
Optimizing the Query Performance of Elasticsearch Clusters
Before using an Elasticsearch cluster in CSS, you are advised to optimize the cluster's query performance to improve efficiency.
Data Query Process
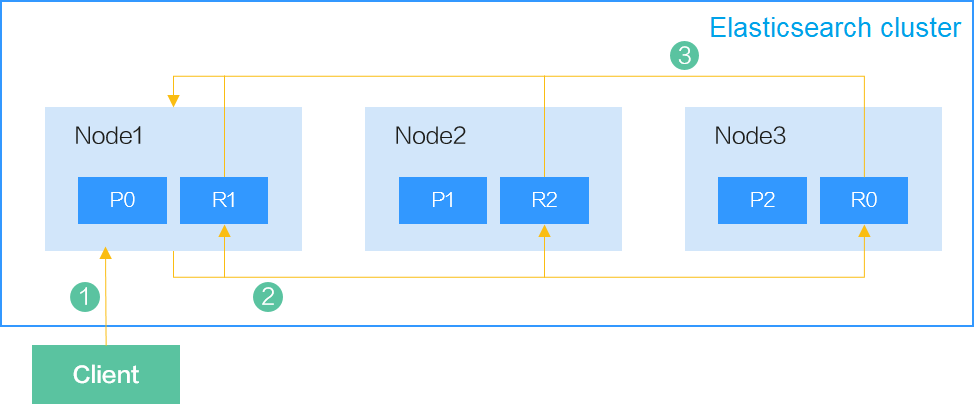
Figure 1 shows how a client sends a query request to an Elasticsearch cluster. In the preceding figure, P indicates the primary shard, and R indicates the replica shard. The primary and replica shards are randomly allocated in data nodes, but cannot be in the same node.
- The client sends a data query request to Node1. Here Node1 is the coordinator node.
- Node1 selects a shard based on the shard distribution and the index specified in the query, and then forwards the request to Node1, Node2, and Node3.
- Each shard executes the query task. After the query succeeds on the shards, the query results are aggregated to Node1, which returns the results to the client.
For a query request, five shards can be queried concurrently on a node by default. If there are more than five shards, the query will be performed in batches. In a single shard, the query is performed by traversing each segment one by one.

Improving Query Performance
The following solutions can be used to improve Elasticsearch's query performance:
| Solution | Description |
|---|---|
| Use _routing to reduce the number of shards scanned during retrieval. | During data import, configure routing to route data to a specific shard instead of all the shards of the related index, improving the overall throughput of the cluster. In Elasticsearch 7.x, run the following commands:
|
| Use index sorting to reduce the number of segments to be scanned. | When a request is processed on a shard, the segments of the shard are traversed one by one. By using index sorting, the range query or sorting query can be terminated in advance (early-terminate). For example, in Elasticsearch 7.x, run the following commands: // Assume the date field needs to be frequently used for range query.
PUT {index}
{
"settings": {
"index": {
"sort.field": "date",
"sort.order": "desc"
}
},
"mappings": {
"properties": {
"date": {
"type": "date"
}
}
}
} |
| Add query cache to improve cache hit. | When a filter request is executed in a segment, the bitset is used to retain the result, which can be reused for later similar queries, thus reducing the overall query workloads. You can add query cache by increasing the value of indices.queries.cache.size. Restart the cluster for the modification to take effect. |
| Perform forcemerge in advance to reduce the number of segments to be scanned. | For read-only indexes that are periodically rolled, you can periodically execute forcemerge to combine small segments into large segments and permanently delete indexes marked as deleted. In Elasticsearch 7.x, a configuration example is as follows: // Assume the number of segments after index forcemerge is set to 10.
POST /{index}/_forcemerge?max_num_segments=10 |
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.




