevent frequent calls.
ModelArts allows you to call APIs to access real-time services in the following ways (HTTPS requests are used as examples):
- Accessing a Real-Time Service Through a Public Network: By default, ModelArts inference uses the public network to access real-time services. A standard, callable RESTful API is provided after deployment of a real-time service.
- Accessing a Real-Time Service Through a VPC High-Speed Channel: When using VPC peering for high-speed access, your service requests are sent directly to instances via VPC peering, bypassing the inference platform. This results in faster service access.
Real-time service APIs are accessed using HTTPS by default. Additionally, the following transmission protocols are also supported:
- Accessing a Real-Time Service Using Server-Sent Events: Server-Sent Events (SSE) primarily facilitates unidirectional real-time communication from the server to the client, such as streaming ChatGPT responses. In contrast to WebSockets, which provide bidirectional real-time communication, SSE is designed to be more lightweight and simpler to implement.
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.




