
Incremental Model Training
What Is Incremental Training?
Incremental learning is a machine learning method that enables AI models to learn from new data without restarting the training process. It builds on existing knowledge, allowing the model to expand its capabilities and improve its performance over time.
Incremental learning allows for training on data in smaller chunks, reducing storage needs and alleviating resource constraints. It also conserves computing power and time, and lowers retraining costs.
Incremental training is ideal for these scenarios:
- Continuous data updates: It allows models to adapt to new data without retraining.
- Resource constraints: It is a more economical choice when retraining a model is too costly.
- Avoiding knowledge loss: It retains old knowledge while learning new information, preventing the model from forgetting what it has learned.
Incremental training is used in various fields, including natural language processing, computer vision, and recommendation systems. It makes AI systems more flexible and adaptable, allowing them to handle changing data in real-world environments.
Implementing Incremental Training in ModelArts Standard
The checkpoint mechanism enables incremental training.
During model training, training results (including but not limited to epochs, model weights, optimizer status, and scheduler status) are continuously saved. To add data and resume a training job, load a checkpoint and use the checkpoint information to initialize the training status. To do so, add reload ckpt to the code.
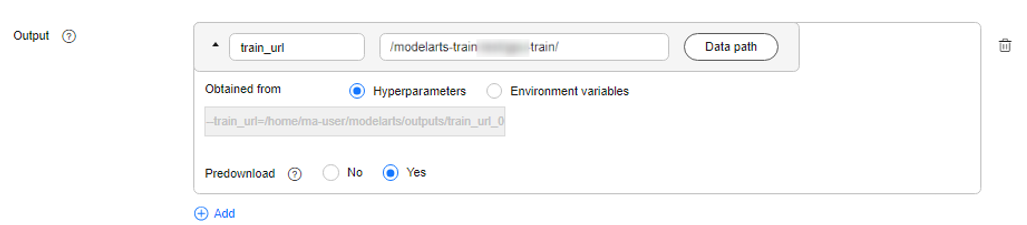
To incrementally train a model in ModelArts, configure the training output.
When creating a training job, set the data path to the training output, save checkpoints in this data path, and set Predownload to Yes. If you set Predownload to Yes, the system automatically downloads the checkpoint file in the training output data path to a local directory of the training container before the training job is started.
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.




