
Help Center/ DataArts Studio/ Best Practices/ Simplified Migration of Trade Data to the Cloud and Analysis/ Using CDM to Upload Data to OBS/ Uploading Inventory Data
Updated on 2025-08-05 GMT+08:00
Uploading Inventory Data
- Use Direct Connect to establish a Direct Connect connection between the local data center and Huawei Cloud Virtual Private Cloud (VPC).
- Create an OBS bucket and record the access domain name, port number, access key ID (AK), and secret access key (SK) of the OBS bucket.
- Create a CDM cluster.
If a DataArts Studio instance includes a CDM cluster (except the trial version) and the cluster meets your requirements, you do not need to buy a DataArts Migration incremental package.
If you need to create another CDM cluster, buy a CDM incremental package by referring to Buying a CDM Incremental Package.
- Instance Type: Select cdm.xlarge, which applies to most migration scenarios.
- VPC: VPC of the CDM cluster. Select the VPC that connects to the local data center through Direct Connect.
- (Optional) Subnet and Security Group: You can configure either of them.
- After the cluster is created, choose . The page for selecting a link type is displayed. See Figure 1.
- To connect to the local Apache HDFS of company H, select Apache HDFS, and click Next. Figure 2 Creating an HDFS link

- Name: Enter a custom link name, for example, hdfs_link.
- URI: Enter the NameNode URI of HDFS of company H.
- Authentication Method: Select KERBEROS if Hadoop is in security mode to obtain the principal and keytab files from the client for authentication.
- Principal and Keytab File: Obtain the principal account and keytab file from the Hadoop administrator.
- Click Save. CDM automatically checks whether the link is available.
- If the link is available, a message is displayed, indicating that the link is successfully saved, and the link management page is displayed.
- If the link is unavailable, check whether the link parameters are correctly configured or whether the firewall of company H allows the elastic IP address (EIP) of the CDM cluster to access the data source.
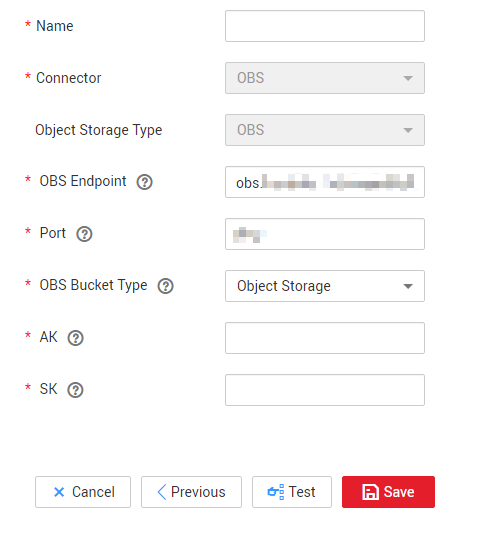
- Click Create Link to create an OBS link. On the page that is displayed, select Object Storage Service (OBS) and click Next. Set the OBS link parameters as required. See Figure 3.
- Name: Enter a custom link name, for example, obslink.
- OBS Endpoint: Enter the domain name or IP address of OBS, for example, obs.myhuaweicloud.com.
- Port: Enter the port number of OBS, for example, 443.
- OBS Bucket Type: Select a value from the drop-down list box as required.
- AK and SK: Enter the AK and SK used for accessing the OBS database. To obtain the AK and SK, log in to the management console, click the username in the upper right corner, and select My Credentials from the drop-down list. On the displayed page, choose Access Keys in the left navigation pane.
- Click Save. The Link Management page is displayed.
- Choose to create a job for migrating trade statistics of company H to OBS. See Figure 4.
- Job Name: Enter a user-defined job name.
- Source Link Configuration:
- Source Link Name: Select the HDFS link hdfs_link created in 5.
- Source Directory/File: Set this parameter to the local storage path of company H's trade statistics. The value can be either a directory or a file. Set this parameter to a directory. CDM migrates all files in the directory to OBS.
- File Format: Select Binary. The file format refers to the format used by CDM to transmit data. The formats of the original files are not changed. Binary is recommended for migration between files because the transmission efficiency and performance are optimal.
- Destination Link Configuration:
- Destination Link Name: Select the OBS link obslink created in 7.
- Bucket Name and Write Directory: Enter the path for storing trade statistics in OBS. CDM writes the files to this path.
- File Format: Select Binary. Similar to the source link, the formats of the original files are not changed.
- Duplicate File Processing Method: Select Skip. CDM determines that a file is a duplicate file only when the file name and file size are the same on the source and destination ends. In this case, CDM skips the file and does not migrate the file to OBS.
- Click Next to go to the tab page for configuring the task parameters. For the migration of inventory data, retain the default values of the parameters.
- Click Save and Run. On the displayed job management page, you can view the job execution progress and result.
- After the job is successfully executed, click Historical Record to view the number of written rows, number of read rows, number of written bytes, number of written files, and execution logs.


Parent topic: Using CDM to Upload Data to OBS
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.
The system is busy. Please try again later.




